PART ONE—
TECHNOLOGICAL FUNDAMENTALS
Chapter 1—
Making Technology Work for Scholarship
Investing in the Data
Susan Hockey
The introduction of any kind of new technology is often a painful and timeconsuming process, at least for those who must incorporate it into their everyday lives. This is particularly true of computing technology, where the learning curve can be steep, what is learned changes rapidly, and ever more new and exciting things seem to be perpetually on the horizon. How can the providers and consumers of electronic information make the best use of this new medium and ensure that the information they create and use will outlast the current system on which it is used? In this chapter we examine some of these issues, concentrating on the humanities, where the nature of the information studied by scholars can be almost anything and where the information can be studied for almost any purpose.
Today's computer programs are not sophisticated enough to process raw data sensibly. This situation will remain true until artificial intelligence and natural language processing research has made very much more progress. Early on in my days as a humanities computing specialist, I saw a library catalog that had been typed into the computer without anything to separate the fields in the information. There was no way of knowing what was the author, title, publisher, or call number of any of the items. The catalog could be printed out, but the titles could not be searched at all, nor could the items in the catalog be sorted by author name. Although a human can tell which is the author or title from reading the catalog, a computer program cannot. Something must be inserted in the data to give the program more information. This situation is a very simple example of markup, or encoding, which is needed to make computers work better for us. Since we are so far from having the kind of intelligence we really need in computer programs, we must put that intelligence in the data so that computer programs can be informed by it. The more intelligence there is in our data, the better our programs will perform. But what should that intelligence look like? How can we ensure that we make the right decisions in creating it so that computers can really do what we
want? Some scholarly communication and digital library projects are beginning to provide answers to these questions.
New Technology or Old?
Many current technology and digital library projects use the new technology as an access mechanism to deliver the old technology. These projects rest on the assumption that the typical scholarly product is an article or monograph and that it will be read in a sequential fashion as indeed we have done for hundreds of years, ever since these products began to be produced on paper and be bound into physical artifacts such as books. The difference is that instead of going only to the library or bookstore to obtain the object, we access it over the network-and then almost certainly have to print a copy of it in order to read it. Of course there is a tremendous savings of time for those who have instant access to the network, can find the material they are looking for easily, and have high-speed printers. I want to argue here that delivering the old technology via the new is only a transitory phase and that it must not be viewed as an end in itself. Before we embark on the large-scale compilation of electronic information, we must consider how future scholars might use this information and what are the best ways of ensuring that the information will last beyond the current technology.
The old (print) technology developed into a sophisticated model over a long period of time.[1] Books consist of pages bound up in sequential fashion, delivering the text in a single linear sequence. Page numbers and running heads are used for identification purposes. Books also often include other organizational aids, such as tables of contents and back-of-the-book indexes, which are conventionally placed at the beginning and end of the book respectively. Footnotes, bibliographies, illustrations, and so forth, provide additional methods of cross-referencing. A title page provides a convention for identifying the book and its author and publication details. The length of a book is often determined by publishers' costs or requirements rather than by what the author really wants to say about the subject. Journal articles exhibit similar characteristics, also being designed for reproduction on pieces of paper. Furthermore, the ease of reading printed books and journals is determined by their typography, which is designed to help the reader by reinforcing what the author wants to say. Conventions of typography (headings, italic, bold, etc.) make things stand out on the page.
When we put information into electronic form, we find that we can do many more things with it than we can with a printed book. We can still read it, though not as well as we can read a printed book. The real advantage of the electronic medium is that we can search and manipulate the information in many different ways. We are no longer dependent on the back-of-the-book index to find things within the text, but can search for any word or phrase using retrieval software. We no longer need the whole book to look up one paragraph but can just access the piece of information we need. We can also access several different pieces of infor-
mation at the same time and make links between them. We can find a bibliographic reference and go immediately to the place to which it points. We can merge different representations of the same material into a coherent whole and we can count instances of features within the information. We can thus begin to think of the material we want as "information objects."[2]
To reinforce the arguments I am making here, I call electronic images of printed pages "dead text" and use the term "live text" for searchable representations of text.[3] For dead text we can use only those retrieval tools that were designed for finding printed items, and even then this information must be added as searchable live text, usually in the form of bibliographic references or tables of contents. Of course most of the dead text produced over the past fifteen or so years began its life as live text in the form of word-processed documents. The obvious question is, how can the utility of that live text be retained and not lost forever?
Electronic Text and Data Formats
Long before digital libraries became popular, live electronic text was being created for many different purposes, most often, as we have seen, with word-processing or typesetting programs. Unfortunately this kind of live electronic text is normally searchable only by the word-processing program that produced it and then only in a very simple way. We have all encountered the problems involved in moving from one word-processing program to another. Although some of these problems have been solved in more recent versions of the software, maintaining an electronic document as a word-processing file is not a sensible option for the long term unless the creator of the document is absolutely sure that this document will be needed only in the short-term future and only for the purposes of word processing by the program that created it. Word-processed documents contain typographic markup, or codes, to specify the formatting. If there were no markup, the document would be much more difficult to read. However, typesetting markup is ambiguous and thus cannot be used sensibly by any retrieval program. For example, italics can be used for titles of books, or for emphasized words, or for foreign words. With typographic markup, we cannot distinguish titles of books from foreign words, which we may, at some stage, want to search for separately.
Other electronic texts were created for the purposes of retrieval and analysis. Many such examples exist, ranging from the large text databases of legal statutes to humanities collections such as the Thesaurus Linguae Graecae (TLG) and the Trésor de la langue française. The scholars working on these projects all realized that they needed to put some intelligence into the data in order to search it effectively. Most project staff devised markup schemes that focus on ways of identifying the reference citations for items that have been retrieved; for example, in the TLG, those items would be the name of the author, work, book, and chapter number. Such
markup schemes do not easily provide for representing items of interest within a text, for example, foreign words or quotations. Most of these markup schemes are specific to one or two computer programs, and texts prepared in them are not easily interchangeable. A meeting in 1987 examined the many markup schemes for humanities electronic texts and concluded that the present situation was "chaos."[4] No existing markup scheme satisfied the needs of all users, and much time was being wasted converting from one deficient scheme to another.
Another commonly used method of storing and retrieving information is a relational database such as, for example, Microsoft Access or dBASE or the mainframe program Oracle. In a relational database, data is assumed to take the form of one or more tables consisting of rows and columns, that is, the form of rectangular structures.[5] A simple table of biographical information may have rows representing people and columns holding information about those people, for example, name, date of birth, occupation, and so on. When a person has more than one occupation, the data becomes clumsy and the information is best represented in two tables, in which the second has a row for each occupation of each person. The tables are linked, or related, by the person. A third table may hold information about the occupations. It is not difficult for a human to conceptualize the data structures of a relational database or for a computer to process them. Relational databases work well for some kinds of information, for example, an address list, but in reality not much data in the real world fits well into rectangular structures. Such a structure means that the information is distorted when it is entered into the computer, and processing and analyses are carried out on the distorted forms, whose distortion tends to be forgotten. Relational databases also force the allocation of information to fixed data categories, whereas, in the humanities at any rate, much of the information is subject to scholarly debate and dispute, requiring multiple views of the material to be represented. Furthermore, getting information out of a relational database for use by other programs usually requires some programming knowledge.
The progress of too many retrieval and database projects can be characterized as follows. A project group decides that it wants to "make a CD-ROM." It finds that it has to investigate possible software programs for delivery of the results and chooses the one that has the most seductive user interface or most persuasive salesperson. If the data include some nonstandard characters, the highest priority is often given to displaying those characters on the screen; little attention is paid to the functions needed to manipulate those characters. Data are then entered directly into this software over a period of time during which the software interface begins to look outmoded as technology changes. By the time the data have been entered for the project, the software company has gone out of business, leaving the project staff with a lot of valuable information in a proprietary software format that is no longer supported. More often than not, the data are lost and much time and money has been wasted. The investment is clearly in the data, and it makes
sense to ensure that these data are not dependent on one particular program but can be used by other programs as well.
Standard Generalized Markup Language (Sgml)
Given the time and effort involved in creating electronic information, it makes sense to step back and think about how to ensure that the information can outlast the computer system on which it is created and can also be used for many different purposes. These are the two main principles of the Standard Generalized Markup Language (SGML), which became an international standard (ISO 8879) in 1986.[6] SGML was designed as a general purpose markup scheme that can be applied to many different types of documents and in fact to any electronic information. It consists of plain ASCII files, which can easily be moved from one computer system to another. SGML is a descriptive language. Most encoding schemes prior to SGML use prescriptive markup. One example of prescriptive markup is word-processing or typesetting codes embedded in a text that give instructions to the computer such as "center the next line" or "print these words in italic." Another example is fielded data that is specific to a retrieval program, for example, reference citations or author's names, which must be in a specific format for the retrieval program to recognize them as such. By contrast, a descriptive markup language merely identifies what the components of a document are. It does not give specific instructions to any program. In it, for example, a title is encoded as a title, or a paragraph as a paragraph. This very simple approach ultimately allows much more flexibility. A printing program can print all the titles in italic, a retrieval program can search on the titles, and a hypertext program can link to and from the titles, all without making any changes to the data.
Strictly speaking, SGML itself is not a markup scheme, but a kind of computer language for defining markup, or encoding, schemes. SGML markup schemes assume that each document consists of a collection of objects that nest within each other or are related to each other in some other way. These objects or features can be almost anything. Typically they are structural components such as title, chapter, paragraph, heading, act, scene, speech, but they can also be interpretive information such as parts of speech, names of people and places, quotations (direct and indirect), and even literary or historical interpretation. The first stage of any SGML-based project is document analysis, which identifies all the textual features that are of interest and identifies the relationships between them. This step can take some time, but it is worth investing the time since a thorough document analysis can ensure that data entry proceeds smoothly and that the documents are easily processable by computer programs.
In SGML terms, the objects within a document are called elements. They are identified by a start and end tag as follows: <title>Pride and Prejudice</title>.
The SGML syntax allows the document designer to specify all the possible elements as a Document Type Definition (DTD), which is a kind of formal model of the document structure. The DTD indicates which elements are contained within other elements, which are optional, which can be repeated, and so forth. For example, in simple terms a journal article consists of a title, one or more author names, an optional abstract, and an optional list of keywords, followed by the body of the article. The body may contain sections, each with a heading followed by one or more paragraphs of text. The article may finish with a bibliography. The paragraphs of text may contain other features of interest, including quotations, lists, and names, as well as links to notes. A play has a rather different structure: title; author; cast list; one or more acts, each containing one or more scenes, which in turn contain one or more speeches and stage directions; and so on.
SGML elements may also have attributes that further specify or modify the element. One use of attributes may be to normalize the spelling of names for indexing purposes. For example, the name Jack Smyth could be encoded as <name norm="SmithJ"> Jack Smyth</name>, but indexed under S as if it were Smith. Attributes can also be used to normalize date forms for sorting, for example, <date norm=19970315>the Ides of March 1997</date>. Another important function of attributes is to assign a unique identifier to each instance of each SGML element within a document. These identifiers can be used as a cross-reference by any kind of hypertext program. The list of possible attributes for an element may be defined as a closed set, allowing the encoder to pick from a list, or it may be entirely open.
SGML has another very useful feature. Any piece of information can be given a name and be referred to by that name in an SGML document. These names are called entities and are enclosed in an ampersand and a semicolon. One use is for nonstandard characters, where, for example, é can be encoded as é thus ensuring that it can be transmitted easily across networks and from one machine to another. A standard list of these characters exists, but the document encoder can also create more. Entity references can also be used for any boilerplate text. This use avoids repetitive typing of words and phrases that are repeated, thus also reducing the chance of errors. An entity reference can be resolved to any amount of text from a single letter up to the equivalent of an entire chapter.
The formal structure of SGML means that the encoding of a document can be validated automatically, a process known as parsing. The parser makes use of the SGML DTD to determine the structure of the document and can thus help to eliminate whole classes of encoding errors before the document is processed by an application program. For example, an error can be detected if the DTD specifies that a journal article must have one or more authors, but the author's name has been omitted accidentally. Mistyped element names can be detected as errors, as can elements that are wrongly nested-for example, an act within a scene when the DTD specifies that acts contain scenes. Attributes can also be validated when there is a closed set of possible values. The validation process can also detect un-
resolved cross-references that use SGML's built-in identifiers. The SGML document structure and validation process means that any application program can operate more efficiently because it derives information from the DTD about what to expect in the document. It follows that the stricter the DTD, the easier it is to process the document. However, very strict DTDs may force the document encoder to make decisions that simplify what is being encoded. Free DTDs might better reflect the nature of the information but usually require more processing. Another advantage of SGML is very apparent here. Once a project is under way, if a document encoder finds a new feature of interest, that feature can simply be added to the DTD without the need to restructure work that has already been done. Many documents can be encoded and processed with the same DTD.
Text Encoding Initiative
The humanities computing community was among the early adopters of SGML, for two very simple reasons. Humanities primary source texts can be very complex, and they need to be shared and used by different scholars. They can be in different languages and writing systems and can contain textual variants, nonstandard characters, annotations and emendations, multiple parallel texts, and hypertext links, as well as complex canonical reference systems. In electronic form, these texts can be used for many different purposes, including the preparation of new editions, word and phrase searches, stylistic analyses and research on syntax, and other linguistic features. By 1987 it was clear that many encoding schemes existed for humanities electronic texts, but none was sufficiently powerful to allow for all the different features that might be of interest. Following a planning meeting attended by representatives of leading humanities computing projects, a major international project called the Text Encoding Initiative (TEI) was launched.[7] Sponsored by the Association for Computers and the Humanities, the Association for Computational Linguistics, and the Association for Literary and Linguistic Computing, the TEI enlisted the help of volunteers all over the world to define what features might be of interest to humanities scholars working with electronic text. It built on the expertise of groups such as the Perseus Project (then at Harvard, now at Tufts University), the Brown University Women Writers Project, the Alfa Informatica Group in Groningen, Netherlands, and others who were already working with SGML, to create SGML tags that could be used for many different types of text.
The TEI published its Guidelines for the Encoding and Interchange of Electronic Texts in May 1994 after more than six years' work. The guidelines identify some four hundred tags, but of course no list of tags can be truly comprehensive, and so the TEI builds its DTDs in a way that makes it easy for users to modify them. The TEI SGML application is built on the assumption that all texts share some common core of features to which can be added tags for specific application areas. Very few tags are mandatory, and most of these are concerned with documenting the text
and will be further discussed below. The TEI Guidelines are simply guidelines. They serve to help the encoder identify features of interest, and they provide the DTDs with which the encoder will work. The core consists of the header, which documents the text, plus basic structural tags and common features, such as lists, abbreviations, bibliographic citations, quotations, simple names and dates, and so on. The user selects a base tag set: prose, verse, drama, dictionaries, spoken texts, or terminological data. To this are added one or more additional tag sets. The options here include simple analytic mechanisms, linking and hypertext, transcription of primary sources, critical apparatus, names and dates, and some methods of handling graphics. The TEI has also defined a method of handling nonstandard alphabets by using a Writing System Declaration, which the user specifies. This method can also be used for nonalphabetic writing systems, for example, Japanese. Building a TEI DTD has been likened to the preparation of a pizza, where the base tag set is the crust, the core tags are the tomato and cheese, and the additional tag sets are the toppings.
One of the issues addressed at the TEI planning meeting was the need for documentation of an electronic text. Many electronic texts now exist about which little is known, that is, what source text they were taken from, what decisions were made in encoding the text, or what changes have been made to the text. All this information is extremely important to a scholar wanting to work on the text, since it will determine the academic credibility of his or her work. Unknown sources are unreliable at best and lead to inferior work. Experience has shown that electronic texts are more likely to contain errors or have bits missing, but these are more difficult to detect than with printed material. It seems that one of the main reasons for this lack of documentation for electronic texts was simply that there was no common methodology for providing it.
The TEI examined various models for documenting electronic texts and concluded that some SGML elements placed as a header at the beginning of an electronic text file would be the most appropriate way of providing this information. Since the header is part of the electronic text file, it is more likely to remain with that file throughout its life. It can also be processed by the same software as the rest of the text. The TEI header contains four major sections.[8] One section is a bibliographic description of the electronic text file using SGML elements that map closely on to some MARC fields. The electronic text is an intellectual object different from the source from which it was created, and the source is thus also identified in the header. The encoding description section provides information about the principles used in encoding the text, for example, whether the spelling has been normalized, treatment of end-of-line hyphens, and so forth. For spoken texts, the header provides a way of identifying the participants in a conversation and of attaching a simple identifier to each participant that can then be used as an attribute on each utterance. The header also provides a revision history of the text, indicating who made what changes to it and when.
As far as can be ascertained, the TEI header is the first systematic attempt to
provide documentation for an electronic text that is a part of the text file itself. A good many projects are now using it, but experience has shown that it would perhaps benefit from some revision. Scholars find it hard to create good headers. Some elements in the header are very obvious, but the relative importance of the remaining elements is not so clear. At some institutions, librarians are creating TEI headers, but they need training in the use and importance of the nonbibliographic sections and in how the header is used by computer software other than the bibliographic tools that they are familiar with.
Encoded Archival Description (Ead)
Another SGML application that has attracted a lot of attention in the scholarly community and archival world is the Encoded Archival Description (EAD). First developed by Daniel Pitti at the University of California at Berkeley and now taken over by the Library of Congress, the EAD is an SGML application for archival finding aids.[9] Finding aids are very suitable for SGML because they are basically hierarchic in structure. In simple terms, a collection is divided into series, which consist of boxes, which contain folders, and so on. Prior to the EAD, there was no effective standard way of preparing finding aids. Typical projects created a collection level record in one of the bibliographic utilities, such as RLIN, and used their own procedures, often a word-processing program, for creating the finding aid. Possibilities now exist for using SGML to link electronic finding aids with electronic representations of the archival material itself. One such experiment, conducted at the Center for Electronic Texts in the Humanities (CETH), has created an EAD-encoded finding aid for part of the Griffis Collection at Rutgers University and has encoded a small number of the items in the collection (nineteenth-century essays) in the TEI scheme.[10] The user can work with the finding aid to locate the item of interest and then move directly to the encoded text and an image of the text to study the item in more detail. The SGML browser program Panorama allows the two DTDs to exist side by side and in fact uses an extended pointer mechanism devised by the TEI to move from one to the other.
Other Applications of SGML
SGML is now being widely adopted in the commercial world as companies see the advantage of investment in data that will move easily from one computer system to another. It is worth noting that the few books on SGML that appeared early in its life were intended for an academic audience. More recent books are intended for a commercial audience and emphasize the cost savings involved in SGML as well as the technical requirements. This is not to say that these books are not of any value to academic users. The SGML Web pages list many projects in the areas of health, legal documents, electronic journals, rail and air transport, semiconductors, the U.S. Internal Revenue Service, and more. SGML is extremely useful
for technical documentation, as can be evidenced by the list of customers on the Web page of one of the major SGML software companies, INSO/EBT. This list includes United Airlines, Novell, British Telecom, AT&T, Shell, Boeing, Nissan, and Volvo.
SGML need not be used only with textual data. It can be used to describe almost anything. SGML should not therefore be seen as an alternative to Acrobat, PostScript, or other document formats but as a way of describing and linking together documents in these and other formats, forming the "underground tunnels" that make the documents work for users.[11] SGML can be used to encode the searchable textual information that must accompany images or other formats in order to make them useful. With SGML, the searchable elements can be defined to fit the data exactly and can be used by different systems. This encoding is in contrast with storing image data in some proprietary database system, which is common practice. We can imagine a future situation in which a scholar wants to examine the digital image of a manuscript and also have available a searchable text. He or she may well find something of interest on the image and want to go to occurrences of the same feature elsewhere within the text. In order to do this, the encoded version of the text must know what that feature of interest is and where it occurs on the digital image. Knowing which page it is on is not enough. The exact position on the page must be encoded. This information can be represented in SGML, which thus provides the sophisticated kind of linking needed for scholarly applications. SGML structures can also point to places within a recording of speech or other sound and can be used to link the sound to a transcription of the conversation, again enabling the sound and text to be studied together. Other programs exist that can perform these functions, but the problem with all of them is that they use a proprietary data format that cannot be used for any other purpose.
SGML, HTML, and XML
The relationship between SGML and the Hypertext Markup Language (HTML) needs to be clearly understood. Although not originally designed as such, HTML is now an SGML application, even though many HTML documents exist that cannot be validated according to the rules of SGML. HTML consists of a set of elements that are interpreted by Web browsers for display purposes. The HTML tags were designed for display and not for other kinds of analysis, which is why only crude searches are possible on Web documents. HTML is a rather curious mixture of elements. Larger ones, such as <body>; <h1>, <h2>, and so on for head levels; <p> for paragraph; and <ul> for unordered list, are structural, but the smaller elements, such as <b> for bold and <i> for italic, are typographic, which, as we have seen above, are ambiguous and thus cannot be searched effectively. HTML version 3 attempts to rectify this ambiguity somewhat by introducing a few semantic level elements, but these are very few in comparison with those
identified in the TEI core set. HTML can be a good introduction to structured markup. Since it is so easy to create, many project managers begin by using HTML and graduate to SGML once they become used to working with structured text and begin to see the weakness of HTML for anything other than the display of text. SGML can easily be converted automatically to HTML for delivery on the Web, and Web clients have been written for the major SGML retrieval programs.
The move from HTML to SGML can be substantial, and in 1996 work began on XML (Extensible Markup Language), which is a simplified version of SGML for delivery on the Web. It is "an extremely simple dialect of SGML," the goal of which "is to enable generic SGML to be served, received, and processed on the Web in the way that is now possible with HTML" (see http://www.w3.org/TR/REC-xml ). XML is being developed under the auspices of the World Wide Web Consortium, and the first draft of the specification for it was available by the SGML conference in December 1996. Essentially XML is SGML with some of the more complex and esoteric features removed. It has been designed for interoperability with both SGML and HTML-that is, to fill the gap between HTML, which is too simple, and fullblown SGML, which can be complicated. As yet there is no specific XML software, but the work of this group has considerable backing and the design of XML has proceeded quickly.[12]
SGML and New Models of Scholarship
SGML's objectlike structures make it possible for scholarly communication to be seen as "chunks" of information that can be put together in different ways. Using SGML, we no longer have to squeeze the product of our research into a single linear sequence of text whose size is often determined by the physical medium in which it will appear; instead we can organize it in many different ways, privileging some for one audience and others for a different audience. Some projects are already exploiting this potential, and I am collaborating in two that are indicative of the way I think humanities scholarship will develop in the twenty-first century. Both projects make use of SGML to create information objects that can be delivered in many different ways.
The Model Editions Partnership (MEP) is defining a set of models for electronic documentary editions.[13] Directed by David Chesnutt of the University of South Carolina, with the TEI Editor, C. Michael Sperberg-McQueen, and myself as co-coordinators, the MEP also includes seven documentary editing projects. Two of these projects are creating image editions, and the other five are preparing letterpress publications. These documentary editions provide the basic source material for the study of American history by adding the historical context that makes the material meaningful to readers. Much of this source material consists of letters, which often refer to people and places by words that only the author and recipient understand. A good deal of the source material is in handwriting that
can be read only by scholars specializing in the field. Documentary editors prepare the material for publication by transcribing the documents, organizing the sources into a coherent sequence that tells the story (the history) behind them, and annotating them with information to help the reader understand them. However, the printed page is not a very good vehicle for conveying the information that documentary editors need to say. It forces one organizing principle on the material (the single linear sequence of the book) when the material could well be organized in several different ways (chronologically, for example, or by recipient of letters). Notes must appear at the end of an item to which they refer or at the end of the book. When the same note-for example, a short biographical sketch of somebody mentioned in the sources-is needed in several places, it can appear only once, and after that it is cross-referenced by page numbers, often to earlier volumes. Something that has been crossed out and rewritten in a source document can only be represented clumsily in print even though it may reflect a change of mind that altered the course of history.
At the beginning of the MEP project, the three coordinators visited all seven partner projects, showed the project participants some very simple demonstrations, and then invited them to "dream" about what they would like to do in this new medium. The ideas collected during these visits were incorporated into a prospectus for electronic documentary editions. The MEP sees SGML as the key to providing all the functionality outlined in the prospectus. The MEP has developed an SGML DTD for documentary editions that is based on the TEI and has begun to experiment with delivery of samples from the partner projects. The material for the image editions is wrapped up in an "SGML envelope" that provides the tools to access the images. This envelope can be generated automatically from the relational databases in which the image access information is now stored. For the letterpress editions, many more possibilities are apparent. If desired, it will be possible to merge material from different projects that are working on the same period of history. It will be possible to select subsets of the material easily by any of the tagged features. This means that editions for high school students or the general public could be created almost automatically from the archive of scholarly material. With a click of a mouse, the user can go from a diplomatic edition to a clear reading text and thus trace the author's thoughts as the document was being written. The documentary editions also include very detailed conceptual indexes compiled by the editors. It will be possible to use these indexes as an entry point to the text and also to merge indexes from different projects. The MEP sees the need for making dead text image representations of existing published editions available quickly and believes that these can be made much more useful by wrapping them in SGML and using the conceptual indexes as an entry point to them.
The second project is even more ambitious than the MEP, since it is dealing with entirely new material and has been funded for five years. The Orlando Project at the Universities of Alberta and Guelph is a major collaborative research ini-
tiative funded by the Canadian Social Sciences and Humanities Research Council.[14] Directed by Patricia Clements, the project is to create an Integrated History of Women's Writing in the British Isles, which will appear in print and electronic formats. A team of graduate research assistants is carrying out basic research for the project in libraries and elsewhere. The research material they are assembling is being encoded in SGML so that it can be retrieved in many different ways. SGML DTDs have been designed to reflect the biographical details for each woman writer as well as her writing history, other historical events that influenced her writing, a thesaurus of keyword terms, and so forth. The DTDs are based on the TEI but they incorporate much descriptive and interpretive information, reflecting the nature of the research and the views of the literary scholars in the team. Tag sets have been devised for topics such as the issues of authorship and attribution, genre issues, and issues of reception of an author's work.
The Orlando Project is thus building up an SGML-encoded database of many different kinds of information about women's writing in the British Isles. The SGML encoding, for example, greatly assists in the preparation of a chronology by allowing the project to pull out all chronology items from the different documents and sort them by their dates. It facilitates an overview of where the women writers lived, their social background, and what external factors influenced their writing. It helps with the creation and consistency of new entries, since the researchers can see immediately if similar information has already been encountered. The authors of the print volumes will draw on this SGML archive as they write, but the archive can also be used to create many different hypertext products for research and teaching.
Both Orlando and the MEP are, essentially, working with pieces of information, which can be linked in many different ways. The linking, or rather the interpretation that gives rise to the linking, is what humanities scholarship is about. When the information is stored as encoded pieces of information, it can be put together in many different ways and used for many different purposes, of which creating a print publication is only one. We can expect other projects to begin to work in this way as they see the advantages of encoding the features of interest in their material and of manipulating them in different ways.
It is useful to look briefly at some other possibilities. Dictionary publishers were among the first to use SGML. (Although not strictly SGML since it does not have a DTD, the Oxford English Dictionary was the first academic project to use structured markup.) When well designed, the markup enables the dictionary publishers to create spin-off products for different audiences by selecting a subset of the tagged components of an entry. A similar process can be used for other kinds of reference works. Tables of contents, bibliographies, and indexes can all be compiled automatically from SGML markup and can also be cumulative across volumes or collections of material.
The MEP is just one project that uses SGML for scholarly editions. A notable
example is the CD-ROM of Chaucer's Wife of Bath's Prologue, prepared by Peter Robinson and published by Cambridge University Press in 1996. This CD-ROM contains all fifty-eight pre-1500 manuscripts of the text, with encoding for all the variant readings as well as digitized images of every page of all the manuscripts. Software programs provided with the CD-ROM can manipulate the material in many different ways, enabling a scholar to collate manuscripts, move immediately from one manuscript to another, and compare transcriptions, spellings, and readings. All the material is encoded in SGML, and the CD-ROM includes more than one million hypertext links generated by a computer program, which means that the investment in the project's data is carried forward from one delivery system to another, indefinitely, into the future.
Making SGML Work Effectively
Getting started with SGML can seem to be a big hurdle to overcome, but in fact the actual mechanics of working with SGML are nowhere near as difficult as is often assumed. SGML tags are rarely typed in, but are normally inserted by software programs such as Author/Editor. These programs can incorporate a template that is filled in with data. Like other SGML software, these programs make use of the DTD. They know which tags are valid at any position in the document and can offer only those tags to the user, who can pick from a menu. They can also provide a pick list of attributes and their values if the values are a closed set. These programs ensure that what is produced is a valid SGML document. They can also toggle the display of tags on and off very easily-Author/Editor encloses them in boxes that are very easy to see. The programs also incorporate style sheets that define the display format for every element.
Nevertheless, inserting tags in this way can be rather cumbersome, and various software tools exist to help in the translation of "legacy" data to SGML. Of course, these tools cannot add intelligence to data if it was not there in the legacy format, but they can do a reasonable and low-cost job of converting material for large-scale projects in which only broad structural information is needed. For UNIX users, the shareware program sgmls and its successor, sp, are excellent tools for validating SGML documents and can be incorporated in processing programs. There are also ways in which the markup can be minimized. End tags can be omitted in some circumstances, for example, in a list where the start of a new list item implies that the previous one has ended.
There is no doubt that SGML is considered expensive by some project managers, but further down the line the payoff can be seen many times over. The quick and dirty solution to a computing problem does not last very long, and history has shown how much time can be wasted converting from one system to another or how much data can be lost because they are in a proprietary system. It is rather surprising that the simple notion of encoding what the parts of a document are,
rather than what the computer is supposed to do with them, took so long to catch on. Much of the investment in any computer project is in the data, and SGML is the best way we know so far of ensuring that the data will last for a long time and that they can be used and reused for many different purposes. It also ensures that the project is not dependent on one software vendor.
The amount of encoding is obviously a key factor in the cost, and so any discussion about the cost-effectiveness of an SGML project should always be made with reference to the specific DTD in use and the level of markup to be inserted. Statements that SGML costs x dollars per page are not meaningful without further qualification. Unfortunately at present such further qualification seems rarely to be the case, and misconceptions often occur. It is quite possible, although clearly not sensible, to have a valid SGML document that consists of one start tag at the beginning and one corresponding end tag at the end with no other markup in between. At the other extreme, each word (or even letter) in the document could have several layers of markup attached to it. What is clear is that the more markup there is, the more useful the document is and the more expensive it is to create. As far as I am aware, little research has been done on the optimum level of markup, but at least with SGML it is possible to add markup to a document later without prejudicing what is already encoded.
In my view, it is virtually impossible to make some general cost statements for SGML-based work. Each project needs to be assessed differently depending on its current situation and its objectives.[15] However, I will attempt to discuss some of the issues and the items that make up the overall cost. Many of the costs of an SGML-based project are no different from those of other computer-based projects in that both have start-up costs and ongoing costs.
Start-up costs can depend on how much computing experience and expertise there already is in the organization. Projects that are being started now have the advantage of not being encumbered by large amounts of legacy data and proprietary systems, but they also will need to be started from scratch with the three things that make any computer project work: hardware, software, and skilled people. Hardware costs are insignificant these days, and SGML software will work on almost any current PC or UNIX-based hardware. It does not need an expensive proprietary system. An individual scholar can acquire PC software for creating and viewing SGML-encoded text for under $500. Public domain UNIX tools cost nothing to acquire. That leaves what is, in my view, the most essential component of any computing project, namely, people with good technical skills. Unfortunately, these people are expensive. The market is such that they can expect higher salaries than librarians and publishers receive at the equivalent stages in their careers. However, I think that it is unwise for any organization to embark on a computer-based project without having staff with the proper skills to do the work. Like people in all other disciplines, computer people specialize in one or two areas, and so it is important to hire staff with the right computing skills and thus impor-
tant for the person doing the hiring to understand what those skills should be. There are still not many SGML specialists around, but someone with a good basic background in computing could be trained in SGML at a commercial or academic course in a week or so, with some follow-up time for experimentation. This person can then use mailing lists and the SGML Web site to keep in touch with new developments. Having the right kind of technical person around early on in any computing project also means that there is somebody who can advise on the development of the system and ensure that expensive mistakes are not made by decision makers who have had little previous involvement with computing systems. The technical person will also be able to see immediately where costs can be saved by implementing shortcuts.
The one specific start-up cost with SGML is the choice or development of the DTD. Many digital library projects are utilizing existing DTDs-for example, the cut-down version of the TEI called TEILite-either with no changes at all or with only light modifications. However, I think that it is important for project managers to look hard at an existing DTD to see whether it really satisfies their requirements rather than just decide to use it because everyone else they know is using it. A project in a very specialized area may need to have its own DTD developed. This could mean the hiring of SGML consultants for a few days plus time spent by the project's own staff in specifying the objectives of the project in great detail and in defining and refining the features of interest within the project's documents.
Computer-based projects seldom proceed smoothly, and in the start-up phase, time must be allowed for false starts and revisions. SGML is no different here, but by its nature it does force project managers to consider very many aspects at the beginning and thus help prevent the project from going a long way down a wrong road. SGML elements can also be used to assist with essential aspects of project administration, for example, tags for document control and management.
Ongoing costs are largely concerned with document creation and encoding, but they also include general maintenance, upgrades, and revisions. If the material is not already in electronic form, it may be possible to convert it by optical character recognition (OCR). The accuracy of the result will depend on the quality of the type fonts and paper of the original, but the document will almost certainly need to be proofread and edited to reach the level of quality acceptable to the scholarly community. OCR also yields a typographic representation of a document, which is ambiguous for other kinds of computer processing. Whether it comes from word processors or OCR, typographic encoding needs to be converted to SGML. It is possible to write programs or purchase software tools to do this, but only those features that can be unambiguously defined can be converted in this way. Any markup that requires interpretive judgment must be inserted manually at the cost of human time. Most electronic text projects in the humanities have had the material entered directly by keyboarding, not only to attain higher levels of accuracy than with OCR, but also to insert markup at the same time. More often than not, project managers employ graduate students for this
work, supervised by a textbase manager who keeps records of decisions made in the encoding and often assisted by a programmer who can identify shortcuts and write programs where necessary to handle these shortcuts.
There are also, of course, costs associated with delivering SGML-encoded material once it has been created. These costs fall into much the same categories as the costs for creating the material. Start-up costs include the choice and installation of delivery software. In practice, most digital library projects use the Opentext search engine, which is affordable for a library or a publisher. The search engine also needs a Web client, which need not be a big task for a programmer. Naturally it takes longer to write a better Web client, but a better client may save end users much time as they sort through the results of a query. Opentext is essentially a retrieval program, and it does not provide much in the way of hypertext linking. INSO/EBT's suite of programs, including DynaText and DynaWeb, provides a model of a document that is much more like an electronic book with hypertext links. INSO's Higher Education Grant Program has enabled projects like MEP and Orlando to deliver samples of their material without the need to purchase SGML delivery software. INSO offers some technical support as part of the grant package, but skilled staff are once again the key component for getting a delivery system up and running. When any delivery system is functioning well, the addition of new SGML-encoded material to the document database can be fully automated with little need for human intervention unless something goes wrong.
Experience has shown that computer-based projects are rarely, if ever, finished. They will always need maintenance and upgrades and will incur ongoing costs more or less forever if the material is not to be lost. SGML seems to me to be the best way of investing for the future, since there are no technical problems in migrating it to new systems. However, I find it difficult to envisage a time when there will be no work and no expense involved with maintaining and updating electronic information. It is as well to understand this and to budget for these ongoing costs at the beginning of a project rather than have them come out gradually as the project proceeds.
SGML does have one significant weakness. It assumes that each document is a single hierarchic structure, but in the real world (at least of the humanities) very few documents are as simple as this.[16] For example, a printed edition of a play has one structure of acts, scenes, and speeches and another of pages and line numbers. A new act or scene does not normally start on a new page, and so there is no relationship between the pages and the act and scene structure. It is simply an accident of the typography. The problem arises even with paragraphs in prose texts, since a new page does not start with a new paragraph or a new paragraph with a new page. For well-known editions the page numbers are important, but they cannot easily be encoded in SGML other than as "empty" tags that simply indicate a point in the text, not the beginning and end of a piece of information. The disadvantage here is that the processing of information marked by empty tags cannot make full use of SGML's capabilities. Another example of the same problem is
quotations spanning over paragraphs. They have to be closed and then opened again with attributes to indicate that they are really all the same quotation.
For many scholars, SGML is exciting to work with because it opens up so many more possibilities for working with source material. We now have a much better way than ever before of representing in electronic form the kinds of interpretation and discussion that are the basis of scholarship in the humanities. But as we begin to understand these new possibilities, some new challenges appear.[17] What happens when documents from different sources (and thus different DTDs) are merged into the same database? In theory, computers make it very easy to do this, but how do we merge material that has been encoded according to different theoretical perspectives and retain the identification and individuality of each perspective? It is possible to build some kind of "mega-DTD," but the mega-DTD may become so free in structure that it is difficult to do any useful processing of the material.
Attention must now turn to making SGML work more effectively. Finding better ways of adding markup to documents is a high priority. The tagging could be speeded up by a program that can make intelligent tagging guesses based on information it has derived from similar material that has already been tagged, in much the same way that some word class tagging programs "learn" from text that has already been tagged manually. We also need to find ways of linking encoded text to digital images of the same material without the need for hand coding. Easier ways must be found for handling multiple parallel structures. All research leading to better use of SGML could benefit from a detailed analysis of documents that have already been encoded in SGML. The very fact that they are in SGML makes this analysis easy to do.
Chapter 2—
Digital Image Quality
From Conversion to Presentation and Beyond
Anne R. Kenney
There are a number of significant digital library projects under way that are designed to test the economic value of building digital versus physical libraries. Business cases are being developed that demonstrate the economies of digital applications to assist cultural and research institutions in their response to the challenges of the information explosion, spiraling storage and subscription costs, and increasing user demands. These projects also reveal that the costs of selecting, converting, and making digital information available can be staggering and that the costs of archiving and migrating that information over time are not insignificant.
Economic models comparing the digital to the traditional library show that digital will become more cost-effective provided the following four assumptions prove true:
1. that institutions can share digital collections,
2. that digital collections can alleviate the need to support full traditional libraries at the local level,
3. that use will increase with electronic access, and
4. that the long-term value of digital collections will exceed the costs associated with their creation, maintenance, and delivery.[1]
These four assumptions-resource sharing, lower costs, satisfaction of user demands with timely and enhanced access, and continuing value of information-presume that electronic files will have relevant content and will meet baseline measures of functionality over time. Although a number of conferences and publications have addressed the need to develop selection criteria for digital conversion and to evaluate the effective use of digitized material, more rhetoric than substantive information has emerged regarding the impact on scholarly research of creating digital collections and making them accessible over networks.
I believe that digital conversion efforts will prove economically viable only if they focus on creating electronic resources for long-term use. Retrospective
sources should be carefully selected based on their intellectual content; digital surrogates should effectively capture that intellectual content; and access should be more timely, usable, or cost-effective than is possible with original source documents. In sum, I argue that long-term utility should be defined by the informational value and functionality of digital images, not limited by technical decisions made at the point of conversion or anywhere else along the digitization chain. I advocate a strategy of "full informational capture" to ensure that digital objects rich enough to be useful over time are created in the most cost-effective manner.[2]
There is much to be said for capturing the best possible digital image. From a preservation perspective, the advantages are obvious. An "archival" digital master can be created to replace rapidly deteriorating originals or to reduce storage costs and access times to office back files, provided the digital surrogate is a trusted representation of the hard copy source. It also makes economic sense, as Michael Lesk has noted, to "turn the pages once" and produce a sufficiently high-level image so as to avoid the expense of reconverting at a later date when technological advances require or can effectively utilize a richer digital file.[3] This economic justification is particularly compelling as the labor costs associated with identifying, preparing, inspecting, and indexing digital information far exceed the costs of the scan itself. In recent years, the costs of scanning and storage have declined rapidly, narrowing the gap between high-quality and low-quality digital image capture. Once created, the archival master can then be used to generate derivatives to meet a variety of current and future user needs: high resolution may be required for printed facsimiles, for on-screen detailed study,[4] and in the future for intensive image processing; moderate to high resolution may be required for character recognition systems and image summarization techniques;[5] and lower resolution images, encoded text, or PDFs derived from the digital masters may be required for on-screen display and browsing.[6] The quality, utility, and expense of all these derivatives will be directly affected by the quality of the initial scan.[7]
If there are compelling reasons for creating the best possible image, there is also much to be said for not capturing more than you need. At some point, adding more resolution will not result in greater quality, just a larger file size and higher costs. The key is to match the conversion process to the informational content of the original. At Cornell, we've been investigating digital imaging in a preservation context for eight years. For the first three years, we concentrated on what was technologically possible-on determining the best image capture we could secure. For the last five years, we've been striving to define the minimal requirements for satisfying informational capture needs. No more, no less.
Digital Benchmarking
To help us determine what is minimally acceptable, we have been developing a methodology called benchmarking. Digital benchmarking is a systematic proce-
dure used to forecast a likely outcome. It begins with an assessment of the source documents and user needs; factors in relevant objective and subjective variables associated with stated quality, cost, and/or performance objectives; involves the use of formulas that represent the interrelationship of those variables to desired outcomes; and concludes with confirmation through carefully structured testing and evaluation. If the benchmarking formula does not consistently predict the outcome, it may not contain the relevant variables or reflect their proper relationship-in which case it should be revised.
Benchmarking does not provide easy answers but a means to evaluate possible answers for how best to balance quality, costs, timeliness, user requirements, and technological capabilities in the conversion, delivery, and maintenance of digital resources. It is also intended as a means to formulate a range of possible solutions on the macro level rather than on an individual, case-by-case basis. For many aspects of digital imaging, benchmarking is still uncharted territory. Much work remains in defining conversion requirements for certain document types (photographs and complex book illustrations, for example); in conveying color information; in evaluating the effects of new compression algorithms; and in providing access on a mass scale to a digital database of material representing a wide range of document types and document characteristics.
We began benchmarking with the conversion of printed text. We anticipate that within several years, quality benchmarks for image capture and presentation of the broad range of paper- and film-based research materials-including manuscripts, graphic art, halftones, and photographs-will be well defined through a number of projects currently under way.[8] In general, these projects are designed to be system independent and are based increasingly on assessing the attributes and functionality characteristic of the source documents themselves coupled with an understanding of user perceptions and requirements.
Why Do Benchmarking?
Because there are no standards for image quality and because different document types require different scanning processes, there is no "silver bullet" for conversion. This frustrates many librarians and archivists who are seeking a simple solution to a complex issue. I suppose if there really were the need for a silver bullet, I'd recommend that most source documents be scanned at a minimum of 600 dpi with 24-bit color, but that would result in tremendously large file sizes and a hefty conversion cost. You would also be left with the problems of transmitting and displaying those images.
We began benchmarking with conversion, but we are now applying this approach to the presentation of information on-screen. The number of variables that govern display are many, and it will come as no surprise that they preclude the establishment of a single best method for presenting digital images. But here, too,
the urge is strong to seek a single solution. If display requirements paralleled conversion requirements-that is, if a 600 dpi, 24-bit image had to be presented onscreen, then at best, with the highest resolution monitors commercially available, only documents whose physical dimensions did not exceed 2.7" ³ 2.13" could be displayed-and they could not be displayed at their native size. Now most of us are interested in converting and displaying items that are larger than postage stamps, so these "simple solutions" are for most purposes impractical, and compromises will have to be made.
The object of benchmarking is to make informed decisions about a range of choices and to understand in advance the consequences of such decisions. The benchmarking approach can be applied across the full continuum of the digitization chain, from conversion to storage to access to presentation. Our belief at Cornell is that benchmarking must be approached holistically, that it is essential to understand at the point of selection what the consequences will be for conversion and presentation. This is especially important as institutions consider inaugurating large-scale conversion projects. Toward this end, the advantages of benchmarking are several in number.
1. Benchmarking is first and foremost a management tool, designed to lead to informed decision making. It offers a starting point and a means for narrowing the range of choices to a manageable number. Although clearly benchmarking decisions must be judged through actual implementations, the time spent in experimentation can be reduced, the temptation to overstate or understate requirements may be avoided, and the initial assessment requires no specialized equipment or expenditure of funds. Benchmarking allows you to scale knowledgeably and to make decisions on a macro level rather than to determine those requirements through item-by-item review or by setting requirements for groups of materials that may be adequate for only a portion of them.
2. Benchmarking provides a means for interpreting vendor claims. If you have spent any time reading product literature, you may have become convinced, as I have, that the sole aim of any company is to sell its product. Technical information will be presented in the most favorable light, which is often incomplete and intended to discourage product comparisons. One film scanner, for instance, may be advertised as having a resolution of 7500 dpi; another may claim 400 dpi. In reality, these two scanners could provide the very same capabilities, but it may be difficult to determine that without additional information. You may end up spending considerable time on the phone, first getting past the marketing representatives and then closely questioning those with a technical understanding of the product's capabilities. If you have benchmarked your requirements, you will be able to focus the discussion on your particular needs.
3. Benchmarking can assist you in negotiating with vendors for services and products. I've spent many years advocating the use of 600 dpi bitonal scanning for printed text, and invariably when I begin a discussion with a representative of an imaging service bureau, he will try to talk me out of such a high resolution, claiming that I do not need it or that it will be exorbitantly expensive. I suspect the representative is motivated to make those claims in part because he believes them and in part because the company may not provide that service and the salesperson wants my business. If I had not benchmarked my resolution requirements, I might be persuaded by what this salesperson has to say.
4. Benchmarking can lead to careful management of resources. If you know up front what your requirements are likely to be and the consequences of those requirements, you can develop a budget that reflects the actual costs, identify prerequisites for meeting those needs, and, perhaps most important, avoid costly mistakes. Nothing will doom an imaging project more quickly than buying the wrong equipment or having to manage image files that are not supported by your institution's technical infrastructure.
5. Benchmarking can also allow you to predict what you can deliver under specific conditions. It is important to understand that an imaging project may break at the weakest link in the digitization chain. For instance, if your institution is considering scanning its map collection, you should be realistic about what ultimately can be delivered to the user's desktop. Benchmarking lets you predict how much of the image and what level of detail can be presented on-screen for various monitors. Even with the most expensive monitor available, presenting oversize material completely, with small detail intact, is impractical.
Having spent some time extolling the virtues of digital benchmarking, I'd like to turn next to describing this methodology as it applies to conversion and then to move to a discussion of on-screen presentation.
Conversion Benchmarking
Determining what constitutes informational content becomes the first step in the conversion benchmarking process. This can be done objectively or subjectively. Let's consider an objective approach first.
Objective Evaluation
One way to perform an objective evaluation would be to determine conversion requirements based on the process used to create the original document. Take resolution, for instance. Film resolution can be measured by the size of the silver crystalline clusters suspended in an emulsion, whose distinct characteristics are appreciated only under microscopic examination. Should we aim for capturing the
properties of the chemical process used to create the original? Or should we peg resolution requirements at the recording capability of the camera or printer used?
There are objective scientific tests that can measure the overall information carrying capacity of an imaging system, such as the Modulation Transfer Function, but such tests require expensive equipment and are still beyond the capability of most institutions except industrial or research labs.[9] In practical applications, the resolving power of a microfilm camera is measured by means of a technical test chart in which the distinct number of black and white lines discerned is multiplied by the reduction ratio used to determine the number of line pairs per millimeter. A system resolution of 120 line pairs per millimeter (lppm) is considered good; above 120 is considered excellent. To digitally capture all the information present on a 35 mm frame of film with a resolution of 120 Ippm would take a bitonal film scanner with a pixel array of 12,240.[10] There is no such beast on the market today.
How far down this path should we go? It may be appropriate to require that the digital image accurately depict the gouges of a woodcut or the scoops of a stipple engraving, but what about the exact dot pattern and screen ruling of a halftone? the strokes and acid bite of an etching? the black lace of an aquatint that becomes visible only at a magnification above 25³ ? Offset publications are printed at 1200 dpi-should we choose that resolution as our starting point for scanning text?
Significant information may well be present at that level in some cases, as may be argued for medical X rays, but in other cases, attempting to capture all possible information will far exceed the inherent properties of the image as distinct from the medium and process used to create it. Consider for instance a 4" ³ 5" negative of a badly blurred photograph. The negative is incredibly information dense, but the information it conveys is not significant.
Obviously, any practical application of digital conversion would be overwhelmed by the recording, computing, and storage requirements that would be needed to support capture at the structure or process level. Although offset printing may be produced at 1200 dpi, most individuals would not be able to discern the difference between a 600 dpi and a 1000 dpi digital image of that page, even under magnification. The higher resolution adds more bits and increases the file size but with little to no appreciable gain. The difference between 300 dpi and 600 dpi, however, can be easily observed and, in my opinion, is worth the extra time and expense to obtain. The relationship between resolution and image quality is not linear: at some point as resolution increases, the gain in image quality will level off. Benchmarking will help you to determine where the leveling begins.
Subjective Evaluation
I would argue, then, that determining what constitutes informational content is best done subjectively. It should be based on an assessment of the attributes of the document rather than the process used to create that document. Reformatting via
digital-or analog-techniques presumes that the essential meaning of an original can somehow be captured and presented in another format. There is always some loss of information when an object is copied. The key is to determine whether that informational loss is significant. Obviously for some items, particularly those of intrinsic value, a copy can serve only as a surrogate, not as a replacement. This determination should be made by those with curatorial responsibility and a good understanding of the nature and significance of the material. Those with a trained eye should consider the attributes of the document itself as well as the immediate and potential uses that researchers will make of its informational content.
Determining Scanning Resolution Requirements for Replacement Purposes
To illustrate benchmarking for conversion, let's consider the brittle book. For brittle books published during the last century and a half, detail has come to represent the size of the smallest significant character in the text, usually the lowercase e. To capture this information-which consists of black ink on a light background-resolution is the key determinant of image quality.
Benchmarking resolution requirements in a digital world have their roots in micrographics, where standards for predicting image quality are based on the Quality Index (QI). QI provides a means for relating system resolution and text legibility. It is based on multiplying the height of the smallest significant character, h, by the smallest line pair pattern resolved by a camera on a technical test target, p: QI = h³p. The resulting number is called the Quality Index, and it is used to forecast levels of image quality-marginal (3.6), medium (5.0), or high (8.0)-that will be achieved on the film. This approach can be used in the digital world, but the differences in the ways microfilm cameras and scanners capture detail must be accounted for.[11] Specifically, it is necessary to make the following adjustments:
1. Establish levels of image quality for digitally rendered characters that are analogous to those established for microfilming. In photographically reproduced images, quality degradation results in a fuzzy or blurred image. Usually degradation with digital conversion is revealed in the ragged or stairstepping appearance of diagonal lines or curves, known as aliasing, or "jaggies."
2. Rationalize system measurements. Digital resolution is measured in dots per inch; classic resolution is measured in line pairs per millimeter. To calculate QI based on scanning resolution, you must convert from one to the other. One millimeter equals 0.039 inches, so to determine the number of dots per millimeter, multiply the dpi by 0.039.
3. Equate dots to line pairs. Again, classic resolution refers to line pairs per millimeter (one black line and one white line), and since a dot occupies the same space as a line, two dots must be used to represent one line pair. This means the dpi must be divided by two to be made equivalent to p.
With these adjustments, we can modify the QI formula to create a digital equivalent. From QI = p ³h, we now have QI = 0.039 dpi ³h/2, which can be simplified to 0.0195 dpi ³h.
For bitonal scanning, we would also want to adjust for possible misregistration due to sampling errors brought about in the thresholding process in which all pixels are reduced to either black or white. To be on the conservative side, the authors of AIIM TR26-1993 advise increasing the input scanning resolution by at least 50% to compensate for possible image detector misalignment. The formula would then be QI = 0.039 dpi ³h/3, which can be simplified to 0.013 dpi ³h.
So How Does Conversion Benchmarking Work?
Consider a printed page that contains characters measuring 2 mm high or greater. If the page were scanned at 300 dpi, what level of quality would you expect to obtain? By plugging in the dpi and the character height and solving for QI, you would discover that you can expect a QI of 8, or excellent rendering.
You can also solve the equation for the other variables. Consider, for example, a scanner with a maximum of 400 dpi. You can benchmark the size of the smallest character that you could capture with medium quality (a QI of 5), which would be .96 mm high. Or you can calculate the input scanning resolution required to achieve excellent rendering of a character that is 3 mm high (200 dpi).
With this formula and an understanding of the nature of your source documents, you can benchmark the scanning resolution needs for printed material. We took this knowledge and applied it to the types of documents we were scanning- brittle books published from 1850 to 1950. We reviewed printers' type sizes commonly used by publishers during this period and discovered that virtually none utilized type fonts smaller than I mm in height, which, according to our benchmarking formula, could be captured with excellent quality using 600 dpi bitonal scanning. We then tested these benchmarks by conducting an extensive on-screen and in-print examination of digital facsimiles for the smallest font-sized Roman and non-Roman type scripts used during this period. This verification process confirmed that an input scanning resolution of 600 dpi was indeed sufficient to capture the monochrome text-based information contained in virtually all books published during the period of paper's greatest brittleness. Although many of those books do not contain text that is as small as I mm in height, a sufficient number of them do. To avoid the labor and expense of performing item-by-item review, we currently scan all books at 600 dpi resolution.[12]
Conversion Benchmarking beyond Text
Although we've conducted most of our experiments on printed text, we are beginning to benchmark resolution requirements for nontextual documents as well. For non-text-based material, we have begun to develop a benchmarking formula that would be based on the width of the smallest stroke or mark on the page rather
than a complete detail. This approach was used by the Nordic Digital Research Institute to determine resolution requirements for the conversion of historic Icelandic maps and is being followed in the current New York State Kodak Photo CD project being conducted at Cornell on behalf of the Eleven Comprehensive Research Libraries of New York State.[13] The measurement of such fine detail will require the use of a 25 to 50 ³ loupe with a metric hairline that differentiates below 0.1 mm.
Benchmarking for conversion can be extended beyond resolution to tonal reproduction (both grayscale and color); to the capture of depth, overlay, and translucency; to assessing the effects of compression techniques and levels of compression used on image quality; to evaluating the capabilities of a particular scanning methodology, such as the Kodak Photo CD format. Benchmarking can also be used for evaluating quality requirements for a particular category of material- halftones, for example-or to examine the relationship between the size of the document and the size of its significant details, a very challenging relationship that affects both the conversion and the presentation of maps, newspapers, architectural drawings, and other oversized, highly detailed source documents.
In sum, conversion benchmarking involves both subjective and objective components. There must be the means to establish levels of quality (through technical targets or samples of acceptable materials), the means to identify and measure significant information present in the document, the means to relate one to another via a formula, and the means to judge results on-screen and in-print for a sample group of documents. Armed with this information, benchmarking enables informed decision making-which often leads to a balancing act involving tradeoffs between quality and cost, between quality and completeness, between completeness and size, or between quality and speed.
Display Benchmarking
Quality assessments can be extended beyond capture requirements to the presentation and timeliness of delivery options. We began our benchmarking for conversion with the attributes of the source documents. We begin our benchmarking for display with the attributes of the digital images.
I believe that all researchers in their heart of hearts expect three things from displayed digital images: (I) they want the full-size image to be presented onscreen; (2) they expect legibility and adequate color rendering; and (3) they want images to be displayed quickly. Of course they want lots of other things, too, such as the means to manipulate, annotate, and compare images, and for text-based material, they want to be able to conduct key word searches across the images. But for the moment, let's just consider those three requirements: full image, full detail and tonal reproduction, and quick display.
Unfortunately, for many categories of documents, satisfying all three criteria at
once will be a problem, given the limitations of screen design, computing capabilities, and network speeds. Benchmarking screen display must take all these variables into consideration and the attributes of the digital images themselves as user expectations are weighed one against the other. We are just beginning to investigate this interrelationship at Cornell, and although our findings are still tentative and not broadly confirmed through experimentation, I'm convinced that display benchmarking will offer the same advantages as conversion benchmarking to research institutions that are beginning to make their materials available electronically.[14]
Now for the good news: it is easy to display the complete image and it is possible to display it quickly. It is easy to ensure screen legibility-in fact, intensive scrutiny of highly detailed information is facilitated on-screen. Color fidelity is a little more difficult to deliver, but progress is occurring on that front.[15]
Now for the not-so-good news: given common desktop computer configurations, it may not be possible to deliver full 24-bit color to the screen-the monitor may have the native capability but not enough video memory, or its refresh rate cannot sustain a nonflickering image. The complete image that is quickly displayed may not be legible. A highly detailed image may take a long time to deliver, and only a small percent of it will be seen at any given time. You may call up a photograph of Yul Brynner only to discover you have landed somewhere on his bald pate.
Benchmarking will allow you to predict in advance the pros and cons of digital image display. Conflicts between legibility and completeness, between timeliness and detail, can be identified and compromises developed. Benchmarking allows you to predetermine a set process for delivering images of uniform size and content and to assess how well that process will accommodate other document types. Scaling to 72 dpi and adding 3 bits of gray may be a good choice for technical reports produced at 10-point type and above but will be totally inadequate for delivering digital renderings of full-size newspapers.
To illustrate benchmarking as it applies to display, consider the first two user expectations: complete display and legibility. We expect printed facsimiles produced from digital images to look very similar to the original. They should be the same size, preserve the layout, and convey detail and tonal information that is faithful to the original. Many readers assume that the digital image on-screen can also be the same, that if the page were correctly converted, it could be brought up at approximately the same size and with the same level of detail as the original. It is certainly possible to scale the image to be the same size as the original document, but most likely the information contained therein will not be legible.
If the scanned image's dpi does not equal the screen dpi, then the image onscreen will appear either larger or smaller than the original document's size. Because scanning dpi most often exceeds the screen dpi, the image will appear larger on the screen-and chances are that not all of it will be represented at once. This is because monitors have a limited number of pixels that can be displayed both
horizontally and vertically. If the number of pixels in the image exceeds those of the screen and if the scanning dpi is higher, the image will be enlarged on the screen and will not be completely presented.
The problems of presenting completeness, detail, and native size are more pronounced in on-screen display than in printing. In the latter, very high printing resolutions are possible, and the total number of dots that can be laid down for a given image is great, enabling the creation of facsimiles that are the same size- and often with the same detail-as the original.
The limited pixel dimensions and dpi of monitors can be both a strength and a weakness. On the plus side, detail can be presented more legibly and without the aid of a microscope, which, for those conducting extensive textual analysis, may represent a major improvement over reviewing the source documents themselves. For instance, papyrologists can rely on monitors to provide the enlarged view of fragment details required in their study. When the original documents themselves are examined, they are typically viewed under a microscope at 4 to 10 ³ magnification.[16] Art historians can zoom in on high-resolution images to enlarge details or to examine brush strokes that convey different surfaces and materials.[17] On the downside, because the screen dpi is often exceeded by the scanning dpi and because screens have very limited pixel dimensions, many documents cannot be fully displayed if legibility must be conveyed. This conflict between overall size and level of detail is most apparent when dealing with oversized material, but it also affects a surprisingly large percentage of normal-sized documents as well.
Consider the physical limitations of computer monitors: typical monitors offer resolutions from 640 ³ 480 at the low end to 1600 ³ 1200 at the high end. The lowest level SVGA monitor offers the possibility of displaying material at 1024 ³ 768. These numbers, known as the pixel matrix, refer to the number of horizontal by vertical pixels painted on the screen when an image appears.
In product literature, monitor resolutions are often given in dpi, which can range from 60 to 120 depending on the screen width and horizontal pixel dimension. The screen dpi can be a misleading representation of a monitor's quality and performance. For example, when SVGA resolution is used on a 14", 17", and 21" monitor, the screen dpi decreases as screen size increases. We might intuitively expect image resolution to increase, not decrease, with the size of the monitor. In reality, the same amount of an image-and level of detail-would be displayed on all three monitors set to the same pixel dimensions. The only difference would be that the image displayed on the 21" monitor would appear enlarged compared to the same image displayed on the 17" and 14" monitors.
The pixel matrix of a monitor limits the number of pixels of a digital image that can be displayed at any one time. And if there is insufficient video memory, you will also be limited to how much gray or color information can be supported at any pixel dimension. For instance, while the three-year-old 14" SVGA monitor on my desk supports a 1024 ³ 768 display resolution, it came bundled with half a
megabyte of video memory. It cannot display an 8-bit grayscale image at that resolution and it cannot display a 24-bit color image at all, even if it is set at the lowest resolution of 640 ³ 480. If I increased its VRAM, I would be bothered by an annoying flicker, because the monitor's refresh rate is not great enough to support a stable image on-screen at higher resolutions. It is not coincidental that while the most basic SVGA monitors can support a pixel matrix of 1024 ³ 768, most of them come packaged with the monitor set at a resolution of 800 ³ 600. As others have noted, network speeds and the limitations of graphical user interfaces will also profoundly affect user satisfaction with on-screen presentation of digital images.
So How Does Display Benchmarking Work?
Consider the brittle book and how best to display it. Recall that it may contain font sizes at 1 mm and above, so we have scanned each page at 600 dpi, bitonal mode. Let's assume that the typical page averages 4" ³ 6" in size. The pixel matrix of this image will be 4³ 600 by 6 ³ 600, or 2400 ³ 3600-far above any monitor pixel matrix currently available. Now if I want to display that image at its full scanning resolution on my monitor, set to the default resolution of 800 ³ 600, it should be obvious to many of you that I will be showing only a small portion of that image- approximately 5% of it will appear on the screen. Let's suppose I went out and purchased a $2,500 monitor that offered a resolution of 1600 ³ 1200. I'd still only be able to display less than a fourth of that image at any one time.
Obviously for most access purposes, this display would be unacceptable. It requires too much scrolling or zooming out to study the image. If it is an absolute requirement that the full image be displayed with all details fully rendered, I'd suggest converting only items whose smallest significant detail represents nothing smaller than one third of 1% of the total document surface. This means that if you had a document with a one-millimeter-high character that was scanned at 600 dpi and you wanted to display the full document at its scanning resolution on a 1024 ³ 768 monitor, the document's physical dimensions could not exceed 1.7" (horizontal) ³ 1.3" (vertical). This document size may work well for items such as papyri, which are relatively small, at least as they have survived to the present. It also works well for items that are physically large and contain large-sized features, such as posters that are meant to be viewed from a distance. If the smallest detail on the poster measured 1", the poster could be as large as 42" ³ 32" and still be fully displayed with all detail intact.[18]
Most images will have to be scaled down from their scanning resolutions for onscreen access, and this can occur a number of ways. Let's first consider full display on the monitor, and then consider legibility. In order to display the full image on a given monitor, the image pixel matrix must be reduced to fit within the monitor's pixel dimensions. The image is scaled by setting one of its pixel matrixes to the corresponding pixel dimension of the monitor.[19]
To fit the complete page image from our brittle book on a monitor set at 800 ³ 600, we would scale the vertical dimension of our image to 600; the horizontal dimension would be 400 to preserve the aspect ratio of the original. By reducing the 2400 ³ 3600 pixel image to 400 ³ 600, we will have discarded 97% of the information in the original. The advantages to doing this are several: it facilitates browsing by displaying the full image, and it decreases file size, which in turn decreases the transmission time. The downside should also be obvious. There will be a major decrease in image quality as a significant number of pixels are discarded. In other words, the image can be fully displayed, but the information contained in that image may not be legible. To determine whether that information will be useful, we can turn to the use of benchmarking formulas for legible display.
Here are the benchmarking resolution formulas for scaling bitonal and grayscale images for on-screen display:[20]
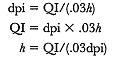
Note: Recall that in the benchmarking resolution formulas for conversion, dpi refers to the scanning resolution. In the scaling formulas, dpi refers to the image dpi (not to be confused with the monitor's dpi).
Let's return to the example of our 4" ³ 6" brittle page. If we assume that we need to be able to read the 1-mm-high character but that it doesn't have to be fully rendered, then we set our QI requirement at 3.6, which should ensure legibility of characters in context. We can use the benchmarking formula to predict the scaled image dpi:
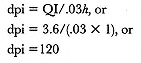
The image could be fully displayed with minimal legibility on a 120 dpi monitor. The pixel dimensions for the scaled image would be 120 ³ 4 by 120 ³ 6, or 480 ³ 720. This full image could be viewed on SVGA monitors set at 1024 ³ 768 or above; slightly more than 80% of it could be viewed on my monitor set at 800 ³ 600.
We can also use this formula to determine a preset scaling dpi for a group of documents to be conveyed to a particular clientele. Consider a scenario in which your primary users have access to monitors that can effectively support an 800 ³ 600 resolution. We could decide whether the user population would be satisfied with receiving only 80% of the document if it meant that they could read the smallest type, which may occur only in footnotes. If your users are more interested in quick browsing, you might want to benchmark against the body of the text
rather than the smallest typed character. For instance, if the main text were in 12-point type and the smallest lowercase e measured 1.6 mm in height, then our sample page could be sent to the screen with a QI of 3.6 at a pixel dimension of 300 ³ 450, or an image dpi of 75-well within the capabilities of the 800 ³ 600 monitor.
You can also benchmark the time it will take to deliver this image to the screen. If your clientele are connected via ethernet, this image (with 3 bits of gray added to smooth out rough edges of characters and improve legibility) could be sent to the desktop in less than a second-providing readers with full display of the document, legibility of the main text, and a timely delivery. If your readers are connected to the ethernet via a 9600-baud modem, however, the image will take 42 seconds to be delivered. If the footnotes must be readable, the full text cannot be displayed on-screen and the time it will take to retrieve the image will increase. Benchmarking allows you to identify these variables and consider the trade-offs or compromises associated with optimizing any one of them.
Conclusion
Benchmarking is an approach, not a prescription. It offers a means to evaluate choices for how best to balance quality, costs, timeliness, user requirements, and technological capabilities in the conversion, delivery, and presentation of digital resources. The value of this approach will best be determined by extensive field testing. We at Cornell are committed to further refinement of the benchmarking methodology, and we urge others to consider its utility before they commit considerable resources to bringing about the brave new world of digitized information.
Chapter 3—
The Transition to Electronic Content Licensing
The Institutional Context in 1997
Ann S. Okerson
Introduction
The public discourse about electronic publishing, as heard at scholarly and library gatherings on the topic of scholarly communications, has changed little over the past several years. Librarians and academics fret about the serials crisis, argue about the influence of commercial offshore publishers, wonder when the academic reward system will begin to take electronic publications into account, and debate what steps to take to rationalize copyright policy in our institutions. There is progress in that a wider community now comes together to ponder these familiar themes, but to those of us who have been party to the dialogue for some years, the tedium of ritual sometimes sets in.
At Yale, subject-specialist librarians talk to real publishers every day about the terms on which the library will acquire their electronic products: reference works, abstracts, data, journals, and other full-text offerings. Every week, or several times a week, we are swept up in negotiating the terms of licenses with producers whose works are needed by our students and faculty. Electronic publications are now a vital part of libraries' business and services. For example, at a NorthEast Research Libraries Consortium (NERL) meeting in February 1997, each of the 13 research library representatives at the table stated that his or her library is expending about 6-7% of its acquisitions budget on electronic resources.
This essay will offer some observations on the overall progress of library licensing negotiations. But the main point of this essay will be to make this case: in
ã 1999 by Ann Okerson. Readers of this article may copy it without the copyright owner's permission if the author and publisher are acknowledged in the copy and the copy is used for educational, not-for-profit purposes.
the real world of libraries, we have begun to move past the predictable, ritual discourse. The market has brought librarians and publishers together; the parties are discovering where their interests mesh; and they are beginning to build a new set of arrangements that meet needs both for access (on the part of the institution) and remuneration (on the part of the producer). Even though the prices for electronic resources are becoming a major concern, libraries are able to secure crucial and significant use terms via site licenses, use terms that often allow the customer's students, faculty, and scholars significant copying latitude for their work (including articles for reserves and course packs), at times more latitude than what is permitted via the fair use and library provisions in the Copyright Act of the United States. In short, institutions and publishers perhaps do not realize how advanced they are in making a digital market, more advanced at that, in fact, than they are at resolving a number of critical technological issues.[1]
Why do Contracts or Licenses (Rather Than Copyright) Govern Electronic Content?
Society now faces what seems to be a powerful competitor for copyright's influence over the marketplace of cultural products, one that carries its own assumptions about what intellectual property is, how it is to be used, how it can be controlled, and what economic order can emerge as a result.
For convenience's sake, the codification of intellectual property is assigned to the early eighteenth century. That time period is when the evolving notion of copyright was enacted into law, shaping a marketplace for cultural products unlike any seen before. In that eighteenth-century form, copyright legislation depended in three ways on the technologies of the time:
1. The power of copyright was already being affirmed through the development of high-speed printing presses that increased the printer's at-risk capital investment and greatly multiplied the number of copies of a given original that could be produced (and thus lowered the selling price).
2. An author could begin to realize financial rewards through signing over copyright to a publisher. Owning the copyright meant that the publisher, who had assumed the expense and risk of publication, stood to gain a substantial portion of the publication revenue.
3. Punishment for breaking the law (i.e., printing illegal copies) was feasible, for the ability to escape detection was relatively slight. The visibility and the capital costs of establishing and operating a printing press meant that those who used such presses to violate copyright were liable to confiscatory punishment at least commensurate with the injury done by the crime itself.
In the 1970s, technology advances produced the photocopier, an invention that empowered the user to produce multiple copies cheaply and comparatively unnoticed. In the 1980s, the fax machine took the world by storm, multiplying copies
and speeding up their distribution. Computer networking technology of the 1990s marries the convenience, affordability, and ease of distribution, eclipsing the power of all previous technologies. We can attribute the exponential increase in electronic content, at least indirectly, to the current inhabitants of the White House. The Clinton-Gore campaign of 1992 introduced the Internet to the general public, and this administration has been passionately committed to rapid development of the National Information Infrastructure (NII) and determined to advance the electronic marketplace. Part of that commitment arises from national leaders' unwavering faith that electronic networks create an environment and a set of instruments vital to the overall economic growth of the United States.
While copyright (that is, the notion that creative works can be owned) is still and probably always will be recognized as a fundamental principle by most players in the information chain, many believe that its currently articulated "rules" do not effectively address either the technical capabilities or reader needs of a high-speed information distribution age. It could be argued (and many educators do) that the nineteenth-and twentieth-century drafters of copyright law intended to lay down societally beneficial and, by extension, technologically neutral principles about intellectual property ownership and copying,[2] but in fact Thomas Jefferson knew nothing of photocopiers, and the legislators who crafted the 1976 Copyright Act of the United States knew nothing of computer networks. Had they even begun to imagine such things, the law might have been written differently-and in fact the case can be made that it should now be written differently.[3] So to many people, the gulf between copyright laws or treaties and the universe that those laws ought to address today feels vast and deep. Therefore, instead of relying on national copyright law, surrounding case law, international treaties, and prevailing practice to govern information transactions for electronic information, copyright holders have turned to contracts (or licenses, as they are more commonly called in the library world) as the mechanism for defining the owner, user, and uses of any given piece of information.
That is, the license-contract is invoked because the prospective deal is for both parties a substantial transaction (in cash or in consequence). The new atmosphere creates a new kind of marketplace or a market for a new kind of product, and neither the selling nor the buying parties are sure of the other or of their position visà-vis the law and the courts. Publishers come to the table with real anxieties that their products may be abused by promiscuous reproduction of a sort that ultimately saps their product's marketability, while libraries are fearful that restrictions on permitted uses will mean less usable or more expensive products.
In short, what licensing agreements have in common with the copyright regime is that both accept the fundamental idea of the nature of intellectual property-that even when intangible, it can be owned. Where they differ is in the vehicle by which they seek to balance creators', producers', and users' rights and to regulate the economy that springs up around those rights. Copyright represents a set of general regulations negotiated through statutory enactment. Licenses, on the
other hand, represent a market-driven approach to this regulation through deals struck between buyers and sellers.
When Did This Mode of Doing Business Begin for Libraries?
The concept of a license is old and fundamentally transparent. A license is essentially a means of providing use of a piece of property without giving up the ownership. For example, if you own a piece of property and allow another to use it without transferring title, you may, by law of contract, stipulate your conditions; if the other party agrees to them, then a mutually agreeable deal has come into being. A similar transaction takes place in the case of performance rights for films and recordings. This example moves from the tangible property mode of real estate, in which exclusive licenses (granting of rights to only one user) are common, to the intangible property mode of intellectual property such as copyright, in which nonexclusive licenses are the norm. The owner of a movie theater rarely owns the cans of film delivered weekly to the cinema, holding them instead under strict conditions of use: so many showings, so much payment for each ticket sold, and so on. With the right price such an arrangement, like the economic relationship between author and publisher that is sanctioned by copyright, can be extraordinarily fruitful. In the license mode of doing business (precisely defined by the legal contract that describes the license), the relationships are driven entirely by contract law: the owner of a piece of property is free to ask whatever price and set whatever conditions on use the market will bear. The ensuing deal is pure "marketplace" a meeting of minds between a willing buyer and a willing seller. A crucial point here is that the license becomes a particularly powerful tool for that property owner who has a copyright-protected monopoly.
Most academics began to be parties to license agreements when personal computer software (WordStar, WordPerfect) appeared in the 1980s in shrink-wrap packages for the first time. Some purchasers of such software may have read the fine print on the wrapper that detailed the terms and conditions of use, but most either did not or have ceased to do so. The thrust of such documents is simple: by opening the package the purchaser has agreed to certain terms, terms that include limited rights of ownership and use of the item paid for. In many ways, this mode of licensing raises problematic questions,[4] but in other ways, such as sheer efficiency, shrink-wrap licensing suggests the kind of transaction that the scholarly information marketplace needs to achieve. It is noteworthy that the shrink-wrap license has moved easily into the World Wide Web environment, where it shows itself in clickable "I agree" form. The user's click supposedly affirms that he or she has said yes to the user terms and is ready to abide by them. The downsides and benefits are similar to those of shrink-wrapped software.
The phenomenon of institutional licensing for electronic content has evolved in a short time. Over the past 20 years or so, the licensing of software has become a way of life for institutions of higher education. These kinds of licenses are gen-
erally for systems that run institutional computers or on-line catalogs or software packages (e.g., for instruction or for office support). The licenses, often substantial in scale and price, are arranged by institutional counsel (an increasingly overworked segment of an educational institution's professional staff) along with information technology managers.
Libraries' entrée into this arena has been comparatively recent and initially on a small scale. In fact, the initial library business encounter with electronic content may not have happened via license at all, but rather via deposit account. Some 20 years ago, academic and research libraries began accessing electronic information through mediated searching of indexing and abstracting services provided by consolidators such as Dialog. Different database owners levied different per hour charges (each database also required its own searching vocabularies and strategies), and Dialog (in this example) aggregated them for the educational customer. For the most part, libraries established accounts to which these searches (usually mediated by librarians or information specialists) were charged.
By the late 1980s, libraries also began to purchase shrink-wrapped (prelicensed) content, though shrink-wrapped purchases did not form-and still do not-any very visible part of library transactions. Concurrently, a number of indexing and abstracting services offered electronic versions directly to libraries via CD-ROM or through dial-up access (for example, an important early player in this arena was ISI, the Institute for Scientific Information). It was at this point, within the last ten years, that library licenses gradually became recognized as a means to a new and different sort of information acquisition or access. Such licenses were often arranged by library subject specialists for important resources in well-defined areas of use. The license terms offered to libraries were accepted or not, the library customer regarding them mostly as nonnegotiable. Nonacceptance was most often a matter of affordability, and there seemed to be little room for the library customer to affect the terms. Complaints about terms of licenses began to be (and persist in being) legion, for important reasons such as the following:
• Potential loss of knowledge. By definition, licenses are arranged for specific periods of time. At the end of that time, librarians rapidly discovered, if the license is not renewed, prior investment can become worthless as the access ceases (for example, where a CD-ROM must be returned or perhaps stops being able to read the information; or where connections to a remote server are severed).
• License restrictions on use and users. In order to reduce or curtail the leakage of electronic information, institutions are often asked to ensure that only members of the institution can use that information.,
• Limitations on users' rights. Initial license language not infrequently asks that institutional users severely limit what and how much they may copy from the information resource and may prescribe the means by which such copying can be done.
• Cost. In general, electronic licenses for indexing and abstracting services cost significantly more than print equivalents.[5]
What has happend to increase Libraries' Awareness of Licenses?
1. Sheer numbers have increased. Thousands of information providers have jumped into the scholarly marketplace with electronic products of one sort or another: CDs, on-line databases, full text resources, multimedia. Many scientific publishers, learned societies, university presses, full-text publishers, and vendor/aggregators, as well as new entrants to the publishing arena, now offer beta or well-tested versions of either print-originating or completely electronic information. The numbers have ballooned in a short two to three years, with no signs of abating. For example, Newfour, the on-line forum for announcing new e-journals, magazines, and newsletters, reports 3,634 titles in its archive as of April 5,1997, and this figure does not include the 1,100 science journal titles that Elsevier is now making available in electronic form.[6] The Yale University Library licenses more than 400 electronic resources of varying sizes, types, media, and price, and it reviews about two new electronic content licenses a week.
2. The attempt by various players in the information chain to create guidelines about electronic fair use has not so far proved fruitful. In connection with the Clinton Administration's National Information Infrastructure initiative, the Working Group on Intellectual Property Rights in the Electronic Environment called upon copyright stakeholders to negotiate guidelines for the fair use of electronic materials in a variety of nonprofit educational contexts. Anyone who wished to participate was invited to do so, and a large group calling itself CONFU, the Conference on Fair Use, began to negotiate such guidelines for a variety of activities (such as library reserves, multimedia in the classroom, interlibrary loans, etc.) in September 1997.[7] The interests of all participants in the information chain were represented, and the group quickly began to come unstuck in reaching agreements on most of the dozen or more areas defined as needing guidelines. Such stalemates should come as no surprise; in fact, they are healthy and proper. Any changes to national guidelines, let alone national law or international treaty, should happen only when the public debate has been extensive and consensus has been reached. What many have come to realize during the current licensing activities is that the license arrangements that libraries currently are making are in fact achieving legislation's business more quickly and by other means. Instead of waiting on Congress or CONFU and allowing terms to be dictated to both parties by law, publishers and institutions are starting to make their peace together, thoughtfully and responsibly, one step at a time. Crafting these agreements and relationships is altogether the most important achievement of the licensing environment.
3. Numerous formal partnerships and informal dialogues have been spawned by the capabilities of new publications technologies. A number of libraries collaborate with the publishing and vendor communities as product developers or testers. Such relationships are fruitful in multiple ways. They encourage friction, pushback, and conversation that lead to positive and productive outcomes. Libraries have been offered-and have greatly appreciated-the opportunity to discuss at length the library licenses of various producers, for example, JSTOR, and libraries feel they have had the opportunity to shape and influence these licenses with mutually satisfactory results.
4. Library consortia have aggressively entered the content negotiating arena. While library consortia have existed for decades and one of their primary aims has been effective information sharing, it is only in the 1990s (and mostly in the last two to three years) that a combination of additional state funding (for statewide consortia), library demands, and producers' willingness to negotiate with multiple institutions has come together to make the consortial license an efficient and perhaps cost-effective way to manage access to large bodies of electronic content. An example of a particularly fruitful marketplace encounter (with beautiful as well as charged moments) occurred from February 3 to 5, 1997, as a group of consortial leaders, directors, and coordinators who had communicated informally for a year or two through mailing list messages arranged a meeting at the University of Missouri-St. Louis. The Consortium of Consortia (COC, as we sweepingly named ourselves) invited a dozen major electronic content vendors to describe their products briefly and their consortial working arrangements in detail.[8] By every account, this encounter achieved an exceptional level of information swapping, interaction, and understandings, both of specific resources and of the needs of producers and customers. That said, the future of consortial licensing is no more certain than it is for individual library licenses, though for different reasons.[9]
5. Academia's best legal talent offers invaluable support to libraries. Libraries are indebted to the intelligent and outspoken lawyerly voices in institutions of higher learning in this country. The copyright specialists in universities' general counsel offices have, in a number of cases, led in negotiating content licenses for the institution and have shared their strategies and knowledge generously. Law school experts have published important articles, taught courses, contributed to Internet postings, and participated in national task forces where such matters are discussed.[10]
6. The library community has organized itself to understand the licensing environment for its constituents. The Association of Research Libraries (ARL) has produced an introductory licensing brochure,[11] the Council on Library Resources/Commission on Preservation and Access has supported Yale Library's creation of an important Web site about library content licensing,[12] and the Yale Library offers the library, publisher, vendor, and lawyer world
a high-quality, moderated, on-line list where the issues of libraries and producers are aired daily.[13]
7. Options are limited. Right now, licensing and contracts are the only way to obtain the increasing number of electronic information resources that library users need for their education and research.
Some notable challenges of the library licensing Environment Today
I identify these challenges because they are important and need to be addressed.
1. Terms of use. This area needs to be mentioned at the outset, as it has caused some of the most anguished discussions between publishers and libraries. Initially, many publishers' contract language for electronic information was highly restrictive about both permitted users and permitted uses. Assumptions and requirements about how use ought to be contained have been at times ludicrous, for example, in phrases such as "no copies may be made by any means electronic or mechanical." Through dialogue between librarians and producers, who are usually eager to market their work to happy customers, much of this language has disappeared from the first draft contracts presented to library customers. Where libraries are energetic and aggressive on behalf of their users, the terms of use can indeed be changed to facilitate educational and research goals. The Yale Library, for example, is now party to a number of licenses that permit substantial amounts of copying and downloading for research, individual learning, in-the-classroom learning, library reserves, course packs, and related activities. Interlibrary loan and transmission of works to individual scholars in other organizations are matters that still need a great deal of work. However, the licenses of 1996 and 1997 represent significant all-around improvements and surely reinforce the feeling that rapid progress is being made.
2. Scalability. Institutional electronic content licenses are now generally regarded as negotiable, mostly because the library-customer side of the marketplace is treating them as such (which publishers seem to welcome). Successes of different sorts have ensued (success being defined as a mutually agreeable contract), making all parties feel that they can work together effectively in this new mode. However, negotiations are labor intensive. Negotiation requires time (to develop the expertise and to negotiate), and time is a major cost. The current method of one-on-one negotiations between libraries and their publishers seems at the moment necessary, for many reasons, and at the same time it places new demands on institutional staff. Scalability is the biggest challenge for the licensing environment.
• Clearly, it is too early to shift the burden onto intermediaries such as subscription agencies or other vendors who have vested interests of their
own. So far their intervention has been absent or not particularly successful. In fact, in some of the situations in which intermediaries purvey electronic databases, library customers secure less advantageous use terms than those libraries could obtain by licensing directly from the publishers. This is because those vendors are securing commercial licenses from the producers whereas libraries are able to obtain educational licenses. Thus, it is no surprise that in unveiling their latest electronic products and services, important organizations such as Blackwell's (Navigator ) and OCLC (EFO-Electronic Fournals On-line ) leave license negotiating for the journal content as a matter between the individual journal publishers and their library customers.
• The contract that codifies the license terms is a pervasive document that covers every aspect of the library/producer relationship, from authorized uses and users to technology base, duration, security mechanisms, price, liability, responsibility, and so on. That is, the license describes the full dimensions of the "deal" for any resource. The library and educational communities, in their attempts to draft general principles or models to address content licensing, characteristically forget this important fact, and the results inevitably fall short in the scaling-up efforts.
3. Price. Pricing models for electronic information are in their infancy; they tend to be creative, complicated, and often hard to understand.[14] Some of these models can range from wacky to bizarre. Consortial pricing can be particularly complex. Each new model solves some of the equity or revenue problems associated with earlier models but introduces confusion of its own. While pricing of electronic resources is not, strictly speaking, a problem with the license itself, price has been a major obstacle in making electronic agreements. The seemingly high price tags for certain electronic resources leave the "serials crisis" in the dust.[15] It is clear that academic libraries, particularly through their consortial negotiators, expect bulk pricing arrangements, sliding scales, early signing bonuses, and other financial inducements that publishers may not necessarily feel they are able to offer. Some of the most fraught moments at the St. Louis COC meeting involved clashes between consortial representatives who affirmed that products should be priced at whatever a willing buyer can or will pay, even if this means widely inconsistent pricing by the vendor, and producers who affirmed the need to stick with a set price that enables them to meet their business plan.
4. The liability-trust conundrum. One of the most vexing issues for producers and their licensees has been the producers' assumption that institutions can and ought to vouch for the behavior of individual users (in licenses, the sections that deal with this matter are usually called "Authorized or Permitted Users" and what users may do under the terms of a license is called an "Authorized or Permitted Use") and the fact that individual users' abuses of the terms of
a license can kill the deal for a library or a whole group of libraries. Working through this matter with provider after provider in a partnership/cooperative approach poses many challenges. In fact, this matter may be a microcosm of a larger issue: the development of the kind of trust that must underlie any electronic content license. Generally the marketplace for goods is not thought of in terms of trust; it regarded as a cold cash (or virtual cash) transaction environment. Yet the kinds of scaled-up scholarly information licenses that libraries are engaging with now depend on mutual understanding and trust in a way not needed for the standard trade-or even the print-market to work. In negotiating electronic content licenses, publishers must trust-and, given the opening up of user/use language, it seems they are coming to trust-their library customers to live up to the terms of the deal.
In part, we currently rely on licenses because publishers do not trust users to respect their property and because libraries are fretful that publishers will seek to use the new media to tilt the economic balance in their favor. Both fears are probably overplayed. If libraries continue to find, as they are beginning to do, that publishers are willing to give the same or even more copying rights via licenses as copyright oners, both parties may not be far from discovering that fears have abated, trust has grown, and the ability to revert to copyright as the primary assurance of trust can therefore increase. But many further technological winds must blow-for example, the cybercash facility to allow micropayment transactions-before the players may be ready to settle down to such a new equilibrium.
5. The aggregator aggravation (and opportunity). The costly technological investments that producers need to make to move their publications onto an electronic base; the publishing processes that are being massively reconceived and reorganized; and not least, the compelling vision of digital libraries that proffer information to the end user through a single or small number of interfaces, with a single or modest number of search engines, give rise to information aggregators of many sorts:[16] those who develop important searching, indexing, and/or display softwares (Alta Vista, OpenText, etc.); those who provide an interface or gateway to products (Blackwell's, etc.); and those who do all that plus offer to deliver the information (DIALOG @CARL, OCLC, etc.). Few publishers convert or create just one journal or publication in an electronic format. From the viewpoint of academic research libraries, it appears that the electronic environment has the effect of shifting transaction emphasis from single titles to collections or aggregations of electronic materials as marketplace products.
In turn, licensing collections from aggregators makes libraries dependent on publishers and vendors for services in a brand new way. That is, libraries' original expectation for electronic publications, no more than five years ago, was that publishers would provide the data and the subscribing library or
groups of libraries would mount and make content available. But mounting and integrating electronic information requires a great deal of capital, effort, and technological sophistication as well as multiple licenses for software and content. Thus, the prognosis for institutions meeting all or most of their users' electronic information needs locally is slim. The currently emerging mode, thus, takes us to a very different world in which publishers have positioned themselves to be the electronic information providers of the moment.[17]
The electronic collections offered to the academic library marketplace are frequently not in configurations that librarians would have chosen for their institutions had these resources been unbundled. This issue has surfaced in several of Yale Library's negotiations. For example, one publisher of a large number of high-quality journals made only the full collection available in e-form and only through consortial sale. By this means, the Yale Library recently "added" 50 electronic journal titles to its cohort, titles it had not chosen to purchase in print. The pricing model did not include a cost for those additional 50 titles; it was simply easier for the publisher to include all titles than to exclude the less desirable ones. While this forum is not the place to explore this particular kind of scaling up of commercial digital collections, it is a topic of potentially great impact on the academic library world.
6. The challenge of consortial dealings. Ideally, groups of libraries acting in consort to license electronic resources can negotiate powerfully for usage terms and prices with producers. In practice, both licensors and licensees have much to learn about how to approach this scaled-up environment. Here are some of the particularly vexing issues:
• Not all producers are willing to negotiate with all consortia; some are not able to negotiate with consortia at all.
• In the early days of making a consortial agreement, the libraries may not achieve any efficiencies because all of them (and their institutional counsel) may feel the need or desire to participate in the negotiating process. Thus, in fact, a license for 12 institutions may take nearly as long to negotiate as 12 separate licenses.
• Consortia overlap greatly, particularly with existing bodies such as cataloging and lending utilities that are offering consortial deals to their members. It seems that every library is in several consortia these days, and many of us are experiencing a competition for our business from several different consortia at once for a single product's license.
• No one is sure precisely what comprises a consortial "good deal." That is, it is hard to define and measure success. The bases for comparison between individual institutional and multiple institutional prices are thin, and the stated savings can often feel like a sales pitch.
• Small institutions are more likely to be unaffiliated with large or powerful institutions and left out of seemingly "good deals" secured by the larger, more prosperous libraries. Surprisingly enough, private schools can be at a disadvantage since they are generally not part of state-established and funded consortial groups.
• In fact, treating individual libraries differently from collectives may, in the long run, not be in the interests of publishers or those libraries.
7. Institutional workflow restructuring. How to absorb the additional licensing work (and create the necessary expertise) within educational institutions is a challenge. I can foresee a time when certain kinds of institutional licenses (electronic journals, for example) might offer standard, signable language, for surely producers are in the same scaling-up bind that libraries are. At the moment, licenses are negotiated in various departments and offices of universities and libraries. Many universities require that license negotiation, or at least a review and signature, happen through the office of general counsel and sometimes over the signature of the purchasing department. In such circumstances, the best result is delay; the worst is that the library may not secure the terms it deems most important. Other institutions delegate the negotiating and signing to library officers who have an appropriate level of responsibility and accountability for this type of legal contract. Most likely the initial contact between the library and the electronic provider involves the public service or collections librarians who are most interested in bringing the resource to campus.
One way of sharing the workload is to make sure that all selector staff receive formal or informal training in the basics and purposes of electronic licenses, so that they can see the negotiations through as far as possible and leave only the final review and approval to those with signing authority.[18] In some libraries, the licensing effort is coordinated from the acquisitions or serials departments, the rationale being that this is where purchase orders are cut and funds released for payment. However, such an arrangement can have the effect of removing the publisher interaction from the library staff best positioned to understand a given resource and the needs of the library readers who will be using it. Whatever the delegation of duties may be at any given institution, it is clear that the tasks must be carved out in a sensible fashion, for it will be a long time before the act of licensing electronic content becomes transparent. Clearly, this new means of working is not the "old" acquisitions model. How does everyone in an institution who should be involved in crafting licensing "deals" get a share of the action?
Succeeding (Not Just Coping)
On the positive side, both individual libraries and consortia of libraries have reported negotiating electronic content licenses with a number of publishers who
have been particularly understanding of research library needs. In general, academic publishers are proving to be willing to give and take on license language and terms, provided that the licensees know what terms are important to them. In many cases, librarians ask that the publisher reinstate the "public good" clauses of the Copyright Act into the electronic content license, allowing fair use copying or downloading, interlibrary loan, and archiving for the institutional licensee and its customers. Consortial negotiations are having a highly positive impact on the usefulness and quality of licenses.
While several downsides to the rapidly growing licensing environment have been mentioned, the greatest difficulty at this point is caused by the proliferation of licenses that land on the desks of librarians, university counsel, and purchasing officers. The answers to this workload conundrum might lie in several directions.
1. National or association support. National organizations such as ARL and the Council on Library and Information Resources (CLIR) are doing a great deal to educate as many people as possible about licensing. Practicing librarians treasure that support and ask that licensing continue to be part of strategic and funding plans. For example, the Yale Library has proposed next-step ideas for the World Wide Web Liblicense project. Under discussion are such possibilities as: further development of a prototype licensing software that will enable librarians to create licenses on the fly, via the World Wide Web, for presentation to producers and vendors as a negotiating position;[19] and assembling a working group meeting that involves publisher representatives in order to explore how many pieces of an academic electronic content are amenable to standardization. Clearly, academic libraries are working with the same producers to license the same core of products over and over again. It might be valuable for the ARL and other organizations to hire a negotiator to develop acceptable language for certain key producers-say the top 100-with the result that individual libraries would not need to work out this language numerous times. Pricing and technology issues, among others, might nonetheless need to remain as items for local negotiation.
2. Aggregators. As libraries, vendors, and producers become more skilled as aggregators, the scaling issues will abate somewhat. Three aggregating directions are emerging:
• Information bundlers, such as Lexis-Nexis, OCLC, UMI, IAC, OVID, and a number of others offer large collections of materials to libraries under license. Some of these are sizeable take-it-or-leave-it groupings; others allow libraries to choose subsets or groups of titles.
• Subscription agents are beginning to develop gateways to electronic resources and to offer to manage libraries' licensing needs.
• Consortia of libraries can be considered as aggregators of library customers for publishers.
3. Transactional licensing. This paper treats only institutional licenses, be they site licenses, simultaneous user/port licenses, or single-user types. An increasing number of library transactions demand rights clearance for a piece at a time (situations that involve, say, course reserves or provision of articles that are not held in the library through a document supplier such as CARL). Mechanisms for easy or automatic rights clearance are of surpassing importance, and various entities are applying considerable energies to them. The academic library community has been skittish about embracing the services of rights management or licensing organizations, arguing that participation would abrogate fair use rights. It seems important, particularly in light of recent court decisions, that libraries pay close attention to their position vis-àvis individual copies (when they are covered by fair use and when they are not, particularly in the electronic environment) and take the lead in crafting appropriate and fair arrangements to simplify the payment of fees in circumstances when such fees are necessary.[20]
Beyond the license?
As we have seen, the content license comes into play when the producer of an electronic resource seeks to define a "deal" and an income stream to support the creation and distribution of the content. Yet other kinds of arrangements are possible.
1. Unrestricted and for free. Some important resources are funded up front by, for example, governments or institutions, and the resources are available to all end users. Examples include the notable Los Alamos High Energy Physics Preprints; the various large genome databases; the recent announcement by the National Institutes of Health of MEDLNE's availability on-line; and numerous university-based electronic scholarly journals or databases. The number of such important resources is growing, though they may always be in the minority of scholarly resources. Characteristically, such information is widely accessible, the restrictions on use are minimal or nonexistent, and license negotiations are largely irrelevant or very straightforward.
2. For a subscription fee and unrestricted to subscribers. Some producers are, in fact, charging an on-line subscription fee but licenses need not be crafted or signed. The terms of use are clearly stated and generous. The most significant and prominent example of such not-licensed but paid-for resources is the rapidly growing collection of high-impact scientific and medical society journals published by Stanford University's HighWire Press.[21]
Both of these trends are important; they bear watching and deserve to be nurtured. In the first case, the up-front funding model seems to very well serve the needs of large scientific or academic communities without directly charging users or institutions; the databases are products of public- or university-funded re-
search. In the second instance, although users are paying for access to the databases, the gap between the copyright and licensed way of doing business seems to have narrowed, and in fact the HighWire publications are treated as if copyrightgoverned. Over time, it would not be unreasonable to expect this kind of merger of the two constructs (copyright and contract) and to benefit from the subsequent simplification that the merger would bring.
In short, much is still to be learned in the content licensing environment, but much has been learned already. We are in a period of experimentation and exploration. All the players have real fears about the security of their livelihood and mission; all are vulnerable to the risks of information in new technologies; many are learning to work together pragmatically toward at least midterm modest solutions and are, in turn, using those modest solutions as stepping-stones into the future.