APPENDIX A—
QUANTITATIVE SURVEY OF MOUVANCE
The material in this Appendix is provided in support of claims made in Chapters 4 and 5. The computerized analysis of statistics primarily serves as the basis for Chapter 4; the analysis of stanzaic linkage is of interest for Chapter 5. Fuller interpretations of the results are given in those chapters.
For each of the poets surveyed, a large mass of data was tabulated. Looking at the way these indices show the quantity and manuscript quality of surviving works attributed to him, we develop a profile of each troubadour. From that point, we can compare the artists in terms of their popularity in the transmitting traditions, their susceptibility to version production, their usage of linked stanzas, and the success of their poems in resisting transposition. The list below explains each index and abbreviation.
Components of Each Poet's Data Profile
The following abbreviations are used for raw data:
|
|
The following abbreviations are used for indices derived from the raw data:
|
|
Compilation of Data
The primary data were compiled manually rather than mechanically. No available machine can conveniently count poems, determine whether or not there is more than one stanzaic sequence in a poem, and analyze the rhyme scheme to decide whether stanzas are "linked" or not. Decisions had to be made during the tabulation; thus, an account of my criteria is needed.
First, in making the poem counts (P, P+), I eliminated any poems that were immune from transposition by virtue of their brevity. Since the first stanza is always stable, I did not count any poems with fewer than three stanzas extant. Usually such poems exist in only one manuscript anyway, or their editors mark them "coblas" and take them as incomplete works. Manuscript copies with three stanzas or fewer were also discounted when they appeared in certain chansonniers designed to present only "coblas"—selections from favorite poems. The compilers of these collections had no intention of offering a whole poem but rather only an estrat (extract; see discussion of Ferrari de Ferrara, Chapter 2).
The Transposition Count (T) literally records as having produced "versions" only those poems that exhibit more than one stanzaic sequence. This is the "narrow definition" of "version." I stayed with the criterion of "transposition" so strictly that a separate "version" would not register if a stanza were omitted in the middle of the poem or, as much more frequently occurs, at the end. For example, in a hypothetical poem where the sequences are as follows, there was no transposition (T = "no" = 0) and the number of "sequentially distinct versions" was recorded as "1" (V = 1):
ABDE 1 2 3 4 5
C 1 2 4 5
FGHIK 1 2 3 4
Similarly, poems with "fractured strophes," if the fractured strophe did contain lines from the "standard" strophe for its position, were not counted as having extra "versions, narrowly defined."
By the broader definition of "version," the poem just cited would count as having three different "stanzaic arrays." Thus, it would contribute to its author's data profile the following scores: A = "yes" = 1; W = 3.
A source of uncertainty in the data is that the editions used probably vary in the reliability with which they present the reformation tabulated here. I used the best editions available to me; they range in date from 1909 to 1986, and editorial styles change. A poet's canon may be redefined; more manuscript copies may be discovered or simply used for the first time. Some early editors were able to use only manuscripts that were geographically convenient for them to consult. Modern editors have access to microfilm copies of all the chansonniers . Some of the data for Bertran de Born changed, for example, when I was revising this book and switched from the Stimming edition to the new one by Paden, Sankovitch, and Stäblein: his transposition rate (TR) rose from 56 percent to 66 percent, his popularity (MS) rose, and the percentage of poems with linked stanzas (L) rose. Newer editions are not always "better" for this kind of analysis, however; for my statistical purposes I needed data that some excellent newer editions omitted. For example, despite the high quality of Riquer's 1971 edition of Guilhem de Berguedà, I had to omit that poet from my survey because no information on stanzaic sequence was provided. Some of the recent Italian editions of troubadour poets presented the same problem. The tables and charts that follow this discussion are offered as documentation for generalizations made elsewhere. I provide them to assure the reader that my results can be duplicated.
Statistical Analysis
Once the data were gathered, we used a statistical analysis package (SAS) to determine which variables were correlated with one another, and to
what degree. The results fall into three groups of correlations: those tied to manuscript survival, those connected with quantifiable formal properties of the poetry (stanza length and linkage), and those related to chronology. Full interpretations of these correlations are presented in Chapter 4. Here, I wish only to make available to the reader the statistical documentation of conclusions presented in Chapter 4 and to offer visual illustrations, through the graphs, of the relative "weakness" and "strength" of correlations discussed.
The correlation matrices (Tables A-3-A-4 below) show two numbers for each pair of variables. The top number (two decimal places) is the correlation coefficient. It measures the strength of the linear relationship between the two variables, that is, how closely the various points, when plotted, fit the model of a straight line. The bottom number (four decimal places) represents the so-called significance level. This term should have been named the "in significance level," since the number actually increases as significance decreases. The smaller the number, the stronger the correlation: the significance level estimates the "probability of the null hypothesis," that is, the likelihood that the data could have come from a larger mass of data with no real trend at all, from "a no-slope population." Thus, the highest numbers among the correlation coefficients and the smallest numbers among the significance levels indicate the strongest and most trustworthy correlations.
For each pair of highly related variables, with a correlation coefficient of at least .4 or a significance level of .05 or better (i.e., or less ), we made the computer plot a graphic representation of the data. In a few cases 1 have presented fainter correlations because useful information could be gained either from the absence of a correlation or from a slight one. Conversely, numerous high-correlation graphs have been omitted because they were redundant with the information given in those chosen for presentation.
Each graph also shows, beneath the correlation coefficient and significance level, an equation in the form: Y = m(X) + b. This equation tells exactly how to plot the trend line on a graph, showing the line's "slope" and "intercept." In the generalized equation just given, b represents the point at which the trend line intercepts the X-axis; the m(X) part of the equation shows how steeply the line rises, by showing the normative proportions of X to Y . If m is a negative number, the line will drop from left to right and the two variables will be inversely correlated.
Factors in Transmission: Circulation and Stability
Correlations with Manuscript Survival
When we look to the interrelations of numerical counts (primary variables M, P, T, A, V, W, L), it emerges that the single most "influential" variable was the number of extant manuscript copies of each poet's work (M).
The number of poems preserved under a given poet's name bears a strikingly constant relation to the number of manuscript copies of poems attributed to him (Fig. A-1). Further, the relationship of manuscript copies to transpositions is even more constant (Fig. A-3), and the proportion of manuscripts to arrays (including abridgments as well as transpositions) more constant still (Fig. A-2).
Version production can thus be said to "depend" almost totally on the circulation of a given poet's work. Otherwise the creation of new versions—whether we take "version" to refer only to stanzaic transposition or count also abridgments—would not be distributed so democratically among poets who vary widely in their beliefs about textual integrity, their stance with respect to literacy, their habits and styles of versification.
The more manuscript copies of a poet's works survive, the more likely is a given poem to survive with more than one arrangement of stanzas. The more times a poet's songs were transmitted, the greater number of his songs "moved." The more instances of transmission, the more instances of version production. A sequentially distinct version was created about once in every five manuscripts;[1] a distinct stanzaic array (by the "broad definition of version") occurs about once in every three manuscripts.[2] The unusually stable poets, "nonconformists" on the stable side of the trend line (Fig. A-3), are Guilhem de St-Didier, Raimbaut d'Aurenga, Folquet de Marselha, and Giraut de Bornelh; "nonconformists" on the unstable side are Bernart de Ventadorn, Bertran de Born, and Raimon de Miraval.
Stanzaic Transposition and Abridgment
Each poet has about 1.4 times as many poems showing alteration of the stanzaic array as poems showing transposition (Fig. A-4). For the kind of mouvance documented here—alteration in the series of stanzas—"versions" broadly defined are distinguished by about 40 percent abridgment and 60 percent sequence.[3] For every poem showing transposition,
there are 4.36 sequentially distinct versions.[4] For every poem showing more than one stanzaic array (including abridgments as well as transpositions), there are 4.46 different stanzaic arrays.[5]
From Figure A-5, we can tell which poets had more trouble with transposition and which ones suffered more from abridgment, compared with the norm drawn by the trend line. Giraut de Bornelh, Raimbaut d'Aurenga, Marcabru, and Guilhem de St-Didier undergo relatively little transposition; their songs were more often abridged than their sequence of stanzas transposed. Conversely, Arnaut de Mareuil, Bertran de Born, Berenguer de Palazol, and Bernart de Ventadorn more often had stanzas transposed than abridged.[6]
Thus, the primary indices all point to regular increases in mouvance in proportion to manuscript survival. When we look to the relationships among derived indices, we find a similar situation. The more manuscripts per poem, the more versions per poem were produced and the higher the percentage of poems that underwent transposition (Fig. A-5).
Assuming that the number of extant copies reflects frequency of performance and/or of transcription, we can say that a "popular" or oft-repeated poem not only was more likely than others to develop stanzaic shifting during transmission (MS vs. TR, Fig. A-5), but also was likely to develop more shifting .[7]
In quantity and quality, manuscript survival "should" reflect both a conservative element and an innovative element, if it reflects both written and oral transmission. These data show conclusively that innovation, as a concomitant of popularity, far outweighs the conservatism expected either from familiarity or from literalism, whether from singers or from copyists.
Correlations with Poem Survival (P)
That the incidence of transposition correlates better with the number of manuscripts of a given poet's work (M) than with the number of his poems (P) supports the idea that popularity and circulation, not productivity, were the governing factors. The only primary indices that correlate better with "Poems" than with "Manuscripts" are the counts of "Poems showing alternate arrays" (A) and of "Poems using linked stanzas" (L).[8]
The trends of correlation with poem survival offer precise information about extremely regular patterns of version production per poem. Poets surveyed conform surprisingly well to the trend for about 42 percent of poems to show transposition (T vs. P),[9] even given that one of our initial
"burning questions" was bow to explain variations in the ratios of T to P (T/P = TR, "Percent showing transposition").
Visibly much closer statistical conformity appears, however, in the fact that about 75 percent of each poet's songs show alternate stanzaic arrays, whether these consist of abridgments, transpositions, or both (A vs. P).[10] With a correlation coefficient of .98, this pattern of version production seems almost inhuman in its regularity. Other factors do not disrupt it in the least—neither chronological progress of any sort nor stylistic variations among the poets made any impact at all on the trend: three poems out of four will show some alteration in stanzaic array. Only one in four will be left "intact" (bearing in mind, of course, that "intactness" of stanzaic arrays far from guarantees "intactness" at the level of lines and word choice). This last figure, that only 25 percent of songs were transmitted "intact," is remarkable given that over 12 percent (68/552) of songs surveyed exist in only one manuscript and therefore can have only one stanzaic array. This means that only 13 percent of the songs surveyed show the same stanzaic array in two or more manuscripts.
V vs. P and W vs. P show the number of actual versions, by each definition, per poem. The number of sequentially distinct versions is approximately twice the number of poems (which means that most poets average two sequences per poem).[11] Stanzaic arrays, including abridgments, are about three nines the number of poems (W vs. P: most poets average roughly three "broadly defined versions" per poem).[12] The regularity of these correlations may help to explain why the index VP, "Versions per poem," failed to produce many significant correlations: it was too "flat," with few poets deviating far from the ratio of 2: 1, two versions per poem.
The number of poems showing stanzaic linkage (L) is much more loosely related to the total number of poems (P). Here, the stylistic character of individual poets affects the statistics dramatically. We still see a correlation coefficient of .64, indicating that the transmitters did tend to preserve a certain proportion of linked-stanza poems in each poet's canon, but the "scatter" on the graph of L vs. P (Fig. A-11) makes visible the fact that some poets preferred to use stanzaic linkage while others avoided it. Since L is a subset of P, it makes sense that the number of poems using linked stanzas should maintain a relatively constant proportion to the number of poems. Figure A-11 will be discussed in greater depth under the discussion of stanzaic linkage.
Correlations with Chronology
The temporal index used (Y for "Year") did not correlate at all with my initial index of mouvance, TR, the percentage of each poet's works showing transposition (Fig. A-6). It did, however, correlate with mouvance indices tied to manuscript survival rather than to poem survival: with "Sequentially distinct versions per manuscript" (VM) and "Stanzaic arrays per manuscript" (WM) (Fig. A-7). This trend is more pronounced in the production of versions by the broad definition including abridgment (with WM) than by the narrow definition including transpositions only (VM). Possibly the phenomenon of abridgment is more closely related to the growth of the book culture than is the phenomenon of stanzaic transposition; but see Chapter 4 for an in-depth discussion of Figure A-7.
Further, the chronological trend to fewer versions per manuscript is more pronounced in poems with unlinked stanzas than in the general body of poetry, and it scarcely exists as a trend at all for poems with linked stanzas.
In regard to changes in the formal properties of troubadour lyric, I confirmed that stanza length did gradually increase over time (Fig. A-8, Z vs. Y) at the rate of about two additional lines per hundred years. Nevertheless, as the "scatter" of that graph indicates, many early poets composed long stanzas and many later poets composed short ones.
Of particular interest (though the correlation is among the weakest that qualify as significant) is that the use of linked stanzas tended to drop over time. Figure A-9 illustrates this rather "scattered" trend. The actual "course of literary history" can be seen more sharply in Figure A-12, where we can see distinct "clusters" of poets. The earliest groups (1098–1158 and 1115–179) used stanzaic linkage heavily, perhaps increasingly. Then 1180–1195 marks a "reactionary" period in which stanzaic linkage was seldom used, even though poets in this group created some of the most memorable poetic forms with stanzaic linkage. Later (1205–1248), poets returned to composing 20–25 percent of their poems in forms with stanzaic linkage.
Correlations with Stanza Length
Stanza length proved valuable in the overall stability of a poet's works. It correlated very significantly with versions per manuscript by all definitions—with VM, VMa, and WM (see Fig. A-10). This means that gen-
erally, the longer the stanza, the more instances of transmission it requires to create a transposition or an abridgment.
The tendency toward an increase in stanza length over time (Fig. A-8) has been discussed. Now that we can see longer stanzas as a stabilizing feature, we can see how their increased use may have contributed to the historical decrease in version production shown in Figure A-7.
A positive correlation of stanza length and manuscript survival (M vs. Z) means that performers and copyists did not shy away from poets who used long, perhaps involved, stanza patterns. On the contrary, this feature seems to encourage retransmission.
Correlations with Stanzaic Linkage
Figure A-11 gives us a better picture than would a mere tally of how frequently poets use stanzaic linkage, because it provides a more accurate description of the norm. Filtering out differences caused by the varying sizes of the poets' bodies of works, we can see which ones are unusually favorable to stanzaic linkage and which ones are unfavorable. Poets decidedly favoring stanzaic linkage are Marcabru, Bernart de Ventadorn, Raimbaut d'Aurenga, Guillhem de St-Didier, Pons de la Guardia, and Raimon de Miraval. Poets decidedly rejecting stanzaic linkage are Berenguer de Palazol, Aimeric de Belenoi, Arnaut de Mareuil, Arnaut Daniel, Peire Vidal, Bertran de Born, and Giraut de Bornelh. Note that some of these last were the inventors of new and foolproof rhyme schemes.
The higher the percentage of linked stanzas, the more transpositions per manuscript (Fig. A-12). If anything, the habitual use of linked stanzas contributes to instability, even in the stanza-linked poems![13] The performer or scribe knows that such-and-such a poet uses linked stanzas frequently, yet even though confronted with a stanza-linked poem he transposes the stanzas anyway.
In looking at Figure A-12 (LK+ vs. VMa), one can see that linkage correlates overall with instability. The circled areas identifying chronologically close clusters of poets, however, show a fascinating phenomenon. The first historical group, roughly 1098–1158, uses stanzaic linkage heavily "to no avail"—it does not help them a bit in discouraging stanzaic transposition. The second group, 1115–1179, uses stanzaic linkage even more heavily and much more "successfully": version production drops dramatically for these poets, including Rigaut de Berbezilh, Bernart de Ventadorn, Raimbaut d'Aurenga, and Guilhem de St-Didier. The third group, 1180–1195, manages to keep version pro-
duction low while dramatically curtailing the use of stanzaic linkage. Finally, a fourth group (1205–1248) returns to moderate stanzaic linkage, without increasing version production in the process.
The Graphs
How to Read the Graphs
Some of the labeling of the graphs has necessarily taken the form of abbreviations. Decoding these abbreviations consists mainly of understanding (1) the abbreviations for variables compared statistically (the captions on the graphs indicate the names of the variables; full explanations of each variable are given in the introduction to this appendix under "Explanation of Data Indices"); (2) the numbers representing "data points" (each number refers to a specific poet, each of whom retains the same "code number" throughout the survey); and (3) the statistical information given with each graph (the letter r represents the correlation coefficient; the "significance level" appears below it; and the equation below that describes the "slope and intercept" of the trend line).
Key to Poets: Abbreviations and Code Numbers
The numbers assigned to each poet are in approximate chronological order; they are the same as in Tables A-1 and A-2, which give the "Data Profile" of each poet.
|
|
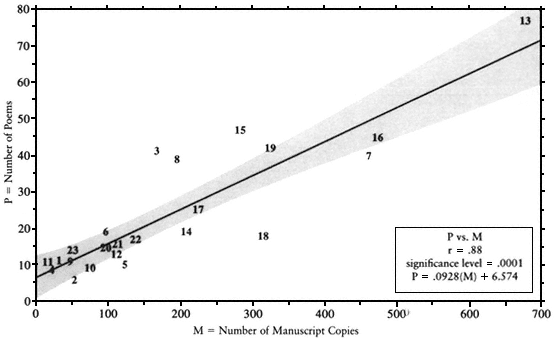
Fig. A-1.
Number of Poems versus Number of Manuscript Copies. Consistently, the more manuscript copies
of a given poet's work survive, the greater the number of his surviving poems.
Note: Numbered points on each graph correspond to individual poets; see "Key to Poets,"
pp. 223–224. Shaded areas show 95 percent confidence bands.
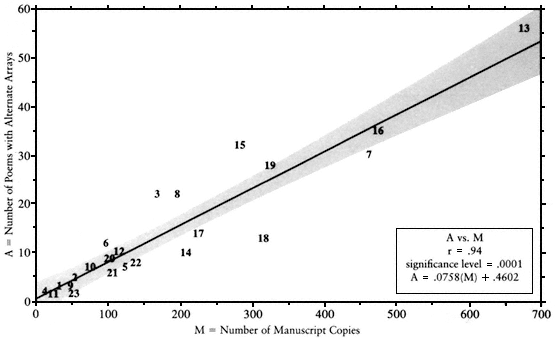
Fig. A-2.
Poems with Alternate Stanzaic Arrays versus Number of Manuscript Copies. The number of poems showing
more than one stanzaic array is consistently proportional to the number of extant manuscript copies.
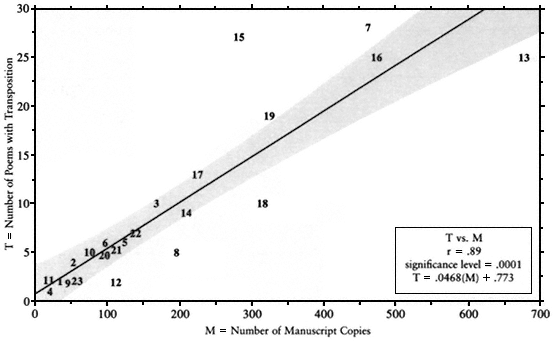
Fig. A-3.
Poems with Transposition versus Number of Manuscript Copies. The number of poems showing transposition,
within a given poet's works, is consistently proportional to the number of extant manuscript copies of his works.
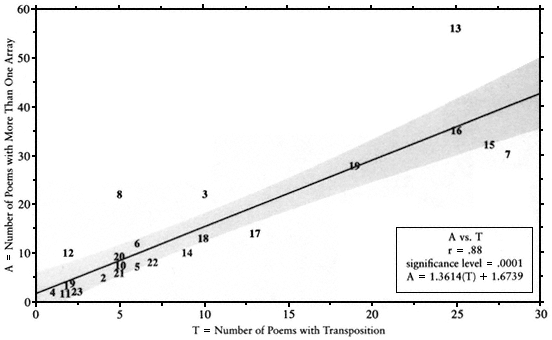
Fig. A-4.
Poems with More Than One Array versus Poems with Transposition. The number of poems showing more
than one stanzaic array will predictably be about 1.3 times the number of poems showing transposition only (plus 1.7).
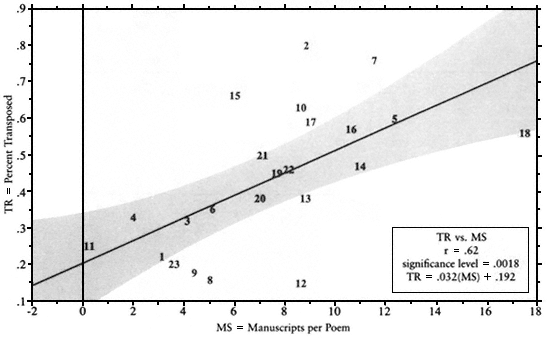
Fig. A-5.
Percent Transposed versus Manuscript per Poem. The rate at which transposition affects a poet's work
increases with the circulation of his works.
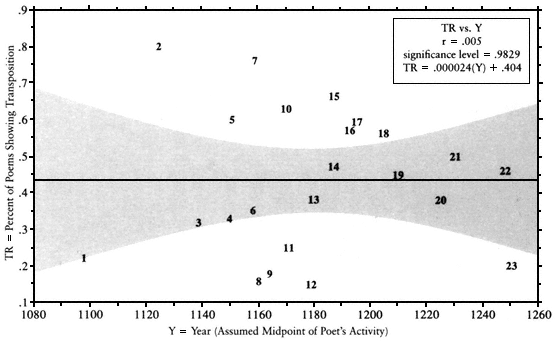
Fig. A-6.
Percent Transposed versus Year Random scatter and no slope: there is no chronological trend whatever
toward an increase or decrease in the percentage of poets' works showing transposition.
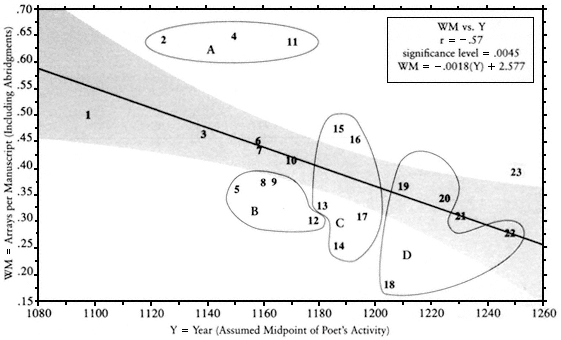
Fig. A-7.
Arrays per Manuscript versus Year. There was a chronological trend to produce fewer stanzaic arrays per
manuscript. Four clusters show the relationship of array production with the poets' use of linked stanzas (LK+) and
stanza length (Z).
Notes To Clusters:
A: Early poets with heavy use of stanzaic linkage and short stanzas (i.e., high LK+ and low Z) show abnormally high
version production.
B: Third-generation poets with heavy use of stanzaic linkage and normal stanza length showing low version production.
C: Middle poets with very low use of stanzaic linkage: those with short stanzas show above-average version production,
while those using long stanzas show lower version production.
D: Later poets with good stability showing moderate to high use of stanzaic linkage and medium to long stanza length.
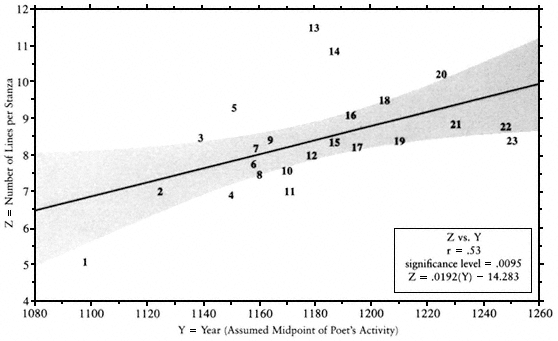
Fig. A-8.
Stanza Length versus Year. As time passed, there was a distinct tendency to compose longer stanzas.
The increase averages only about two lines per stanza per hundred years.
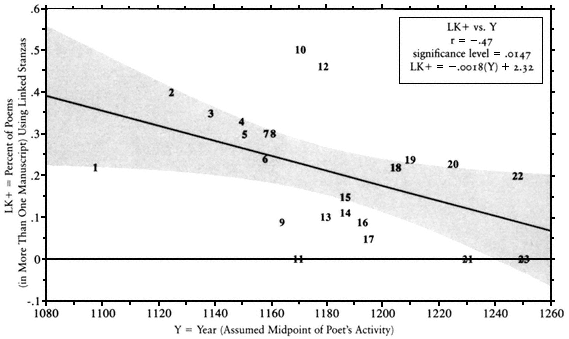
Fig A-9.
Use of Linked Stanzas versus Year. Later poets tend to use linked stanzas in a smaller percentage of surviving
songs than do earlier poets Poets numbered 13–17 show a turning away from stanzaic linkage around 1180–1195,
followed by a return to moderate use (poets 18–20, 22).
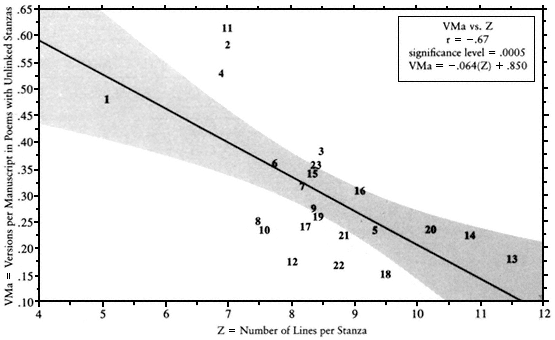
Fig. A-10.
Versions per Manuscript (Unlinked) versus Stanza Length. The longer the stanzas, the fewer versions per
manuscript—especially in poems with unlinked stanzas.
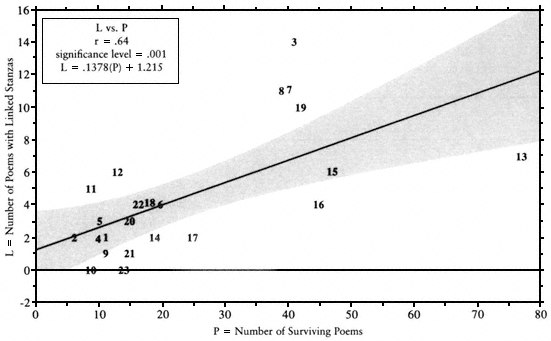
Fig. A-11.
Poems with Linked Stanzas versus Total Number of Poems. Generally, we can predict that the number of
extant linked-stanza songs by a given poet will be about 14 percent (plus 1.2) of the number of his extant songs.
Poets with unusually frequent or infrequent use of linked stanzas fall outside the shaded area.
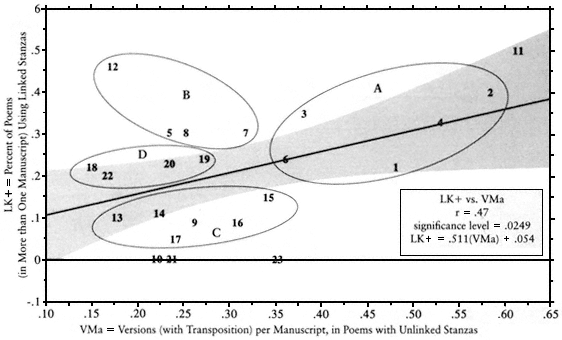
Fig. A-12.
Use of linked Stanzas versus Versions per Manuscript (Unlinked). The more habitually a poet used linked
stanzas, the more versions per manuscript his poems (even those with unlinked stanzas) produced This trend is true
mainly of the early poets (1098–1158). Clusters show chronological trends in acceptance or rejection of stanzaic linkage
Notes To Clusters:
A: 1098–1158; B: 1151–1179; C: 1180–1195; D: 1205–1248
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||