Supercomputing Alternatives
Gordon Bell
C. Gordon Bell, now an independent consultant, was until 1991 Chief Scientist at Stardent Computer. He was the leader of the VAX team and Vice President of R&D at Digital Equipment Corporation until 1983. In 1983, he founded Encore Computer, serving as Chief Technical Officer until 1986, when he founded and became Assistant Director of the Computing and Information Science and Engineering Directorate at NSF. Gordon is also a founder of The Computer Museum in Boston, a fellow of both the Institute of Electrical and Electronics Engineers and the American Association for the Advancement of Science, and a member of the National Academy of Engineering. He earned his B.S. and M.S. degrees at MIT.
Gordon was awarded the National Medal of Technology by the Department of Commerce in 1991 and the von Neumann Medal by the Institute of Electrical and Electronics Engineers in 1992.
Less Is More
Our fixation on the supercomputer as the dominant form of technical computing is finally giving way to reality. Supers are being supplanted by a host of alternative forms of computing, including the interactive, distributed, and personal approaches that use PCs and workstations. The technical computing industry and the community it serves are poised for an exciting period of growth and change in the 1990s.
Traditional supercomputers are becoming less relevant to scientific computing, and as a result, the growth in the traditional vector supercomputer market, as defined by Cray Research, Inc., is reduced from what it was in the early 1980s. Large-system users and the government, who are concerned about the loss of U.S. technical supremacy in this last niche of computing, are the last to see the shift. The loss of supremacy in supercomputers should be of grave concern to the U.S. government, which relies on supercomputers and, thus, should worry about the loss of one more manufacturing-based technology. In the case of supercomputers, having the second-best semiconductors and high-density packaging means that U.S. supercomputers will be second.
The shift away from expensive, highly centralized, time-shared supercomputers for high-performance computing began in the 1980s. The shift is similar to the shift away from traditional mainframes and minicomputers to workstations and PCs. In response to technological advances, specialized architectures, the dictates of economies, and the growing importance of interactivity and visualization, newly formed companies challenged the conventional high-end machines by introducing a host of supersubstitutes: minisupercomputers, graphics supercomputers, superworkstations, and specialized parallel computers. Cost-effective FLOPS, that is, the floating-point operations per second essential to high-performance technical computing, come in many new forms. The compute power for demanding scientific and engineering challenges could be found across a whole spectrum of machines with a range of price/performance points. Machines as varied as a Sun Microsystems, Inc., workstation, a graphics supercomputer, a minisupercomputer, or a special-purpose computer like a Thinking Machines Corporation Connection Machine or an nCUBE Corporation Hypercube all do the same computation for five to 50 per cent of the cost of doing it on a conventional supercomputer. Evidence of this trend abounds.
An example of cost effectiveness would be the results of the PERFECT (Performance Evaluation for Cost-Effective Transformation) contest. This benchmark suite, developed at the University of Illinois Supercomputing Research and Development Center in conjunction with manufacturers and users, attempts to measure supercomputer performance and cost effectiveness.
In the 1989 contest, an eight-processor CRAY Y-MP/832 took the laurels for peak performance by achieving 22 and 120 MFLOPS (million floating-point operations per second) for the unoptimized baseline and hand-tuned, highly optimized programs, respectively. A uniprocessor Stardent Computer 3000 graphics supercomputer won the
cost/performance award by a factor of 1.8 and performed at 4.2 MFLOPS with no tuning and 4.4 MFLOPS with tuning. The untuned programs on the Stardent 3000 were a factor of 27 times more cost effective than the untuned CRAY Y-MP programs. In comparison, a Sun SPARCstation 1 ran the benchmarks roughly one-third as fast as the Stardent.
The PERFECT results typify "dis-economy" of scale. When it comes to getting high-performance computation for scientific and engineering problems, the biggest machine is rarely the most cost effective. This concept runs counter to the myth created in the 1960s known as Grosch's Law, which stated that the power of a computer increased as its price squared. Many studies have shown that the power of a computer increased at most as the price raised to the 0.8 power—a dis-economy of scale.
Table 1 provides a picture of the various computing power and capacity measures for various types of computers that can substitute for supercomputers. The computer's peak power and LINPACK 1K × 1K estimate the peak power that a computer might deliver on a highly parallel application. LINPACK 100-×-100 shows the power that might be expected for a typical supercomputer application and the average speed at which a supercomputer might operate. The Livermore Fortran Kernels (LFKs) were designed to typify workload, that is, the capacity of a computer operating at Lawrence Livermore National Laboratory.
The researchers who use NSF's five supercomputing centers at no cost are insulated from cost considerations. Users get relatively little processing power per year despite the availability of the equivalent 30 CRAY
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
X-MP processors, or 240,000 processor hours per year. When that processing power is spread out among 10,000 researchers, it averages out to just 24 hours per year, or about what a high-power PC can deliver in a month. Fortunately, a few dozen projects get 1000 hours per year. Moreover, users have to contend with a total solution time disproportionate to actual computation time, centralized management and allocation of resources, the need to understand vectorization and parallelization to utilize the processors effectively (including memory hierarchies), and other issues.
These large, central facilities are not necessarily flawed as a source of computer power unless they attempt to be a one-stop solution. They may be the best resource for the very largest users with large, highly tuned parallel programs that may require large memories, file capacity of tens or hundreds of gigabytes, the availability of archive files, and the sharing of large databases and large programs. They also suffice for the occasional user who needs only a few hours of computing a year and doesn't want to own or operate a computer.
But they're not particularly well suited to the needs of the majority of users working on a particular engineering or scientific problem that is embodied in a program model. They lack the interactive and visualization capabilities that computer-aided design requires, for example. As a result, even with free computer time, only a small fraction of the research community, between five and 10 per cent, uses the NSF centers. Instead, users are buying smaller computing resources to make more power available than the large, traditional, centralized supercomputer supplies. Ironic though it may seem, less is more .
Supersubstitutes Provide More Overall Capacity
Users can opt for a supersubstitute if it performs within a factor of 10 of a conventional supercomputer. That is, a viable substitute must supply up to 10 per cent the power of a super so as to deliver the same amount of computation in one day that the typical user could expect from a large, time-shared supercomputer—between a half-hour and an hour of Cray service per day and a peak of two hours. Additionally, it should be the best price performer in its class, sustain high throughput on a wide variety of jobs, and have appropriate memory and other resources.
Data compiled by the market research firm Dataquest Inc. has been arranged in Table 2 so as to show technical computer installations in 1989, along with several gauges of computational capacity: per-processor
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
performance on the Livermore Loops workload benchmark,[*] per-processor performance on LINPACK 100-×-100 and peak performance on the LINPACK 1000-×-1000 benchmark,[**] and total delivered capacity using the Livermore Loops workload measure, expressed as an equivalent to the CRAY Y-MP eight-processor computer's 150 MFLOPS.
How Supers Are Being Niched
Supercomputers are being niched across the board by supersubstitutes that provide a user essentially the same service but at much lower entry and use costs. In addition, all the other forms of computers, including
[*] LFKs consist of 24 inner loops that are representative of the programs run at Lawrence Livermore National Laboratory. The Spectrum of Code varies from being entirely scalar to almost perfectly vectorizable, whereby the supercomputer can run at its maximum speed. The harmonic mean is used to measure relative performances, which correspond to the time it takes to run to all 24 programs. The SPEC and PERFECT benchmarks also correlate with the Livermore benchmark.
[**] The LINPACK benchmark measures the computer's ability to solve a set of linear algebraic equations. These equations are the basis of a number of programs such as finite-element models used for physical systems. The small matrix size (100 × 100) benchmark corresponds to the rate at which a typical application program runs on a supercomputer. The large LINPACK corresponds to the best case that a program is likely to achieve.
mainframes with vector facilities, minis, superminis, minisupers, ordinary workstations, and PCs, offer substitutes. Thus, the supercomputer problem (i.e., the lack of the U.S.'s ability to support them in a meaningful market fashion) is based on economics as much as on competition.
Numerous machines types are contenders as supersubstitutes. Here are some observations on each category.
Workstations
Workstations from companies like Digital Equipment Corporation (DEC), the Hewlett-Packard Company, Silicon Graphics Inc., and Sun Microsystems, among others, provide up to 10 per cent of the capacity of a CRAY Y-MP processor. But they do it at speeds of less than 0.3 per cent of an eight-processor Y-MP LINPACK peak and at about two per cent the speed of a single-processor Y-MP on the LINPACK 100-×-100 benchmark. Thus, while they may achieve impressive scalar performance, they have no way to hit performance peaks for the compute-intensive programs for which the vector and parallel capabilities of supercomputers were developed. As a result, they are not ideal as supersubstitutes. Nevertheless, ordinary computers like workstations, PCs, minicomputers, and superminis together provide most of the technical computing power available today.
Minicomputers and Superminis
These machines provide up to 20 per cent of the capacity of a CRAY-MP processor. But again, with only 0.25 per cent the speed of the LINPACK peak of the Cray, they are also less-than-ideal supercomputer substitutes.
Mainframes
IBM may be the largest supplier of supercomputing power. It has installed significant computational power in its 3090 mainframes with vector-processing facilities. Dataquest has estimated that 250 of the 750 3090-processors shipped last year had vector-processing capability. Although a 3090/600 has 25 per cent of the CRAY Y-MP's LINPACK peak power, its ability to carry out a workload, as measured by Livermore Loops, is roughly one-third that of a CRAY Y-MP/8.
But we see only modest economic advantages and little or no practical benefit to be derived from substituting one centralized, time-shared resource for another. For numeric computing, mainframes are not the best performers in their price class. Although they supply plenty of computational power, they rarely hit the performance peaks that supercomputer-class applications demand. The mainframes from IBM—and
even the new DEC 9000 series—suffer from the awkwardness of traditional architecture evolution. Their emitter-coupled-logic (ECL) circuit technology is costly. And the pace of improvement in ECL density lags far behind the rate of progress demonstrated by the complementary-metaloxide-semiconductor (CMOS) circuitry employed in more cost-effective and easier-to-use supersubstitutes.
Massively Data-Parallel Computers
There is a small but growing base of special-purpose machines in two forms: multicomputers (e.g., hundreds and thousands of computers interconnected) and the SIMD (e.g., the Connection Machine, MasPar), some of which supply a peak of 10 times a CRAY Y-MP/8 with about the same peak-delivered power (1.5 GFLOPS) on selective, parallelized applications that can operate on very large data sets. This year a Connection Machine won the Bell Perfect Club Prize[*] for having the highest peak performance for an application. These machines are not suitable for a general scientific workload. For programs rich in data parallelism, these machines can deliver the performance. But given the need for complete reprogramming to enable applications to exploit their massively parallel architectures, they are not directly substitutable for current supercomputers. They are useful for the highly parallel programs for which the super is designed. With time, compilers should be able to better exploit these architectures that require explicitly locating data in particular memory modules and then passing messages among the modules when information needs to be shared.
The most exciting computer on the horizon is the one from Kendall Square Research (KSR), which is scalable to over 1000 processors as a large, shared-memory multiprocessor. The KSR machine functions equally well for both massive transaction processing and massively parallel computation.
Minisupercomputers
The first viable supersubstitutes, minisupercomputers, were introduced in 1983. They support a modestly interactive, distributed mode of use and exploit the gap left when DEC began in earnest to ignore its
[*] A prize of $1000 is given in each of three categories of speed and parallelism to recognize applications programs. The 1988 prizes went to a 1024-node nCUBE at Sandia and a CRAY X-MP/416 at the National Center for Atmospheric Research; in 1989 a CRAY Y-MP/832 ran the fastest.
technical user base. In terms of power and usage, their relationship to supercomputers is much like that of minicomputers to mainframes. Machines from Alliant Computer Systems and CONVEX Computer Corporation have a computational capacity approaching one CRAY Y-MP processor.
Until the introduction of graphics supercomputers in 1988, minisupers were the most cost-effective source of supercomputing capacity. But they are under both economic and technological pressure from newer classes of technical computers. The leading minisuper vendors are responding to this pressure in different ways. Alliant plans to improve performance and reduce computing costs by using a cost-effective commodity chip, Intel's i860 RISC microprocessor. CONVEX has yet to announce its next line of minisupercomputers; however, it is likely to follow the Cray path of a higher clock speed using ECL.
Superworkstations
This machine class, judging by the figures in Table 1, is the most vigorous of all technical computer categories, as it is attracting the majority of buyers and supplying the bulk of the capacity for high-performance technical computing. In 1989, superworkstation installations reached more users than the NSF centers did, delivering four times the computational capacity and power supplied by the CRAY Y-MP/8.
Dataquest's nomenclature for this machine class—superworkstations—actually comprises two kinds of machines: graphics supercomputers and superworkstations. Graphics supercomputers were introduced in 1988 and combine varying degrees of supercomputer capacity with integral three-dimensional graphics capabilities for project and departmental use (i.e., multiple users per system) at costs ranging between $50,000 and $200,000. Priced even more aggressively, at $25,000 to $50,000, superworkstations make similar features affordable for personal use.
Machines of this class from Apollo (Hewlett-Packard), Silicon Graphics, Stardent, and most recently from IBM all provide between 10 and 20 per cent of the computational capacity of a CRAY Y-MP processor, as characterized by the Livermore Loops workload. They also run the LINPACK 100-×-100 benchmark at about 12 per cent of the speed of a one-processor Y-MP. While the LINPACK peak of such machines is only two per cent of an eight-processor CRAY Y-MP, the distributed approach of the superworkstations is almost three times more cost effective. In other words, users spending the same amount can get three to five times
as much computing from superworkstations and graphics supercomputers than from a conventional supercomputer.
In March 1990, IBM announced its RS/6000 superscalar workstation, which stands out with exceptional performance and price performance. Several researchers have reported running programs at the same speed as the CRAY Y-MP. The RS/6000's workload ability measured by the Livermore Loops is about one-third that of a CRAY Y-MP processor.
Superworkstations promise the most benefits for the decade ahead because they conjoin more leading-edge developments than any other class of technical computer, including technologies that improve performance and reduce costs, interactivity, personal visualization, smarter compiler technologies, and the downward migration of super applications. More importantly, superworkstations provide for interactive visualization in the same style that PCs and workstations used to stabilize mainframe and minicomputer growth. Radically new applications will spring up around this new tool that are not versions of tired 20-year-old code that ran on the supercomputer, mainframe, and minicode museums. These will come predominantly from science and engineering problems, but most financial institutions are applying supercomputers for econometric modeling, work optimization, portfolio analysis, etc.
Because these machines are all based on fast-evolving technologies, including single-chip RISC microprocessors and CMOS, we can expect performance gains to continue at the rate of over 50 per cent a year over the next five years. We'll also see continuing improvements in clock-rate growth to more than 100 megahertz by 1992. By riding the CMOS technology curve, future superworkstation architectures will likely be able to provide more power for most scientific applications than will be available from the more costly multiple-chip systems based on arrays of ECL and GaAs (gallium arsenide) gates. Of course, the bigger gains will come through the use of multiple of these low-cost processors for parallel processing.
Why Supercomputers Are Becoming Less General Purpose
Like their large mainframe and minicomputer cousins, the super is based on expensive packaging of ECL circuitry. As such, the evolution in performance is relatively slower (doubling every five years) than that of the single-chip microprocessor, which doubles every 18 months. One of the problems in building a cost-effective, conventional supercomputer is
that every part—from the packaging to the processors, primary and secondary memory, and the high-performance network—typically costs more than it contributes to incremental performance gains. Supercomputers built from expensive, high-speed components have elaborate processor-memory connections, very fast transfer disks, and processing circuits that do relatively few operations per chip and per watt, and they require extensive installation procedures with high operating costs.
To get the large increases in peak MFLOPS performance, the supercomputer architecture laid down at Cray Research requires having to increase memory bandwidth to support the worst-case peak. This is partially caused by Cray's reluctance to use modem cache memory techniques to reduce cost and latency. This increase in bandwidth results in a proportional increase in memory latency, which, unfortunately, decreases the computer's scalar speed. Because workloads are dominated by scalar code, the result is a disproportionately small increase in throughput, even though the peak speed of a computer increases dramatically. Nippon Electric Corporation's (NEC's) four-processor SX-3, with a peak of 22 GFLOPS, is an example of providing maximum vector speed. In contrast, one-chip microprocessors with on-board cache memory, as typified by IBM's superscalar RS/6000 processor, are increasing in speed more rapidly than supers for scientific codes.
Thus, the supercomputer is becoming a special-purpose computer that is only really cost effective for highly parallel problems. It has about the same performance of highly specialized, parallel computers like the Connection Machine, the microprocessor-based nCUBE, and Intel's multicomputers, yet the super costs a factor of 10 more because of its expensive circuit and memory technology. In both the super and nontraditional computers, a program has to undergo significant transformations in order to get peak performance.
Now look at the situation of products available on the market and what they are doing to decrease the supercomputer market. Figure 1, which plots performance versus the degree of problem parallelism (Amdahl's Law), shows the relative competitiveness in terms of performance for supersubstitutes. Fundamentally, the figure shows that supers are being completely "bracketed" on both the bottom (low performance for scalar problems) and the top (highly parallel problems). The figure shows the following items:
1. The super is in the middle, and its performance ranges from a few tens of MFLOPS per processor to over two GFLOPS, depending on the degree of parallelization of the code and the number of processors
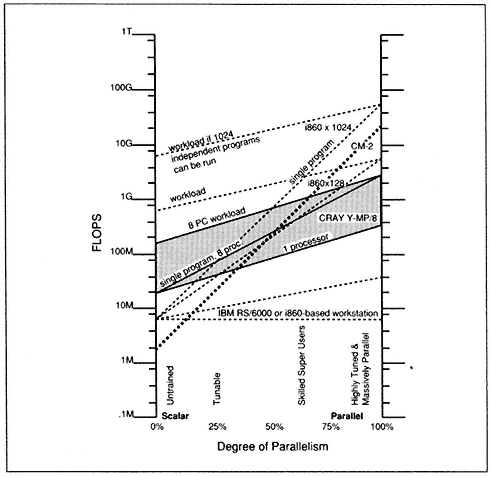
Figure 1.
Performance in floating-point operations per second versus degree of parallel code for four
classes of computer: the CRAY Y-MP/8; the Thinking Machines Corporation CM-2; the IBM
RS/6000 and Intel i860-based workstation; and the Intel 128 and 1024 iPSC/860 multicomputers.
used. Real applications have achieved sustained performance of about 50 per cent of the peak.
2. Technical workstations supply the bulk of computing for the large, untrained user population and for code that has a low degree of vectorization (that must be tuned to run well). In 1990, the best CMOS-based technical workstations by IBM and others performed at one-third the capacity of a single-processor Y-MP on a broad range of programs and cost between $10,000 and $100,000. Thus, they are anywhere from five to 100 times more cost effective than a super costing at around $2,500,000 per processor. This situation differs from a decade ago, when supers provided over a factor of 20 greater
performance for scalar problems against all computers. The growth in clock performance for CMOS is about 50 per cent per year, whereas the growth in performance for ECL is only 10 to 15 per cent per year.
3. For programs that have a high degree of parallelization, two alternatives threaten the super in its natural habitat. The parallelization has to be done by a small user base.
a. The Connection Machine costs about one-half the Y-MP but provides a peak of almost 10 times the Cray. One CM-2 runs a real-time application code at two times the peak of a Cray.
b. Multicomputers can be formed from a large collection of high-volume, cost-effective CMOS microprocessors. Intel's iPSC/860 multicomputer comes in a range of sizes from typical (128 computers) to large (1K computers). IBM is offering the ability to interconnect RS/6000s. A few RS/6000s will offer any small team the processing power of a CRAY Y-MP processor for a cost of a few hundred thousand dollars.
The Supercomputer Industry
The business climate of the 1990s offers further evidence that big machines may be out of step with more cost-effective, modern computing styles. Table 2 shows the number of companies involved in the highly competitive technical computing industry. The business casualties in the high end of the computer industry last year constitute another indicator that the big-machine approach to technical computing might be flawed. No doubt, a variety of factors contributed to the demise of Control Data Corporation's Engineering Technology Associates Systems subsidiary (St. Paul, Minnesota), Chopp (San Diego, California), Cydrome Inc. (San Jose, California), Evans & Sutherland's startup supercomputer division (Sunnyvale, California), Multiflow Computer (New Haven, Connecticut), and Scientific Computer Systems (San Diego, California). But in an enormously crowded market, being out of step with the spirit of the times might have had something to do with it.
With Cray Research, Inc., having spun off Cray Computer Corporation and with several other startups designing supercomputers, it's hard to get very worried about the U.S. position vis-à-vis whether enough is being done about competitiveness. Unfortunately, less and less is being spent on the underlying circuit technologies for the highest possible speeds. It's fairly easy to predict that of the half-dozen companies attempting to build new supers, there won't be more than three viable U.S. suppliers, whereas today we only have one.
From an economic standpoint, the U.S. is fortunate that the Japanese firms are expending large development resources that supercomputers require because these same engineers could, for example, be building consumer products, robots, and workstations that would have greater impact on the U.S. computer and telecommunications markets. It would be very smart for these Japanese manufacturers to fold up their expensive efforts and leave the small but symbolically visible supercomputer market to the U.S. Japan could then continue to improve its position in the larger consumer and industrial electronics, communication, and computing sectors.
Is the Supercomputer Industry Hastening Its Own Demise?
The supercomputer industry and its patrons appear to be doing many things that hasten an early demise. Fundamentally, the market for supercomputers is only a billion dollars, and the R&D going into supers is also on the order of a billion. This simply means too many companies are attempting to build too many noncompatible machines for too small a market. Much of the R&D is redundant, and other parts are misdirected.
The basic architecture of the "true" supercomputer was clearly defined as a nonscalable, vector multiprocessor. Unfortunately, the larger it is made to get the highest peak or advertising speed, the less cost effective it becomes for real workloads. The tradeoff inherent in making a high-performance computer that is judged on the number of GFLOPS it can calculate, based on such a design, seems to be counterproductive. The supercomputer has several inconsistencies (paradoxes) in its design and use:
1. In providing the highest number of MFLOPS by using multiprocessors with multiple pipe vector units to support one to 1.5 times the number of memory accesses as the peak arithmetic speed, memory latency is increased. However, to have a well-balanced, general-purpose supercomputer that executes scalar code well, the memory latency needs to be low.
2. In building machines with the greatest peak MFLOPS (i.e., the advertising speed), many processors are required, raising the computer's cost and lowering per-processor performance. However, supercomputers are rarely used in a parallel mode with all processors; thus, supers are being built at an inherent dis-economy of scale to increase the advertising speed.
3. Having many processors entails mastering parallelism beyond that obtainable through automatic parallelization/vectorization. However, supercomputer suppliers aren't changing their designs to enable scaleability or to use massive parallelism.
4. In providing more than worst-case design of three pipelines to memory, or 1.5 times as many mega-accesses per second as the machine has MFLOPS, the cost effectiveness of the design is reduced at least 50 per cent. However, to get high computation rates, block algorithms are used that ensure memory is not accessed. The average amount of computation a super delivers over a month is only five to 10 per cent of the peak, indicating the memory switch is idle most of the time.
In addition to these paradoxes, true supers are limited in the following ways:
1. Not enough is being done to train users or to make the super substantially easier to use. Network access needs to be much faster and more transparent. The X-Terminal server interface can potentially show the super to have a Macintosh-like interface. No companies provide this at present.
2. The true supercomputer design formula seems flawed. The lack of caches, paging, and scaleability make it doomed to chase the clock. For example, paradox 4 above indicates that a super could probably deliver two to four times more power by doubling the number of processors but without increasing the memory bandwidth or the cost.
3. Cray Research describes a massively parallel attached computer. Cray is already quite busy as it attempts to enter into the minisupercomputer market. Teaming with a startup such as Thinking Machines Corporation (which has received substantial government support) or MasPar for a massively parallel facility would provide a significantly higher return on limited brain power.
4. The U.S. has enough massively parallel companies and efforts. These have to be supported in the market and through use before they perish. Because these computers are inherently specialized (note the figure), support via continued free gifts to labs and universities is not realistic in terms of establishing a real marketplace.
A Smaller, Healthier Supercomputer Industry
Let's look at what fewer companies and better R&D focus might bring:
1. The CRAY Y-MP architecture is just fine. It provides the larger address space of the CRAY-2. The CRAY-3 line, based on a new architecture, will further sap the community of skilled systems-software and applications-builder resources. Similarly, Supercomputer Systems, Inc., (Steve Chen's startup) is most likely inventing a new architecture that requires new systems software and applications. Why have three
architectures for which people have to be trained so they can support operating systems and write applications?
2. Resources could be deployed on circuits and packaging to build GaAs or more aggressive ECL-based or even chilled CMOS designs instead of more supercomputer architectures and companies.
3. Companies that have much of the world's compiler expertise, such as Burton Smith's Tera Computer Company or SSI in San Diego, could help any of the current super companies. It's unlikely that any funding will come from within the U.S. to fund these endeavors once the government is forced into some fiscal responsibility and can no longer fund them. Similarly, even if these efforts get Far-East funding, it is unlikely they will succeed.
4. Government support could be more focused. Supporting the half-dozen companies by R&D and purchase orders just has to mean higher taxes that won't be repaid. On the other hand, continuing subsidies of the parallel machines is unrealistic in the 1990s if better architectures become available. A more realistic approach is to return to the policy of making the funds available to buy parallel machines, including ordinary supers, but to not force the purchase of particular machines.
Policy Issues
Supporting Circuit and Packaging Technology
There is an impression that the Japanese manufacturers provide access to their latest and fastest high-speed circuitry to build supercomputers. For example, CONVEX gets the parts from Fujitsu for making cost-effective minisupercomputers, but these parts are not components of fast-clock, highest-speed supercomputers. The CONVEX clock is two to 10 times slower when compared with a Cray, Fujitsu, Hitachi, or NEC mainframe or super.
High-speed circuitry and interconnect packaging that involves researchers, semiconductor companies, and computer manufacturers must be supported. This effort is needed to rebuild the high-speed circuitry infrastructure. We should develop mechanisms whereby high-speed-logic R&D is supported by those who need it. Without such circuitry, traditional vector supercomputers cannot be built. Here are some things that might be done:
1. Know where the country stands vis-à-vis circuitry and packaging. Neil Lincoln described two developments at NEC in 1990—the SX-3 is running benchmark programs at a 1.9-nanosecond clock; one
processor of an immersion-cooled GaAs supercomputer is operating at a 0.9-nanosecond clock.
2. Provide strong and appropriate support for the commercial suppliers who can and will deliver in terms of quality, performance, and cost. This infrastructure must be rebuilt to be competitive with Japanese suppliers. The Department of Defense's (DoD's) de facto industrial policy appears to support a small cadre of incompetent suppliers (e.g., Honeywell, McDonnell Douglas, Rockwell, Unisys, and Westinghouse) who have repeatedly demonstrated their inability to supply industrial-quality, cost-effective, high-performance semiconductors. The VHSIC program institutionalized the policy of using bucks to support the weak suppliers.
3. Build MOSIS facilities for the research and industrial community to use to explore all the high-speed technologies, including ECL, GaAs, and Josephson junctions. This would encourage a foundry structure to form that would support both the research community and manufacturers.
4. Make all DoD-funded semiconductor facilities available and measured via MOSIS. Eliminate and stop supporting the poor ones.
5. Support foundries aimed at custom high-speed parts that would improve density and clock speeds. DEC's Sam Fuller (a Session 13 presenter) described a custom, 150-watt ECL microprocessor that would operate at one nanosecond. Unfortunately, this research effort's only effect is likely to be a demonstration proof for competitors.
6. Build a strong packaging infrastructure for the research and startup communities to use, including gaining access to any industrial packages from Cray, DEC, IBM, and Microelectronics and Computer Technology Corporation.
7. Convene the supercomputer makers and companies who could provide high-speed circuitry and packaging. Ask them what's needed to provide high-performance circuits.
Supers and Security
For now, the supercomputer continues to be a protected species because of its use in defense. Also, like the Harley Davidson, it has become a token symbol of trade and competitiveness, as the Japanese manufacturers have begun to make computers with peak speeds equal to or greater than those from Cray Research or Cray Computer. No doubt, nearly all the functions supers perform for defense could be carried out more cheaply by using the alternative forms of computing described above.
Supers for Competitiveness
Large U.S. corporations are painstakingly slow, reluctant shoppers when it comes to big, traditional computers like supercomputers, mainframes, and even minisupercomputers. It took three years, for example, for a leading U.S. chemical company to decide to spring for a multimillion-dollar CRAY X-MP. And the entire U.S. automotive industry, which abounds in problems like crashworthiness studies that are ideal candidates for high-performance computers, has less supercomputer power than just one of its Japanese competitors. The super is right for the Japanese organization because a facility can be installed rapidly and in a top-down fashion.
U.S. corporations are less slow to adopt distributed computing by default. A small, creative, and productive part of the organization can and does purchase small machines to enhance their productivity. Thus, the one to 10 per cent of the U.S.-based organization that is responsible for 90 to 95 per cent of a corporation's output can and does benefit. For example, today, almost all electronic CAD is done using workstations, and the product gestation time is reduced for those companies who use these modern tools. A similar revolution in design awaits other engineering disciplines such as mechanical engineering and chemistry—but they must start.
The great gain for productivity is by visualization that comes through interactive supercomputing substitutes, including the personal supercomputers that will appear in the next few years. A supercomputer is likely to increase the corporate bureaucracy and at the same time inhibit users from buying the right computer—the very users who must produce the results!
By far, the greatest limitation in the use of supercomputing is training. The computer-science community, which, by default, takes on much of the training for computer programming, is not involved in supercomputing. Only now are departments becoming interested in the highly parallel computers that will form the basis of this next (fifth) generation of computing.
Conclusions
Alternative forms for supercomputing promise the brightest decade ever, with machines that have the ability to simulate and interact with many important physical phenomena.
Large, slowly evolving central systems will continue to be supplanted by low-cost, personal, interactive, and highly distributed computing because of cost, adequate performance, significantly better performance/cost, availability, user friendliness, and all the other factors that caused users of mainframes and minis to abandon the more centralized structures for personal computing. By the year 2000, we expect nearly all personal computers to have the capability of today's supercomputer. This will enable all users to simulate the immense and varied systems that are the basis of technical computing.
The evolution of the traditional supercomputer must change to a more massively parallel and scalable structure if it is to keep up with the peak performance of evolving new machines. By 1995, specialized, massively parallel computers capable of a TFLOPS (1012 floating-point operations per second) will be available to simulate a much wider range of physical phenomena.
Epilogue, June 1992
Clusters of 10 to 100 workstations are emerging as a high-performance parallel processing computer—the result of economic realities. For example, Lawrence Livermore National Laboratory estimates spending three times more on workstations that are 15 per cent utilized than it does on supercomputers. Supers cost a dollar per 500 FLOPS and workstations about a dollar per 5000 FLOPS. Thus, 25 times the power is available in their unused workstations as in supers. A distributed network of workstations won the Gordon Bell Prize for parallelism in 1992.
The ability to use workstation clusters is enabled by a number of environments such as Linda, the Parallel Virtual Machine, and Parasoft Corporation's Express. HPF (Fortran) is emerging as a powerful standard to allow higher-level use of multicomputers (e.g., Intel's Paragon, Thinking Machine's CM-5), and this could also be used for workstation clusters as standardization of interfaces and clusters takes place.
The only inhibitor to natural evolution is that government, in the form of the High Performance Computing and Communications (HPCC) Initiative, and especially the Defense Advanced Research Projects Agency, is attempting to "manage" the introduction of massive parallelism by attempting to select winning multicomputers from its development-funded companies. The HPCC Initiative is focusing on the peak TFLOPS at any price, and this may require an ultracomputer (i.e., a machine costing $50 to $250 million). Purchasing such a machine would be a
mistake—waiting a single three-year generation will reduce prices by a least a factor of four.
In the past, the government, specifically the Department of Energy, played the role of a demanding but patient customer, but it never funded product development—followed by managing procurement to the research community. This misbehavior means that competitors are denied the significant market of leading-edge users. Furthermore, by eliminating competition, weak companies and poor computers emerge. There is simply no need to fund computer development. This money would best be applied to attempting to use the plethora of extant machines—and with a little luck, weed out the poor machines that absorb and waste resources.
Whether traditional supercomputers or massively parallel computers provide more computing, measured in FLOPS per month by 1995, is the object of a bet between the author and Danny Hillis of Thinking Machines. Unless government continues to tinker with the evolution of computers by massive funding for massive parallelism, I believe supers will continue as the main source of FLOPS in 1995.