Future Directions for Research
We have already started looking at how we can make "cosmetic changes" to the LAPACK software—adapt it in a semiautomatic fashion for distributed-memory architectures. In this effort, our current work on blocked operations will be appropriate because the operations minimize communication and provide a good surface-to-volume ratio. We also expect that this task will require defining yet another set of routines, this one based on the BLACS (basic linear algebra communication routines). Once again, we will draw on what has been done in the community for those operations.
As a preliminary piece of data, we show in Figure 4 an implementation of LU decomposition from LAPACK, run on a 64-processor Intel iPSC. Clearly, we are not yet achieving optimum performance, but the situation is improving daily.
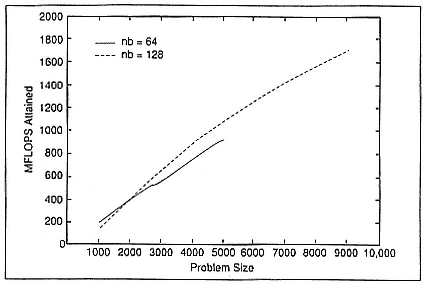
Figure 4.
Pipelined LU factorization results for 64 and 128 nodes.
Some interest has also been expressed in developing a C implementation of the LAPACK library. And we continue to track what is happening with Fortran 90 and with the activities of the Parallel Computing Forum.
In the meantime, we are in our last round of testing of the shared-memory version of LAPACK. The package will be released to the public in 1992.