Some Developments in Parallel Applications II
Some additional observations concerning the development of massively parallel applications can be drawn from our research into Strategic Defense Initiative (SDI) tracking and correlation problems. This is a classic problem of tracking tens or hundreds of thousands of objects, which Sandia is investigating jointly with Los Alamos National Laboratory, the Naval Research Laboratory, and their contractors. Each member of the team is pursuing a different approach to parallelism, with Sandia's charter being to investigate massive parallelism on MIMD hypercubes.
One of the central issues in parallel computing is that a major effort may be expended in overhauling the fundamental algorithms involved as part of the porting process, irrespective of the architecture involved. The course of the initial parallelization effort for the tracker-correlator was interesting: parallel code development began on the hypercube, followed by a quick retreat to restructuring the serial code on the Cray. The original tracking algorithms were extremely memory intensive, and data structures required extensive modification to improve the memory use of the code (Figure 3), but first-generation hypercube nodes with a mere half megabyte of memory were not well suited for the task.
Halbgewachs et al. (1990) developed a scheme for portability between the X-MP and the nCUBE/ten in which they used accesses to the solid-state device (SSD) to swap "hypercube processes" and to simulate the handling of the message-passing. In this scheme one process executes, sends its "messages" to the SSD, and is then swapped out for another "process." This strategy was a boon to the code-development effort. Key algorithms were quickly restructured to reduce the memory use from second order to first order. Further incremental improvements have been made to reduce the slope of the memory-use line. The original code could not track more than 160 objects. The first version with linear memory requirements was able to track 2000 objects on the Cray and the nCUBE/ten.
On the nCUBE/ten a heterogeneous implementation was created with a host process. (A standard host utility may be used in lieu of a host program on the second-generation hypercubes.) The tracking code that runs on the nodes has a natural division into two phases. A dynamic load balancer was implemented with the first phase of the tracking algorithm, which correlates new tracks to known clusters of objects. The second phase, in which tracks are correlated to known objects, is performed on the rest of the processors.
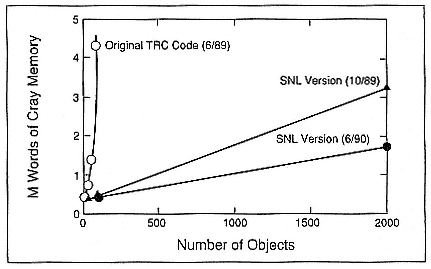
Figure 3.
Improved memory utilization: Phase 1, reduced quadratic dependence to linear;
Phase 2, reduced coefficient of linear dependence.
Given the demonstration of an effective heterogeneous implementation and the ability to solve large problems, suddenly there is user interest in real-time and disk I/O capabilities, visualization capabilities, etc. When only small problems could be solved, I/O and visualization were not serious issues.
Performance evaluation that leads to algorithm modifications is critical when large application codes are parallelized. For example, the focus of SDI tracking is on simulating much larger scenarios, i.e., 10,000 objects, as of September 1990, and interesting things happen when you break new ground in terms of problem size. The first 10,000-object run pinpointed serious bottlenecks in one of the tracking phases. The bottleneck was immediately removed, and run time for the 10,000-object problem was reduced from three hours to one hour. Such algorithmic improvements are just as important as improving the scalability of the parallel simulation because a simulation that required 3000 or 4000 processors to run in an hour now requires only 1000.
A heterogeneous software implementation, such as the one described above for the SDI tracking problem, suggests ways of producing heterogeneous hardware implementations for the application. For example, we can quantify the communication bandwidth needed between the different algorithms; i.e., the throughput rate needed in a distributed-computing
approach where one portion of the computation is done on a space platform, other portions on the ground, etc. In addition, MIMD processors might not be needed for all phases of the simulation. Heterogeneous implementations are MIMD at their highest level, but one might be able to take advantage of the power of SIMD computing in some of the phases. Furthermore, heterogeneous nodes are of interest in these massively parallel applications because, for example, using a few nodes with large memories in a critical phase of a heterogeneous application might reduce the total number of processors needed to run that phase in a cost-effective manner.
Given our experience with a heterogeneous implementation on homogeneous hardware, one can propose a heterogeneous hardware system to carry out the computation efficiently. We note, however, that it would be risky to build a system in advance of having the homogeneous hardware implementation. If you're going to do this sort of thing—and the vendors are gearing up and are certainly talking seriously about providing this capability—then I think we really want to start with an implementation on a homogeneous machine and do some very careful performance analyses.