Performance Studies and Problem-Solving Environments
David Kuck
David J. Kuck is Director of the Center for Supercomputing Research and Development, which he organized in 1984, and is a Professor of Computer Science and Electrical and Computer Engineering at the University of Illinois-Urbana/Champaign, where he has been a faculty member since 1965. He is currently engaged in the development and refinement of the Cedar parallel processing system and, in general, in theoretical and empirical studies of various machine and software organization problems, including parallel processor computation methods, interconnection networks, memory hierarchies, and the compilation of ordinary programs for such machines.
I would like to address performance issues in terms of a historical perspective. Instead of worrying about architecture or software, I think we really need to know why the architectures, compilers, and applications are not working as well as they could. At the University of Illinois, we have done some work in this area, but there is a tremendous amount of work remaining. Beyond programming languages, there are some efforts ongoing to make it possible to use machines in the "shrink-wrapped" problem-solving environment that we use in some PCs today.
Figure 1 shows a century-long view of computing, broken into a sequential (or von Neumann) era and a parallel era. The time scales show how long it takes to get the applications, architectures, compilers, etc.,
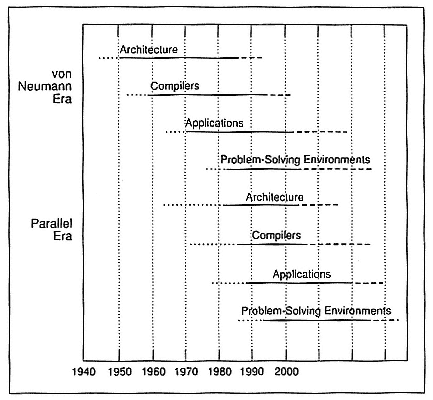
Figure 1.
Two computing eras.
that we have now and will have in the future. Because architectures, compilers, and applications are three components of performance, if you get any one of them slightly wrong, performance may be poor.
With respect to sequential machines, at about the time the RISC processors came along, you could for $5000 buy a box that you really did not program. It was a turnkey machine that you could use for lots of different purposes without having to think about it too much; you could deal with it in your own terms. I regard that kind of use of machines as an area that is going to be very important in the future.
At about the same time, in the early 1980s, companies started producing parallel architectures of all kinds. Then, with about a 30-year delay, everything in the sequential era is repeating itself. Now, for parallel machines we have compilers, and you will be able to start to buy application software one of these days.
In the von Neumann era, the performance issues were instructions, operations, or floating-point operations, reckoned in millions per second,
and the question was whether to use high-level or assembly language to achieve a 10–200 per cent performance increase. In the parallel era, the performance issues have become speedup, efficiency, stability, and tunability to vectorize, parallelize, and minimize synchronization, with performance potentials of 10X, 100X, and even 1000X. In both eras, memory-hierarchy management has been crucial, and now it is much more complex.
Some of these performance issues are illustrated in the Perfect data of Figure 2 (Berry et al. 1989), which plots 13 supercomputers from companies like Hitachi, Cray Research, Inc., Engineering Technology Associates Systems, and Fujitsu. The triangles are the peak numbers that you get from the standard arguments. The dots are the 13 codes run on all those different machines. The variation between the best and worst is about a factor of 100, all the way across. It doesn't matter which machine you run on. That is bad news, it seems to me, if you're coming from a Digital Equipment Corporation VAX. The worst news is that if I label those points, you'll see that it's not the case that some fantastic code is right up there at the top all the way across (Corcoran 1991). Things bounce around.
When you move from machine to machine, there's another kind of instability. If you decided to benchmark one machine, and you decided for price reasons to buy another, architecturally similar, one that you didn't have access to, it may not give similar performance.
The bars in Figure 2 are harmonic means. For these 13 codes on all the supercomputers shown, you're getting a little bit more that 10 million floating-point operations per second. That is one per cent of peak being delivered, and so there is a gap of two orders of magnitude there, and a gap of two orders of magnitude in the best-to-worst envelope.
If you think it's just me who is confused about all this, no less an authority than the New York Times in a two-month period during the Spring of 1990 announced, "Work Station Outperforms Supercomputer," "Cray Is Still Fastest," "Nobody Will Survive the Killer Micros," and "Japanese Computer Rated Fastest by One Measure." So there's tremendous confusion among experts and the public.
How do we get around this? Let me suggest an old remedy in a new form. Why don't we just forget about all the kinds of programming languages we have right now? If you can just specify problems and have them solved on workstations or on PCs, why can't we do that on these machines? I think we will have to eventually if parallel processing is really going to be a general success. I don't really know how to do this, but we have been thinking about it quite a bit at the Center for
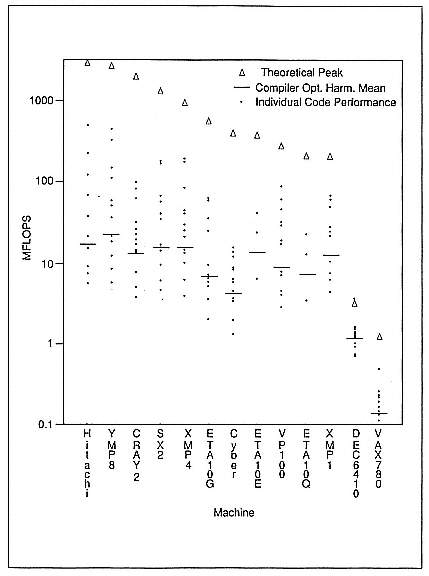
Figure 2.
Thirteen Perfect codes (instability scatter plot).
Supercomputing Research and Development (CSRD) for the last year or so on the basis of our existing software.
If you could write mathematical equations or if you could describe circuits by pictures or whatever, there would be some tremendous benefits. The parallelism that exists in nature should somehow come straight through, so you'd be able to get at that a lot easier. You would be able to adapt old programs to new uses in various ways. As examples, I should say that at Lawrence Livermore National Laboratory, there's the ALPAL system, at Purdue University there's ELLPACK, and Hitachi has something called DEQSOL. These are several examples into which parallelism is starting to creep now.
Figure 3 gives a model of what I think an adaptive problem-solving environment is. This is just your old Fortran program augmented a bit and structured in a new way. There's some logic there that represents "all" methods of solution on "all" machines. The data structures and library boxes contain lots of solution methods for lots of machines and come right out of the Perfect approach. Imagine a three-dimensional volume labeled with architectures and then for each architecture, a set of applications and each application broken down into basic algorithms. That's the way we've been attacking the Perfect database that we're building, and it flows right into this (Kuck and Sameh 1987). So you can have a big library with a lot of structure to it.
The key is that the data structures have to represent all algorithms on all machines, and I've got some ideas about how you translate from one of those to the other if you wanted to adapt a code (Kuck 1991). There are two kinds of adaptation. Take an old program and run it in some new way, e.g., on a different machine with good performance, which is the simplest case. But then, more interestingly, take two programs that should work together. You've got one that simulates big waves on the ocean, and you've got one that simulates a little airplane flying over the ocean, and you want to crash that airplane into that ocean. How would you imagine doing that? Well, I'm thinking of 20 or 30 years from now, but I think we can take steps now that might capture some of these things and lead us in that direction.
I'd like to talk a little bit about spending money. How should we spend high-performance computing money in the 1990s? I looked back at the book and the talks from the Frontiers of Supercomputing meeting in 1983, and I recalled a dozen or so companies, such as Ardent-Stellar,
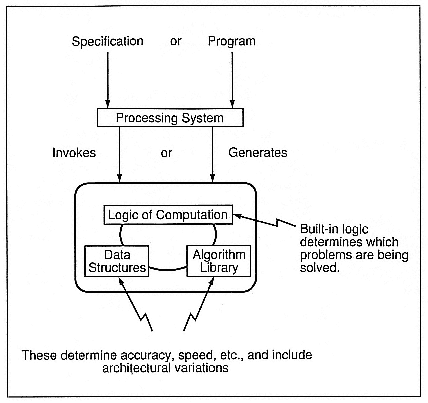
Figure 3.
Problem-solving environment model.
Masscomp-Concurrent, and Gould-Encore, that either went out of business or merged together of necessity. There were probably a billion dollars spent on aborted efforts. There are some other companies that are ongoing and have spent much more money.
On the other hand, I looked at the five universities that were represented at the 1983 meeting, and two of us, the New York University people with IBM and the Cedar group at CSRD, have developed systems (as did the Caltech group, which was not at the 1983 Frontiers meeting). Cedar has had 16 processors in four Alliant clusters running for the last year (Kuck et al. 1986). Although the machine is down right now so we can put in the last 16 processors, which will bring us up to 32, we are getting very interesting performances. We did Level 3 of the basic linear algebra subprograms and popularized parallel libraries. We've done parallelization of lots of languages, including Lisp, which I think is a big accomplishment because of the ideas that are useful in many languages. My point here is that all the money spent on university development projects is perhaps only five per cent of the industrial expenditures, so it seems to be a bargain and should be expanded.
In the 1990s the field needs money for
• research and teaching of computational science and engineering,
• development of joint projects with industry, and
• focusing on performance understanding and problem-solving environments.
For the short term, I think there is no question that we all have to look at performance. For instance, I have a piece of software now that instruments the source code, and I'm able to drive a wedge between two machines that look similar. I take the same code on machines from CONVEX Computer Corporation and Alliant Computer Systems, and frequently a program deviates from what the ratio between those machines should be, and then we are able to go down, down, down and actually locate causes of performance differences, and then we see some commonality of causes. For example, all of the loops with the middle- and inner-loop indices reversed in some subscript position are causing one machine to go down in relative performance. So those kinds of tools are absolutely necessary, and they have to be based on having real codes and real data.
I feel that we're not going to stop working on compilers; but I think we need a longer-term vision and goal, and for me that's obviously derived from the PC, after all, because it is a model that works.
References
M. Berry, D. Chen, P. Koss, D. J. Kuck, et al., "The Perfect Club Benchmarks: Effective Performance Evaluation of Supercomputers," International Journal of Supercomputer Applications3 (3), 5-40 (1989).
E. Corcoran, "Calculating Reality," Scientific American264 (1), 100-109 (1991).
D. J. Kuck, A User's View of High-Performance Scientific and Engineering Software Systems in the Mid-21st Century, Intelligent Software Systems I , North-Holland Press, Amsterdam (1991).
D. J. Kuck, E. S. Davidson, D. H. Lawrie, and A. H. Sameh, "Parallel Supercomputing Today and the Cedar Approach," Science231 , 967-974 (1986).
D. J. Kuck and A. H. Sameh, "Supercomputing Performance Evaluation Plan," in Lecture Notes in Computer Science, No. 297: Proceedings of the First International Conference on Supercomputing, Athens, Greece , T. S. Papatheodorou, E. N. Houstis, C. D. Polychronopoulos, Eds., Springer-Verlag, New York, pp. 1-17 (1987).