It's Time to Face Facts
Joe Brandenburg
Joe Brandenburg is manager of the Computational Sciences Group at Intel Supercomputer Systems Division. He is an expert in parallel programming, having applied his expertise to the fields of artificial intelligence, finance, and general high-performance computing and architectures. He received a Ph.D. in mathematics from the University of Oregon in 1980 and an M.S. in computer science from the University of Maryland in 1983. He has been a member of the technical staff at Intel since 1985.
I am sure that everyone is aware of the efforts of Intel in the last five years in building parallel processors. We started out with what was really a toy in order to learn something about writing parallel programs, and then we developed a machine that was actually competitive with minis and mainframes. We now have a machine that does compete with supercomputers, with the goal to build what we are starting to call ultracomputers. We want to go beyond the supercomputer type of machine.
We see the building of these kinds of computers—these high-performance computers—as having lots of pieces, all of which I will not be able to discuss here. Fundamentally, in building these types of machines, we have to deal with the processor, the memory, and the interconnection hardware. We have to deal with the operating system, the compilers, and the actual software needed for the applications.
Let me begin by discussing building a machine that is capable of 1012 floating-point operations per second (TFLOPS) and that is based on traditional supercomputing methods. If I take today's supercomputing capabilities—that is, an MFLOPS processor, approximately a GFLOPS machine—and want to build a TFLOPS machine, I'd have to have 1000 processors put together (Figure 1). Of course, we don't really know how to do that today, but that would be what it would take. If I want to build it in a 10-year time frame, I still am going to have to put together hundreds of these supercomputers—traditional kinds of CPUs. That is not going to be easy, and it is not going to be cheap.
If I want to build a TFLOPS machine with the microprocessors and I want to do that today, I'd have to put together some 10,000 processors (Figure 2). By the year 1995, that would be 3000 or 4000 of these processors, and by the year 2000, I'd need only 1000 processors.
Today we know how to put together hundreds of these things. We believe that within a couple of years, we will be producing machines that have thousands of processors, and therefore in the year 2000, we will definitely be able to put together 1000 of these machines. That will actually be a step backward for us. From a processor point of view, that means we can achieve TFLOPS performance if we concentrate on using stock, off-the-shelf microprocessors.
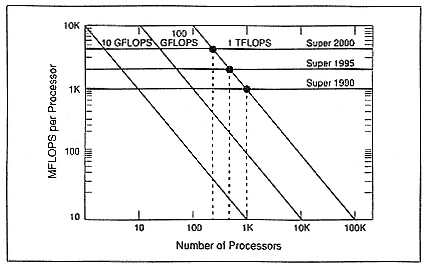
Figure 1.
Achieving TFLOPS performance with traditional supercomputers (parallelism
versus processor speed).
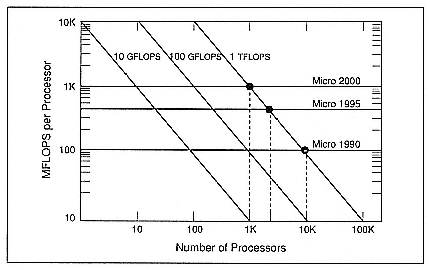
Figure 2.
Achieving TFLOPS performance with micro-based multicomputers (parallelism
versus processor speed).
We will have to be able to make all of these machines talk with each other, so we have to deal with the interconnectivity, which will mean that we will have to concentrate on building the appropriate interconnectivity. We will need to take the type of the research that has been done over the last few years at places like Caltech and actually put into a higher and higher silicon the necessary connections to move the bytes into the 40-, 50-, and 100-megabyte-per-channel networks and, with them, build the scalable interconnection networks. There are now known technology paths that can get us to the appropriate level of support for building the interconnections that will provide sufficient hardware bandwidth and for moving messages between these machines (Figure 3).
That leaves us, then, with the problem of making sure we can then get the messages out the door fast enough, that is, the latency issue of the time it takes to set a message up, push it out, and bring it back. That problem is solved with a combination of having good interfaces between the processors and building good architecture on the nodes. In addition, you need very lightweight operating systems so that you won't have to pay a large software overhead. If we carefully build these systems, we will be able to support both MIMD and single-processor, multiple-data architectures.
The Touchstone program is a joint project of Intel and the Defense Advanced Research Projects Agency to develop a series of prototypes of
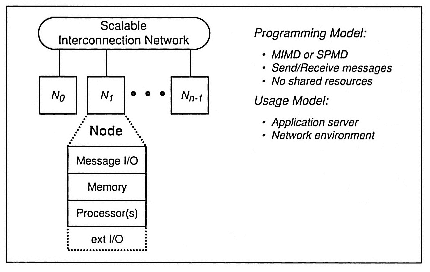
Figure 3.
Message-passing multicomputers (scalable parallel computing systems).
these machines (Figure 4). It is Intel's responsibility to commercialize products out of that. The first machine, Iota, was actually the add-I/O capability to our second-generation iPSC. The next step was to add a higher-performance microprocessor to prove the theory that we can continue to leverage the overall technologies we develop by placing a new processor each time. The Gamma project is based, essentially, on the Intel i860.
Delta was scheduled for September 1990 but has been delayed until September 1991. The idea behind Delta is to use the same essential processor but to raise the number of nodes. To match the processing with the communication, we have to go to a new generation of communications. From a hardware point of view, the Gamma step is to go to the i860 processor; the Delta step is to go to these higher-performance networks.
Sigma will be the final prototype in this particular project, which will go to 2000 processors, again based on the same kind of interconnect but with high performance. The latest Intel process technology is to build the writing chips. Perhaps the most significant advance for Sigma is the packaging issues. That is, we will have to handle 2000 processors and find ways of applying packaging technologies so that we can fit them into a package no bigger than that which contains the 512-processor Delta machine. Thus, a series of processor machines, interconnects, and
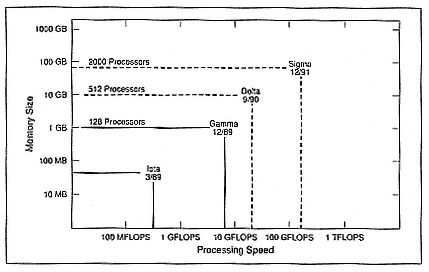
Figure 4.
Touchstone prototypes (processing speed versus memory size).
packaging will culminate in what should be a 500-GFLOPS machine by the year 1992.
We now realize we need to put much more effort into the software, itself. From a hardware-design philosophy, that original technology we believed in was using microprocessors to build what we call fat nodes. That is, each node, itself, will be very powerful, with 32 to 64 micros that have large local memories. In fact, in the 1992–1995 time frame, a node will mean multiple processors. How many, I'm not sure, but it will be the latest and greatest processor Intel can produce. The nodes will be very fat and very powerful. The 2000-processor machine will be able to take real advantage of the compiler technology that is being used now. It will still be in the mode where you have to write parallel programs, but you will write it to the node rather than to the processor. Furthermore, the programmer will be free to choose models, algorithms, and tools.
Using this hardware design philosophy, flat interconnects would make it possible for the machine to behave as though it's fully connected, although it is not. Stock processors would be off-the-shelf instead of custom-made microprocessors. Thus, the programmer would get the best chip and software technology. Commodity disks would consist of many inexpensive disks instead of a few expensive ones; they would be cheap and fast enough that the user could ignore disk staging.
If you look at the amount of R&D dollars placed into workstation-and microcomputer-level I/O, it far outweighs the amount of money placed
in any other form of I/O research. Thus, we want to leverage that, just as we are leveraging the R&D placed into the microprocessors.
In hardware design, I started with the hardware and built up to the design philosophy. For software, I will start with the philosophy and work backward.
As I mentioned, there is a necessity for dealing with the latency of messages in that you have to deal fundamentally with the operating system—that is, lightweight operating systems—because we can't pay the expense of dealing with heavyweight processes. To make the machine usable, we are going to have to deal with putting onto the compute nodes themselves the appropriate services, such as layered support for specific programming models, applications, or tools.
We will also need distributed services, such as high-level services through service nodes or across local area networks. UNIX compatibility without space or time overhead will be needed.
If we really are serious about delivering these machines as commercial products, then it is clear that we have to deal with standard languages, such as C and Fortran, with minimal augmentation. So we will have to deliver C, Fortran, and C++ and hope that the programming models won't be too convoluted by matching the appropriate programming model. So far, we seem to have a fairly simple addition to the language: you send something, you receive something, you broadcast something out, you accumulate something in some kind of reduction or global operation, etc.
The last items in software philosophy I want to discuss are interactive parallelization tools. These tools help the programmer restructure for parallel execution. They also allow use of standard languages and, therefore, minimize staff retraining.
I now switch from philosophy to multicomputer software needs. One of the needs is in operating systems improvements. Fortunately, there is a network of people, mostly in the university research area, that is working on multiuser resource management and efficient shared-memory emulation.
Another need is in parallel libraries. Parallel libraries involve mathematical routines, solvers, data management, visualization utilities, etc. However, these machines are too hard to program. When I talk to users about how to program these machines, I find out from optimists that the big problems come from modeling natural phenomena, which results in a great deal of natural parallelism. The reasoning is that because there is all of this natural parallelism, it should be very easy to write parallel
programs. When I talk to the pessimists, the pessimists ask about solving these equations, which requires a certain amount of stability that is very hard to do.
Interestingly, both the optimistic and pessimistic viewpoints are correct. That is, there is a great deal of parallelism in natural phenomena, and when you deal with that part of it, it really is easy to express. But you come up to the part of the problem where the physicist, the financial analyst, or the chemist usually hands it off and goes and looks up the appropriate numerical algorithm for solving the right set of equations or for generating the right set of random numbers for applying the Monte Carlo method or for doing the appropriate transform. It is exactly at that point where it becomes difficult.
This is exactly the point where we are now as a community of designers. If we are going to make these machines usable, we will have to deal with building the libraries. We used to talk about kernels—building the kernels of applications. However, that was a mistake because it is not the kernels that we need but the solvers.
Therefore, to make these machines more usable, we need better solvers, better random-number generators, better transforms, etc. There is a handful of compute-intensive procedures that cause difficulties when the chemist, the physicist, and the financial analyst run into them in their code, and that is the area where we need to apply computer science.
The other reason why these machines are hard to use is the fact that the compilers, the debuggers, and the tools are very young. The problem is not that it is hard to conceptualize the parallelism but that it is hard to deal with these very young tools. I hope we can deal with the hard-to-program problem by dealing with better tools and by building the solvers.
In summary, it's time to face facts. High-performance computing is at the crossroads. Conventional supercomputers are not improving at a fast enough rate to meet our computational needs. Conventional supercomputers have become too costly to develop or own, given their delivered performance. Microprocessor performance will double every two years for at least the next 10 years. Micro-based, ultraperformance multicomputers are the only viable means to achieve the TFLOPS goal.