Symbolic Supercomputing
Alvin Despain
Alvin M. Despain is the Powell Professor of Computer Engineering at the University of Southern California, Los Angeles. He is a pioneer in the study of high-performance computer systems for symbolic calculations. To determine design principles for these systems, his research group builds experimental software and hardware systems, including compilers, custom very-large-scale integration processors, and multiprocessor systems. His research interests include computer architecture, multiprocessor and multicomputer systems, logic programming, and design automation. Dr. Despain received his B.S., M.S., and Ph.D. degrees in electrical engineering from the University of Utah, Salt Lake City.
This presentation discusses a topic that may be remote from the fields most of you at this conference deal in—symbolic, as opposed to numeric, supercomputing. I will define terms and discuss parallelism in symbolic computing and architecture and then draw some conclusions.
If supercomputing is using the highest-performance computers available, then symbolic supercomputing is using the highest-performance symbolic processor systems. Let me show you some symbolic problems and how they differ from numeric ones.
If you're doing the usual supercomputer calculations, you use LINPAC, fast Fourier transforms (FFTs), etc., and you do typical, linear-algebra kinds of operations. In symbolic computing, you use programs like MACSYMA, MAPLE, Mathematica, or PRESS. You provide symbols,
and you get back not numbers but formulae. For example, you get the solution to a polynomial in terms of a formula.
Suppose we have a problem specification—maybe it is to model global climate. This is a big programming problem. After years of effort programming this fluid-dynamics problem, you get a Fortran program. This is then compiled. It is executed with some data, and some results are obtained (e.g., the temperature predicted for the next hundred years). Then the program is generally tuned to achieve both improved results and improved performance.
In the future you might think that you start with the same problem specification and try to reduce the programming effort by automating some of the more mundane tasks. One of the most important things you know is that the programmer had a very good feel for the data and then wired that into the program. If you're going to automate, you're going to have to bring that data into the process.
Parameters that can be propagated within a program constitute the simplest example of adjusting the program to data, but there are lots of other ways, as well. Trace scheduling is one way that this has been done for some supercomputers. You bring the data in and use it to help do a good job of compiling, vectorizing, and so on. This is called partial evaluation because you have part of the data, and you evaluate the program using the data. And this is a symbolic calculation.
If you're going to solve part of the programming problem that we have with supercomputers, you might look toward formal symbolic calculation. Some other cases are optimizing compilers, formal methods, program analysis, abstract interpretation, intelligent databases, design automation, and very-high-level language compilers.
If you look and see how mathematicians solve problems, they don't do it the way we program Cray Research, Inc., machines, do they? They don't do it by massive additions and subtractions. They integrate together both symbolic manipulations and numeric manipulations. Somehow we have to learn how to do that better, too. It is an important challenge for the future. Some of it is happening today, but there's a lot to be done.
I would like to try to characterize some tough problems in the following ways: there is a set of problems that are numeric—partial differential equations, signal processing, FFTs, etc.; there are also optimization problems in which you search for a solution—linear programming, for example, or numerical optimization of various kinds. At the symbolic level you also have simulation. Abstract interpretation is an example. But you also have theorem proving, design automation, expert
systems, and artificial intelligence (AI). Now, these are fundamentally hard problems. In filter calculations (the easy problems), the same execution occurs no matter what data you have. For example, FFT programs will always execute the same way, no matter what data you're using.
With the hard problems, you have to search. Your calculation is a lot more dynamic and a lot more difficult because the calculation does depend upon the data that you happen to have at the time. It is in this area that my work and the work of my group have focused: how you put together symbols and search. And that's what Newell and Simon (1976) called AI, actually. But call it what you like.
I want to talk about two more things: concurrency and parallelism. These are the themes of this particular session. I'd like to talk about the instruction-set architecture, too, because it interacts so strongly with concurrency and parallelism. If you're building a computer, one instruction type is enough, right? You build a Turing machine with one instruction. So that's sufficient, but you don't get performance.
If you want performance, you'd better add more instructions. If you have a numeric processor, you include floating-point add, floating-point multiply, and floating-point divide. If you have a general-purpose processor, you need operations like load, store, jump, add, and subtract. If you want a symbolic processor, you've got to do things like binding two symbols together (binding), dereferencing, unifying, and backtracking. To construct a symbolic processor, you need the general-purpose features and the symbolic operations.
Our latest effort is a single-chip processor called the Berkeley Abstract Machine (BAM). This work has been sponsored by the Defense Advanced Research Projects Agency. For our symbolic language, we have primarily used Prolog, but BAM is not necessarily dependent on it.
Now, I'd like to tell you a little bit about it to illustrate the instructionset architecture issues involved, especially the features of the BAM chip that boost performance. These are the usual general-purpose instructions—load, store, and so on. There's special support for unification. Unification is the most general pattern match you can do. Backtracking is also supported so that you can do searching and then backtrack if you find it wrong. The architecture features include tags, stack management, special registers, and a microstore—that is, internal opcodes. There is pipeline execution to get performance and multiple I/O ports for address, data, and instructions.
In this processor design we considered what it costs to do symbolic calculations in addition to the general-purpose calculations. We selected
a good set of all possible general-purpose instructions to match with the symbolic, and then we added what was needed to get performance.
If you add a feature, you get a corresponding improvement in performance. See Figure 1, which graphs the percentage increase in performance. The cycle count varies between one and two, one being BAM as a benchmark. We took all combinations of features that we could find and with simulation tried to understand what cost-performance tradeoffs can be achieved.
Some cost-performance combinations aren't very good. Others are quite good, and the full combination is quite good. The net result is that an 11 per cent increase in the silicon area of a single-chip microcomputer, BAM, results in a 70 per cent increase in the performance on symbolic calculations. So that's what we chose for BAM. It doesn't cost very much to do the symbolic once you have the general-purpose features.
The BAM chip features 24 internal microinstructions and 62 external ones. It achieves about 1.4 cycles per instruction. However, because of dereferencing, the number of cycles per instruction is indefinitely large. Simulations indicated that the chip would achieve about 24 million instructions per second, or about three million logical inferences per second (i.e., about 3 MLIPS). A logical inference is what you execute for symbolic computing. It's a general pattern match, and if it succeeds, you do a procedure call, execution, and return.
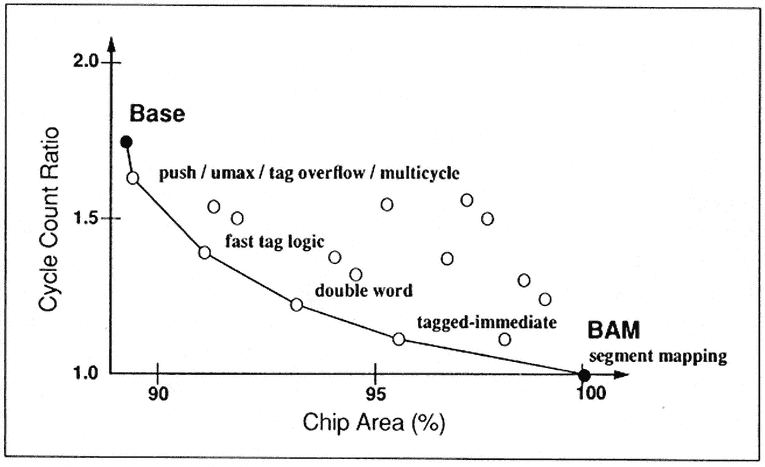
Figure 1.
The benefits of adding architectural features: an 11 per cent increase in silicon area yields a 70 per cent increase in performance.
We submitted this chip for fabrication. The chip has now been tested, and it achieved 3.8 MLIPS.
Consider the performance this represents. Compare, for instance, the Japanese Personal Sequential Inference (PSI) machine, built in 1984. It achieved 30,000 LIPS. A few months later at Berkeley, we built something called the Prolog Machine (PLM), which achieved 300,000 LIPS, even then, a 10-fold improvement. The best the Europeans have done so far is the Knowledge Crunch Machine. It now achieves about 600,000 LIPS.
The best the Japanese have done currently in a single processor is an emitter-coupled-logic machine, 64-bit-wide data path, and it achieved a little over an MLIPS, compared with BAM's 3.8 MLIPS. So the net result of all of this is that we've been able to demonstrate in six years' time a 100-fold improvement in performance in this domain.
The PLM was put into a single chip, just as BAM is a single chip. The PSI was not; it was a multiple-chip system. I think what's important is that you really have to go after the technology. You must also optimize the microarchitecture, the instruction-set architecture, and especially the compiler. Architecture design makes a big difference in performance; it's not a dead issue. And architecture, technology, and compilers all have to be developed together to get these performance levels.
Let me say something about scaling and the multiprocessor. What about parallelism? Supercomputers have many levels of parallelism—parallel digital circuits at the bottom level, microexecution, multiple execution per instruction, multiple instruction streams, multiprocessing, shared-memory multiprocessors, and then heterogeneous multiprocessors at the top. And we've investigated how symbolic calculations play across this whole spectrum of parallelism. If you really want performance, you have to play the game at all these different levels of the hierarchy. It turns out that parallelism is more difficult to achieve in symbolic calculations. This is due to the dynamic, unpredictable nature of the calculation. But on the plus side, you get, for instance, something called superlinear speedup during search.
But as in numerics, the symbolic algorithms that are easy to parallelize turn out to be poor in performance. We all know that phenomenon, and it happens here, too. But there are some special cases that sometimes work out extremely well. What we're trying to do with BAM is identify different types of parallel execution so that you can do something special about each type. BAM handles very well the kind of parallelism requiring you to break a problem into pieces and solve all the pieces simultaneously. With BAM, parallelism can spread across networks, so
you have all-solution, or-parallelism, where you find a whole set of answers to a problem rather than just one.
However, if you're doing a design, all you want is one good design. You don't want every possible design. There are too many to enumerate. And that's been our interest, and it works pretty well on multiprocessors. Unification parallelism, pattern matching, can be done in parallel, and we do some of that within the processor.
Now, let's say you have a BAM chip and a shared-memory cache with the switch and connections to some external bus memory and I/O. Call that a node. Put that together with busses into what we call multi-multi.
Gordon Bell (1985), a Session 8 presenter, wrote a great paper, called "Multis: A New Class of Multiprocessor Computers," about a shared-memory, single-bus system. It turns out you can do the same trick in multiple dimensions and have yourself a very-large-scale, shared-memory, shared-address-space multiprocessor, and it looks like that's going to work. We'll find out as we do our work.
I think that for a modest cost, you can add powerful symbolic capability to a general-purpose machine. That's one of the things we've learned very recently.
Parallel symbolic execution is still a tough problem, and there is still much to be learned. The ultimate goal is to learn how to couple efficiently, in parallel, both symbolic and numeric calculations.
References
C. G. Bell, "Multis: A New Class of Multiprocessor Computers," Science288, 462-467 (1985).
A. Newell and H. Simon, "Computer Science as Empirical Inquiry; Symbols and Search," Communications of the ACM19 (3), 113-126 (1976).