4—
SCALABLE PARALLEL SYSTEMS
This session focused on the promise and limitations of ![]() architectures
architectures ![]() that feature a large number of homogeneous or heterogeneous processing elements. Panelists discussed the limitations, dependencies, sustained performance potential, processor performance, interconnection topologies, and application domains for such
that feature a large number of homogeneous or heterogeneous processing elements. Panelists discussed the limitations, dependencies, sustained performance potential, processor performance, interconnection topologies, and application domains for such ![]() architectures
architectures ![]() .
.
Session Chair
Stephen Squires,
Defense Advanced Research Projects Agency
Symbolic Supercomputing
Alvin Despain
Alvin M. Despain is the Powell Professor of Computer Engineering at the University of Southern California, Los Angeles. He is a pioneer in the study of high-performance computer systems for symbolic calculations. To determine design principles for these systems, his research group builds experimental software and hardware systems, including compilers, custom very-large-scale integration processors, and multiprocessor systems. His research interests include computer ![]() architecture
architecture ![]() , multiprocessor and multicomputer systems, logic programming, and design automation. Dr. Despain received his B.S., M.S., and Ph.D. degrees in electrical engineering from the University of Utah, Salt Lake City.
, multiprocessor and multicomputer systems, logic programming, and design automation. Dr. Despain received his B.S., M.S., and Ph.D. degrees in electrical engineering from the University of Utah, Salt Lake City.
This presentation discusses a topic that may be remote from the fields most of you at this conference deal in—symbolic, as opposed to numeric, supercomputing. I will define terms and discuss parallelism in symbolic computing and ![]() architecture
architecture ![]() and then draw some conclusions.
and then draw some conclusions.
If supercomputing is using the highest-performance computers available, then symbolic supercomputing is using the highest-performance symbolic processor systems. Let me show you some symbolic problems and how they differ from numeric ones.
If you're doing the usual supercomputer calculations, you use LINPAC, fast Fourier transforms (FFTs), etc., and you do typical, linear-algebra kinds of operations. In symbolic computing, you use programs like MACSYMA, MAPLE, Mathematica, or PRESS. You provide symbols,
and you get back not numbers but formulae. For example, you get the solution to a polynomial in terms of a formula.
Suppose we have a problem specification—maybe it is to model global climate. This is a big programming problem. After years of effort programming this fluid-dynamics problem, you get a Fortran program. This is then compiled. It is executed with some data, and some results are obtained (e.g., the temperature predicted for the next hundred years). Then the program is generally tuned to achieve both improved results and improved performance.
In the future you might think that you start with the same problem specification and try to reduce the programming effort by automating some of the more mundane tasks. One of the most important things you know is that the programmer had a very good feel for the data and then wired that into the program. If you're going to automate, you're going to have to bring that data into the process.
Parameters that can be propagated within a program constitute the simplest example of adjusting the program to data, but there are lots of other ways, as well. Trace scheduling is one way that this has been done for some supercomputers. You bring the data in and use it to help do a good job of compiling, vectorizing, and so on. This is called partial evaluation because you have part of the data, and you evaluate the program using the data. And this is a symbolic calculation.
If you're going to solve part of the programming problem that we have with supercomputers, you might look toward formal symbolic calculation. Some other cases are optimizing compilers, formal methods, program analysis, abstract interpretation, intelligent databases, design automation, and very-high-level language compilers.
If you look and see how mathematicians solve problems, they don't do it the way we program Cray Research, Inc., machines, do they? They don't do it by massive additions and subtractions. They integrate together both symbolic manipulations and numeric manipulations. Somehow we have to learn how to do that better, too. It is an important challenge for the future. Some of it is happening today, but there's a lot to be done.
I would like to try to characterize some tough problems in the following ways: there is a set of problems that are numeric—partial differential equations, signal processing, FFTs, etc.; there are also optimization problems in which you search for a solution—linear programming, for example, or numerical optimization of various kinds. At the symbolic level you also have simulation. Abstract interpretation is an example. But you also have theorem proving, design automation, expert
systems, and artificial intelligence (AI). Now, these are fundamentally hard problems. In filter calculations (the easy problems), the same execution occurs no matter what data you have. For example, FFT programs will always execute the same way, no matter what data you're using.
With the hard problems, you have to search. Your calculation is a lot more dynamic and a lot more difficult because the calculation does depend upon the data that you happen to have at the time. It is in this area that my work and the work of my group have focused: how you put together symbols and search. And that's what Newell and Simon (1976) called AI, actually. But call it what you like.
I want to talk about two more things: concurrency and parallelism. These are the themes of this particular session. I'd like to talk about the instruction-set ![]() architecture
architecture ![]() , too, because it interacts so strongly with concurrency and parallelism. If you're building a computer, one instruction type is enough, right? You build a Turing machine with one instruction. So that's sufficient, but you don't get performance.
, too, because it interacts so strongly with concurrency and parallelism. If you're building a computer, one instruction type is enough, right? You build a Turing machine with one instruction. So that's sufficient, but you don't get performance.
If you want performance, you'd better add more instructions. If you have a numeric processor, you include floating-point add, floating-point multiply, and floating-point divide. If you have a general-purpose processor, you need operations like load, store, jump, add, and subtract. If you want a symbolic processor, you've got to do things like binding two symbols together (binding), dereferencing, unifying, and backtracking. To construct a symbolic processor, you need the general-purpose features and the symbolic operations.
Our latest effort is a single-chip processor called the Berkeley Abstract Machine (BAM). This work has been sponsored by the Defense Advanced Research Projects Agency. For our symbolic language, we have primarily used Prolog, but BAM is not necessarily dependent on it.
Now, I'd like to tell you a little bit about it to illustrate the instructionset ![]() architecture
architecture ![]() issues involved, especially the features of the BAM chip that boost performance. These are the usual general-purpose instructions—load, store, and so on. There's special support for unification. Unification is the most general pattern match you can do. Backtracking is also supported so that you can do searching and then backtrack if you find it wrong. The
issues involved, especially the features of the BAM chip that boost performance. These are the usual general-purpose instructions—load, store, and so on. There's special support for unification. Unification is the most general pattern match you can do. Backtracking is also supported so that you can do searching and then backtrack if you find it wrong. The ![]() architecture
architecture ![]() features include tags, stack management, special registers, and a microstore—that is, internal opcodes. There is pipeline execution to get performance and multiple I/O ports for address, data, and instructions.
features include tags, stack management, special registers, and a microstore—that is, internal opcodes. There is pipeline execution to get performance and multiple I/O ports for address, data, and instructions.
In this processor design we considered what it costs to do symbolic calculations in addition to the general-purpose calculations. We selected
a good set of all possible general-purpose instructions to match with the symbolic, and then we added what was needed to get performance.
If you add a feature, you get a corresponding improvement in performance. See Figure 1, which graphs the percentage increase in performance. The cycle count varies between one and two, one being BAM as a benchmark. We took all combinations of features that we could find and with simulation tried to understand what cost-performance tradeoffs can be achieved.
Some cost-performance combinations aren't very good. Others are quite good, and the full combination is quite good. The net result is that an 11 per cent increase in the silicon area of a single-chip microcomputer, BAM, results in a 70 per cent increase in the performance on symbolic calculations. So that's what we chose for BAM. It doesn't cost very much to do the symbolic once you have the general-purpose features.
The BAM chip features 24 internal microinstructions and 62 external ones. It achieves about 1.4 cycles per instruction. However, because of dereferencing, the number of cycles per instruction is indefinitely large. Simulations indicated that the chip would achieve about 24 million instructions per second, or about three million logical inferences per second (i.e., about 3 MLIPS). A logical inference is what you execute for symbolic computing. It's a general pattern match, and if it succeeds, you do a procedure call, execution, and return.
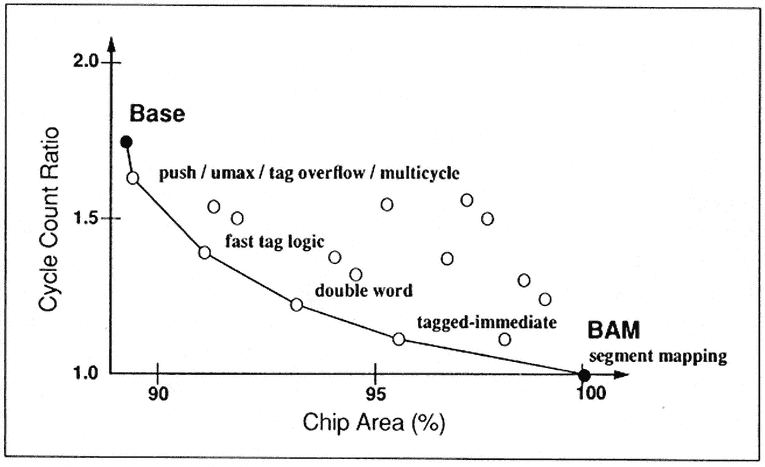
Figure 1.
The benefits of adding architectural features: an 11 per cent increase in silicon area yields a 70 per cent increase in performance.
We submitted this chip for fabrication. The chip has now been tested, and it achieved 3.8 MLIPS.
Consider the performance this represents. Compare, for instance, the Japanese Personal Sequential Inference (PSI) machine, built in 1984. It achieved 30,000 LIPS. A few months later at Berkeley, we built something called the Prolog Machine (PLM), which achieved 300,000 LIPS, even then, a 10-fold improvement. The best the Europeans have done so far is the Knowledge Crunch Machine. It now achieves about 600,000 LIPS.
The best the Japanese have done currently in a single processor is an emitter-coupled-logic machine, 64-bit-wide data path, and it achieved a little over an MLIPS, compared with BAM's 3.8 MLIPS. So the net result of all of this is that we've been able to demonstrate in six years' time a 100-fold improvement in performance in this domain.
The PLM was put into a single chip, just as BAM is a single chip. The PSI was not; it was a multiple-chip system. I think what's important is that you really have to go after the technology. You must also optimize the microarchitecture, the instruction-set ![]() architecture
architecture ![]() , and especially the compiler.
, and especially the compiler. ![]() Architecture
Architecture ![]() design makes a big difference in performance; it's not a dead issue. And
design makes a big difference in performance; it's not a dead issue. And ![]() architecture
architecture ![]() , technology, and compilers all have to be developed together to get these performance levels.
, technology, and compilers all have to be developed together to get these performance levels.
Let me say something about scaling and the multiprocessor. What about parallelism? Supercomputers have many levels of parallelism—parallel digital circuits at the bottom level, microexecution, multiple execution per instruction, multiple instruction streams, multiprocessing, shared-memory multiprocessors, and then heterogeneous multiprocessors at the top. And we've investigated how symbolic calculations play across this whole spectrum of parallelism. If you really want performance, you have to play the game at all these different levels of the hierarchy. It turns out that parallelism is more difficult to achieve in symbolic calculations. This is due to the dynamic, unpredictable nature of the calculation. But on the plus side, you get, for instance, something called superlinear speedup during search.
But as in numerics, the symbolic algorithms that are easy to parallelize turn out to be poor in performance. We all know that phenomenon, and it happens here, too. But there are some special cases that sometimes work out extremely well. What we're trying to do with BAM is identify different types of parallel execution so that you can do something special about each type. BAM handles very well the kind of parallelism requiring you to break a problem into pieces and solve all the pieces simultaneously. With BAM, parallelism can spread across networks, so
you have all-solution, or-parallelism, where you find a whole set of answers to a problem rather than just one.
However, if you're doing a design, all you want is one good design. You don't want every possible design. There are too many to enumerate. And that's been our interest, and it works pretty well on multiprocessors. Unification parallelism, pattern matching, can be done in parallel, and we do some of that within the processor.
Now, let's say you have a BAM chip and a shared-memory cache with the switch and connections to some external bus memory and I/O. Call that a node. Put that together with busses into what we call multi-multi.
Gordon Bell (1985), a Session 8 presenter, wrote a great paper, called "Multis: A New Class of Multiprocessor Computers," about a shared-memory, single-bus system. It turns out you can do the same trick in multiple dimensions and have yourself a very-large-scale, shared-memory, shared-address-space multiprocessor, and it looks like that's going to work. We'll find out as we do our work.
I think that for a modest cost, you can add powerful symbolic capability to a general-purpose machine. That's one of the things we've learned very recently.
Parallel symbolic execution is still a tough problem, and there is still much to be learned. The ultimate goal is to learn how to couple efficiently, in parallel, both symbolic and numeric calculations.
References
C. G. Bell, "Multis: A New Class of Multiprocessor Computers," Science288, 462-467 (1985).
A. Newell and H. Simon, "Computer Science as Empirical Inquiry; Symbols and Search," Communications of the ACM19 (3), 113-126 (1976).
Parallel Processing:
Moving into the Mainstream
H. T. Kung
H. T. Kung joined the faculty of Carnegie Mellon University in 1974, after receiving his Ph.D. there. Since 1992 he has been serving as the Gordon McKay Professor of Electrical Engineering and Computer Science at Harvard University. During a transition period, he continues his involvement with projects under way at Carnegie Mellon. Dr. Kung's research interests are in high-speed networks, parallel-computer ![]() architectures
architectures ![]() , and the interplay between computer and telecommunications systems. Together with his students, he pioneered the concept of systolic-array processing. This effort recently culminated in the commercial release by Intel Supercomputer Systems Division of the iWarp parallel computer.
, and the interplay between computer and telecommunications systems. Together with his students, he pioneered the concept of systolic-array processing. This effort recently culminated in the commercial release by Intel Supercomputer Systems Division of the iWarp parallel computer.
In the area of networks, Dr. Kung's team has developed the Nectar System, which uses fiber-optic links and large crossbar switches. A prototype system employing 100 megabits/second links and more than 20 hosts has been operational since early 1989. The team is currently working with industry on the next-generation Nectar, which will employ fibers operating at gigabits/second rates. The gigabit Nectar is one of the five testbeds in a current national effort to develop gigabits/second wide-area networks. His current network research is directed toward gigabit, cell-based local-area networks capable of guaranteeing performance.
I will focus on three key issues in parallel processing: computation models, interprocessor communication, and system integration. These issues are important in moving parallel processing into the mainstream of computing. To illustrate my points, I will draw on examples from the systems we are building at Carnegie Mellon University—iWarp and Nectar. iWarp is a fine-grain parallel machine developed under a joint project with Intel. Nectar is a network backplane that connects different kinds of machines together.
In discussing computation models, we are really trying to address some of the most difficult problems that people are having with parallel computers. Namely, it can be very difficult to write code for these machines, and the applications codes are not portable between parallel machines or between sequential machines and parallel machines. That has been very troublesome.
There have been attempts to solve these problems. For example, some theoretically oriented researchers have come up with the PRAM model, which presents to the user a parallel computation model that hides almost all the properties of a parallel machine. However, because of its high degrees of generality and transparency, the PRAM model does not exploit useful properties such as the locality or regularity that we worked on so diligently for the last 30 years in order to achieve high-performance computing. What we want is more specialized models—in the beginning, at least.
Therefore, I propose to work on those models that users really understand. For example, one thing we have been doing is that, for each specific area for which we have a good understanding of its computation characteristics, we will develop a parallelizing compiler, although we do not call it a compiler because it is not so general purpose. Instead, we call it a parallel program generator (Figure 1). We start with the specifications, without any detailed knowledge about the underlying parallel machines. Then we have a compiler that will generate code for the specific parallel machines that would have SEND and RECEIVE instructions. So the users can work on a high level in a machine-independent manner.
A concrete example is the APPLY compiler, or parallel program generator (Figure 2) used for many image-processing computations defined in terms of localized operations. That is, each output pixel depends on the small neighborhoods of the corresponding input pixel. In APPLY, the software can generate code for each processor and also do the boundary operations, all automatically.

Figure 1.
Parallel program generators for special computation models.

Figure 2.
APPLY: a parallel program generator for data parallelism using local operators.
Currently APPLY is operational for Warp, iWarp, Transputers, and a couple of other machines. Actually, it generates code for sequential machines, as well. So you can develop your APPLY programs in a comfortable environment of a sequential machine. Intel is going to support APPLY for the iWarp.
Another program generator developed by Carnegie Mellon is called AL, which will generate matrix operations automatically. Actually, we generate much of the LINPACK code on Warp using this language. The language basically is like Fortran but allows hints to the compiler about roughly how arrays should be partitioned, e.g., in certain directions, onto a parallel machine. Then the code for the specific parallel machine will be generated automatically.
We also have a very high-level parallel program generator, called ASSIGN, for large signal flow graphs with nodes that are signal processing operations like fast Fourier transforms, filters, and so on (Figure 3). You just use the fact that there are so many graph nodes that you have to deal with; as a result, you usually can load balance them by mapping an appropriate number of graph nodes onto each processor. Again, this mapping has been done automatically.
One of the most difficult things, so far, for a parallel machine to handle is branch-and-bound types of operations (Figure 4), which are similar to searching a tree, for example. In this type of operation you do a lot of backtracking, which can depend on the computation you are doing at run time. For example, you might sometimes like to go deep so that you can do a useful operation, but you also want to go breadth so that you can increase concurrency. Usually only the user has this rough idea of what the priority is between the depth-first and the breadth-first search. Yet, today we do not even have languages that can express that idea. Even if the user knows that you should go depth a little before you go breadth, we still do not know how to say it to the parallel machine. So we are pretty far away from having a general computation model.
A strategy that I propose is to gain experience in a few computation models for special application areas. At the same time, we should develop insights for the more general models.
The second key issue in parallel processing is interprocessor communication. After all, parallel machines are about communications between different processors. A lot of the parallel machines that people have today are really built out of processing elements that are not good for communication. As a result, some vendors are telling people that their parallel machines are great—but only if you don't communicate!
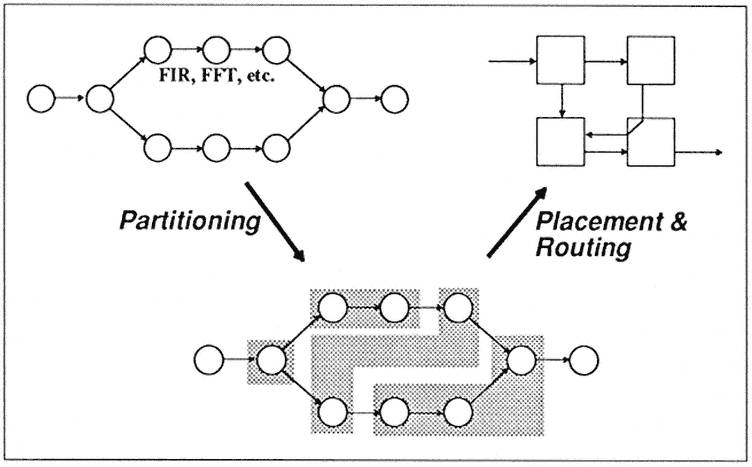
Figure 3.
ASSIGN: a parallel program generator for signal flow graphs.
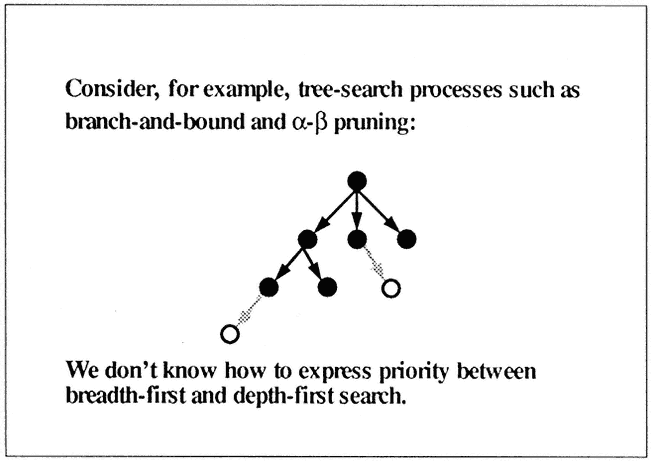
Figure 4.
General models are not quite there yet.
We are trying to make a processor that is good for computation and good for communication. In the case of iWarp, you can build a single component with communication and computation on the same chip, and then you can use this component to form different parallel processing arrays (Figure 5). Once you have such a processor array, you can program each single cell using C and Fortran in the conventional manner. Then you can use parallelizing compilers, or parallel program generators as described above, to generate parallel code for the array.
The iWarp component itself has both a computation and communication agent (Figure 6). Most significant is that the communication part of the chip can do a total of 320 megabytes/second I/O, whereas other current components can do no more than 10 megabytes/second. In addition, we have 160 megabytes/second I/O for the local memory. If you add them up, that is 480 megabytes/second in the current version.
iWarp has three unique innovations in communication: high-bandwidth I/O, systolic communication, and logical channels.
Obviously, in any parallel machine, you have got to be good in I/O because you have got to be able, at least, to get the input data quickly. For example, if you have a high-performance parallel interface (HIPPI) channel with a 100 megabytes/second I/O bandwidth, you can probably get an interface of such bandwidth into the array (see Figure 7). The challenge, however, will be how to distribute the input data onto multiple
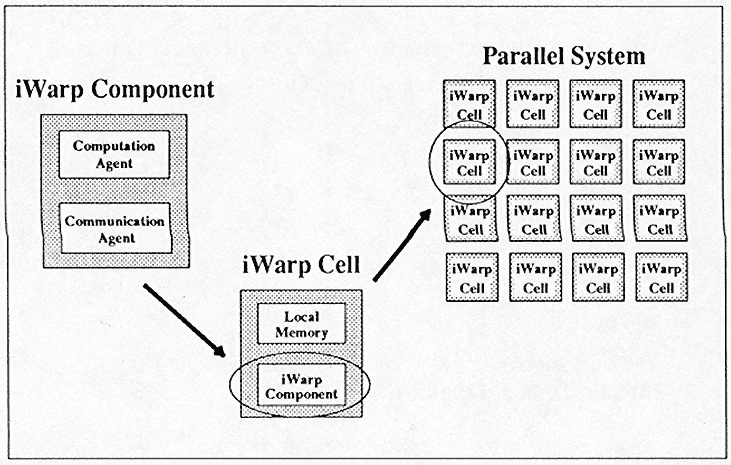
Figure 5.
iWarp: a VLSI building block for parallel systems.
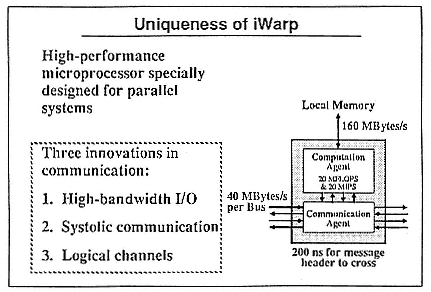
Figure 6.
A single-chip component capable of 480 megabytes/second I/O.
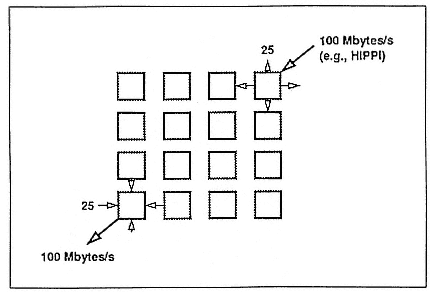
Figure 7.
High-bandwidth distribution and collection of data in processor array.
processing elements. For this distribution we need a large I/O bandwidth per processor element.
For iWarp we have eight links, and each of them is 40 megabytes/second. In particular, we can simultaneously use four links each at 25 megabytes/second to distribute a 100 megabyte/second input in parallel and another four links to distribute the 100 megabyte/second output.
Besides the I/O bandwidth, the other important thing about each processor is easy and direct access to I/O. This is done in iWarp through the systolic communication mechanism. Figure 8 compares systolic communication with the traditional memory-based, message-passing communication.
One of the things that any parallel machine should do well is to distribute an array—say, a row of an image into a number of processing elements. In iWarp a processor can send out a row in a single message to many other processing elements and have the first processing element take one end of the row (Figure 9). Then the first processor can change the message header, redirect the rest of the message to go into the second processing element, and so on. Note that the sender only needs to send out one message to distribute the data to many other processors.
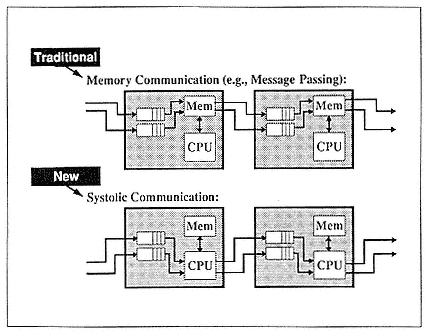
Figure 8.
Systolic communications in iWarp.
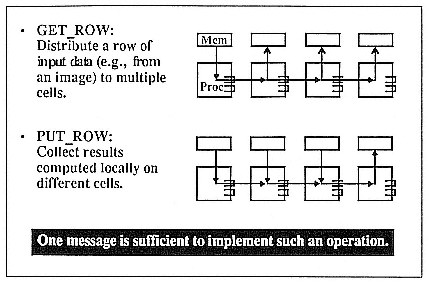
Figure 9.
Message redirection in iWarp.
Logical channels are an important concern. No matter how many pins or how many connectors you have, you never have enough to support some applications. People always want more connectivity so that they can map the computation on the parallel machine easily and so that they can do a reconfiguration of the parallel-processor array more easily. Therefore, it is very useful to time-multiplex the wire by using hardware support so that logically you can imagine having many, many wires instead of having one physical wire.
For iWarp we can have 20 logical connections in and out from each chip. For example, we can have both blue and red connections happening at the same time. A programmer can use the blue connection for some computation. In the meantime, the system message can always go on using the red connection without being blocked by the programmer's computation. Therefore, you can reserve some bandwidth logically for system use (Figure 10). Once you have these kinds of logical connections, you will also find it very easy to reconfigure a processor array. For example, to avoid a faulty node, you can just route it around using logical connections. Because you have so many logical connections available, the routing will be easy.
The message here is that although we have already seen some successful parallel machines, we have not yet seen the really good parallel
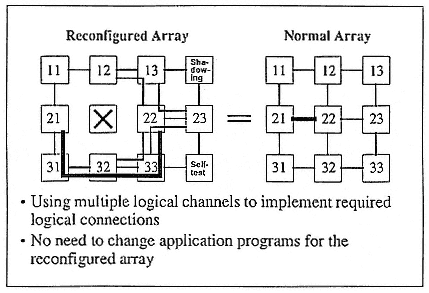
Figure 10.
Reconfiguration for fault tolerance: an application of logical channels.
machine that would support many very basic interprocessor communication operations that applications will typically need. In the future, parallel machines built out of processing building blocks that inherently support efficient and flexible interprocessor communication will be much easier to use.
The last key issue in parallel processing I will address is system integration. Parallel machines are not suited for sequential operations, by definition. Thus, parallel machines typically need to be integrated in a general computing environment. The more powerful a machine is, the more accessible it ought to be. Ideally, all of these computers should be connected together. Actually, this kind of configuration is happening in almost all high-performance computing sites (Figure 11).
At Carnegie Mellon, we are building such a network-based high-performance computing system, called Nectar (Figure 12). Nectar has a general network that supports very flexible, yet high-bandwidth and low-latency, communication. The Nectar demo system (Figure 13) connects about 26 hosts. Currently, we can do interhost communication at about 100 megabits/second, with a latency of about 170 microseconds. Nectar supports transmission control protocol/Internet protocol (TCP/IP). If TCP checksum is turned out, the CAB-to-CAB (i.e., without
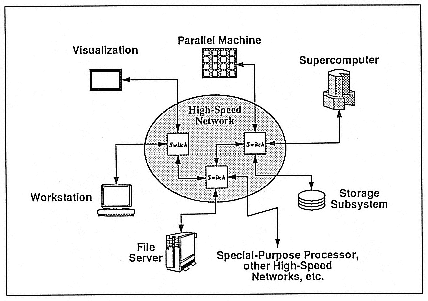
Figure 11.
Accessibility in a general-computing environment.
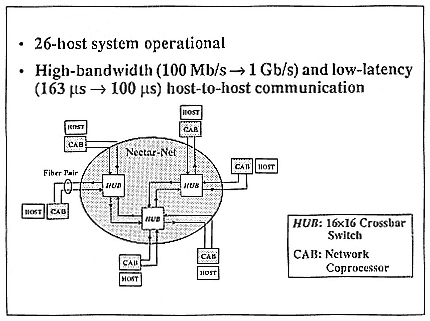
Figure 12.
The Nectar System at Carnegie Mellon University.
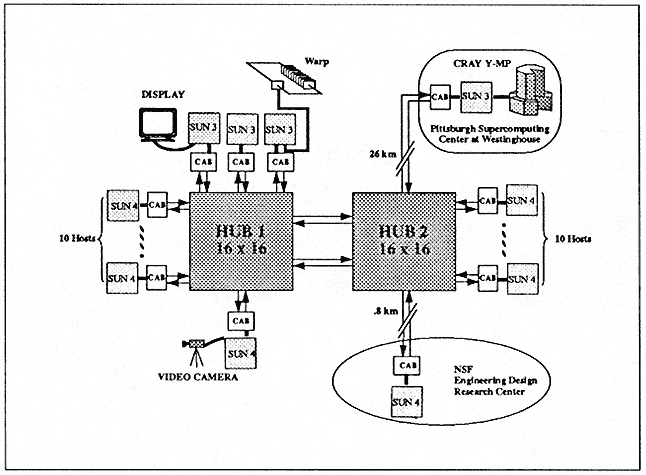
Figure 13.
Host Nectar demo system (May 1990).
crossing the host VME bus) TCP/IP bandwidth can be close to the peak link bandwidth of 100 megabits/second for large packets of 32 kilobytes. It's reasonable to consider the case where TCP checksum is turned off because this checksum can be easily implemented in hardware in the future.
We believe that over the next 18 months, we can build a Nectar-like system with much improved performance. In particular, we're building a HIPPI Nectar, which will support the 800 megabits/second HIPPI channels. For TCP/IP, the goal is to achieve at least 300 megabits/second bandwidth. With Bellcore we are also working on an interface between HIPPI networks and telecommunication ATM/SONET networks.
Figure 14 shows a network-based multicomputer configuration that we proposed about six months ago. With this kind of a network, you can literally have a system capable of 1011 or even 1012 floating-point operations per second, without even building any new machines.
In summary, at Carnegie Mellon we are making progress on the key issues in parallel processing that I have discussed.
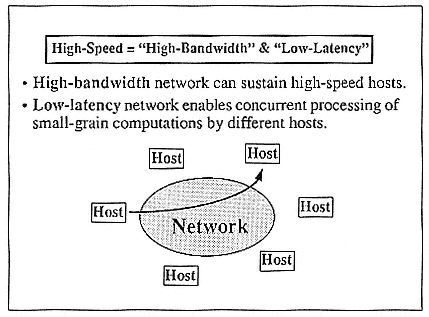
Figure 14.
High-speed networks make high-performance computing over network feasible.
It's Time to Face Facts
Joe Brandenburg
Joe Brandenburg is manager of the Computational Sciences Group at Intel Supercomputer Systems Division. He is an expert in parallel programming, having applied his expertise to the fields of artificial intelligence, finance, and general high-performance computing and ![]() architectures
architectures ![]() . He received a Ph.D. in mathematics from the University of Oregon in 1980 and an M.S. in computer science from the University of Maryland in 1983. He has been a member of the technical staff at Intel since 1985.
. He received a Ph.D. in mathematics from the University of Oregon in 1980 and an M.S. in computer science from the University of Maryland in 1983. He has been a member of the technical staff at Intel since 1985.
I am sure that everyone is aware of the efforts of Intel in the last five years in building parallel processors. We started out with what was really a toy in order to learn something about writing parallel programs, and then we developed a machine that was actually competitive with minis and mainframes. We now have a machine that does compete with supercomputers, with the goal to build what we are starting to call ultracomputers. We want to go beyond the supercomputer type of machine.
We see the building of these kinds of computers—these high-performance computers—as having lots of pieces, all of which I will not be able to discuss here. Fundamentally, in building these types of machines, we have to deal with the processor, the memory, and the interconnection hardware. We have to deal with the operating system, the compilers, and the actual software needed for the applications.
Let me begin by discussing building a machine that is capable of 1012 floating-point operations per second (TFLOPS) and that is based on traditional supercomputing methods. If I take today's supercomputing capabilities—that is, an MFLOPS processor, approximately a GFLOPS machine—and want to build a TFLOPS machine, I'd have to have 1000 processors put together (Figure 1). Of course, we don't really know how to do that today, but that would be what it would take. If I want to build it in a 10-year time frame, I still am going to have to put together hundreds of these supercomputers—traditional kinds of CPUs. That is not going to be easy, and it is not going to be cheap.
If I want to build a TFLOPS machine with the microprocessors and I want to do that today, I'd have to put together some 10,000 processors (Figure 2). By the year 1995, that would be 3000 or 4000 of these processors, and by the year 2000, I'd need only 1000 processors.
Today we know how to put together hundreds of these things. We believe that within a couple of years, we will be producing machines that have thousands of processors, and therefore in the year 2000, we will definitely be able to put together 1000 of these machines. That will actually be a step backward for us. From a processor point of view, that means we can achieve TFLOPS performance if we concentrate on using stock, off-the-shelf microprocessors.
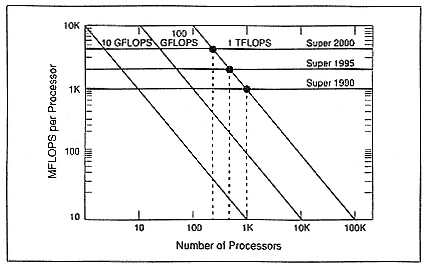
Figure 1.
Achieving TFLOPS performance with traditional supercomputers (parallelism
versus processor speed).
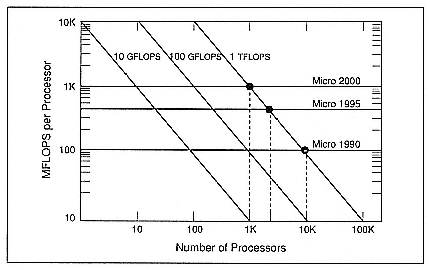
Figure 2.
Achieving TFLOPS performance with micro-based multicomputers (parallelism
versus processor speed).
We will have to be able to make all of these machines talk with each other, so we have to deal with the interconnectivity, which will mean that we will have to concentrate on building the appropriate interconnectivity. We will need to take the type of the research that has been done over the last few years at places like Caltech and actually put into a higher and higher silicon the necessary connections to move the bytes into the 40-, 50-, and 100-megabyte-per-channel networks and, with them, build the scalable interconnection networks. There are now known technology paths that can get us to the appropriate level of support for building the interconnections that will provide sufficient hardware bandwidth and for moving messages between these machines (Figure 3).
That leaves us, then, with the problem of making sure we can then get the messages out the door fast enough, that is, the latency issue of the time it takes to set a message up, push it out, and bring it back. That problem is solved with a combination of having good interfaces between the processors and building good ![]() architecture
architecture ![]() on the nodes. In addition, you need very lightweight operating systems so that you won't have to pay a large software overhead. If we carefully build these systems, we will be able to support both MIMD and single-processor, multiple-data
on the nodes. In addition, you need very lightweight operating systems so that you won't have to pay a large software overhead. If we carefully build these systems, we will be able to support both MIMD and single-processor, multiple-data ![]() architectures
architectures ![]() .
.
The Touchstone program is a joint project of Intel and the Defense Advanced Research Projects Agency to develop a series of prototypes of
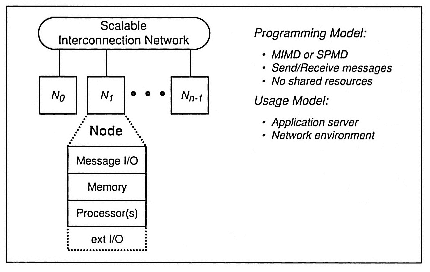
Figure 3.
Message-passing multicomputers (scalable parallel computing systems).
these machines (Figure 4). It is Intel's responsibility to commercialize products out of that. The first machine, Iota, was actually the add-I/O capability to our second-generation iPSC. The next step was to add a higher-performance microprocessor to prove the theory that we can continue to leverage the overall technologies we develop by placing a new processor each time. The Gamma project is based, essentially, on the Intel i860.
Delta was scheduled for September 1990 but has been delayed until September 1991. The idea behind Delta is to use the same essential processor but to raise the number of nodes. To match the processing with the communication, we have to go to a new generation of communications. From a hardware point of view, the Gamma step is to go to the i860 processor; the Delta step is to go to these higher-performance networks.
Sigma will be the final prototype in this particular project, which will go to 2000 processors, again based on the same kind of interconnect but with high performance. The latest Intel process technology is to build the writing chips. Perhaps the most significant advance for Sigma is the packaging issues. That is, we will have to handle 2000 processors and find ways of applying packaging technologies so that we can fit them into a package no bigger than that which contains the 512-processor Delta machine. Thus, a series of processor machines, interconnects, and
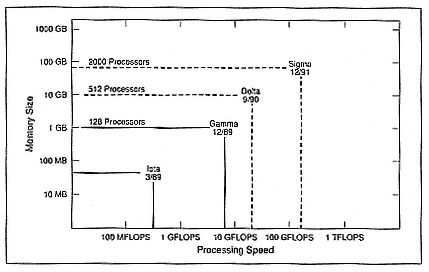
Figure 4.
Touchstone prototypes (processing speed versus memory size).
packaging will culminate in what should be a 500-GFLOPS machine by the year 1992.
We now realize we need to put much more effort into the software, itself. From a hardware-design philosophy, that original technology we believed in was using microprocessors to build what we call fat nodes. That is, each node, itself, will be very powerful, with 32 to 64 micros that have large local memories. In fact, in the 1992–1995 time frame, a node will mean multiple processors. How many, I'm not sure, but it will be the latest and greatest processor Intel can produce. The nodes will be very fat and very powerful. The 2000-processor machine will be able to take real advantage of the compiler technology that is being used now. It will still be in the mode where you have to write parallel programs, but you will write it to the node rather than to the processor. Furthermore, the programmer will be free to choose models, algorithms, and tools.
Using this hardware design philosophy, flat interconnects would make it possible for the machine to behave as though it's fully connected, although it is not. Stock processors would be off-the-shelf instead of custom-made microprocessors. Thus, the programmer would get the best chip and software technology. Commodity disks would consist of many inexpensive disks instead of a few expensive ones; they would be cheap and fast enough that the user could ignore disk staging.
If you look at the amount of R&D dollars placed into workstation-and microcomputer-level I/O, it far outweighs the amount of money placed
in any other form of I/O research. Thus, we want to leverage that, just as we are leveraging the R&D placed into the microprocessors.
In hardware design, I started with the hardware and built up to the design philosophy. For software, I will start with the philosophy and work backward.
As I mentioned, there is a necessity for dealing with the latency of messages in that you have to deal fundamentally with the operating system—that is, lightweight operating systems—because we can't pay the expense of dealing with heavyweight processes. To make the machine usable, we are going to have to deal with putting onto the compute nodes themselves the appropriate services, such as layered support for specific programming models, applications, or tools.
We will also need distributed services, such as high-level services through service nodes or across local area networks. UNIX compatibility without space or time overhead will be needed.
If we really are serious about delivering these machines as commercial products, then it is clear that we have to deal with standard languages, such as C and Fortran, with minimal augmentation. So we will have to deliver C, Fortran, and C++ and hope that the programming models won't be too convoluted by matching the appropriate programming model. So far, we seem to have a fairly simple addition to the language: you send something, you receive something, you broadcast something out, you accumulate something in some kind of reduction or global operation, etc.
The last items in software philosophy I want to discuss are interactive parallelization tools. These tools help the programmer restructure for parallel execution. They also allow use of standard languages and, therefore, minimize staff retraining.
I now switch from philosophy to multicomputer software needs. One of the needs is in operating systems improvements. Fortunately, there is a network of people, mostly in the university research area, that is working on multiuser resource management and efficient shared-memory emulation.
Another need is in parallel libraries. Parallel libraries involve mathematical routines, solvers, data management, visualization utilities, etc. However, these machines are too hard to program. When I talk to users about how to program these machines, I find out from optimists that the big problems come from modeling natural phenomena, which results in a great deal of natural parallelism. The reasoning is that because there is all of this natural parallelism, it should be very easy to write parallel
programs. When I talk to the pessimists, the pessimists ask about solving these equations, which requires a certain amount of stability that is very hard to do.
Interestingly, both the optimistic and pessimistic viewpoints are correct. That is, there is a great deal of parallelism in natural phenomena, and when you deal with that part of it, it really is easy to express. But you come up to the part of the problem where the physicist, the financial analyst, or the chemist usually hands it off and goes and looks up the appropriate numerical algorithm for solving the right set of equations or for generating the right set of random numbers for applying the Monte Carlo method or for doing the appropriate transform. It is exactly at that point where it becomes difficult.
This is exactly the point where we are now as a community of designers. If we are going to make these machines usable, we will have to deal with building the libraries. We used to talk about kernels—building the kernels of applications. However, that was a mistake because it is not the kernels that we need but the solvers.
Therefore, to make these machines more usable, we need better solvers, better random-number generators, better transforms, etc. There is a handful of compute-intensive procedures that cause difficulties when the chemist, the physicist, and the financial analyst run into them in their code, and that is the area where we need to apply computer science.
The other reason why these machines are hard to use is the fact that the compilers, the debuggers, and the tools are very young. The problem is not that it is hard to conceptualize the parallelism but that it is hard to deal with these very young tools. I hope we can deal with the hard-to-program problem by dealing with better tools and by building the solvers.
In summary, it's time to face facts. High-performance computing is at the crossroads. Conventional supercomputers are not improving at a fast enough rate to meet our computational needs. Conventional supercomputers have become too costly to develop or own, given their delivered performance. Microprocessor performance will double every two years for at least the next 10 years. Micro-based, ultraperformance multicomputers are the only viable means to achieve the TFLOPS goal.
Large-Scale Systems and Their Limitations
Dick Clayton
Richard J. Clayton is responsible for the strategy and management of Thinking Machines Corporation's product development, manufacturing, and customer support operations. Since joining Thinking Machines in late 1983—shortly after its founding—he has built both the product and organization to the point where the company's 75 installed Connection Machines represent about 10 per cent of the U.S. supercomputer base.
Before joining Thinking Machines, Mr. Clayton was a Vice President at Digital Equipment Corporation. In his 18 years at Digital, he held numerous positions. As Vice President for Computer System Development, he was responsible for development of products representing 40 per cent of the business. As a Product Line Manager, he was directly responsible for the strategy, marketing, development, and profit and loss for 20 per cent of the company's revenue. As Vice President for Advanced Manufacturing Technology, he was responsible for upgrading the company's manufacturing capabilities.
Mr. Clayton received his bachelor's and master's degrees in electrical engineering from MIT in 1962 and 1964, respectively. During this period he also did independent research on neuroelectric signals in live animals, using the latest computer technology then available.
I'm going to talk about hardware—the applicability of these large-scale systems and their limitations. I have some comments about programming, including some thoughts on the economics, and a few conclusions.
Let me start with the premise that a TFLOPS machines is on the way, i.e., a machine capable of handling 1012 floating-point operations per second. It will certainly be built in the 1990s. I might argue sooner rather than later, but that's not the purpose of this discussion.
I want to focus on this idea of data-intensive, or large-scale, computing, where large scale equates to lots of data. This is where the idea of heterogeneous computing fits. This idea has given us a clearly defined context where the large-scale vector machines, on which we've written large amounts of software, are very, very important to computing for as far as I can see into the future. And that's, for me, where the heterogeneous part fits.
As we get up into many millions or billions of data objects, as we go from two to three to four to five dimensions, the amount of computing—the sheer quantity to be done—is enormous. And how we keep that all together is the question.
So for me, the idea of data parallelism has to do with very large amounts of data, and that's where a lot of the action really is in massive parallelism. The generalized space is another one of these all-possible things you might some day want to do with computers.
With apologies to Ken Olson (an ex-boss of mine, who never allowed semi-log or log-log charts) but in deference to Gordon Bell (who is here with us at this conference), I'm going to consider a log-log chart incorporating the number of processors, the speed expressed in millions of instructions per second, and the general space in which to play.
The speed of light gets you somewhere out at around a nanosecond or so. I don't care, move it out faster if you want. Your choice. But somewhere out there, there are problems, one of which is called communication limits. And I know from experience in design work, software accomplishments, and customer accomplishments, it's a long way up there. I would argue that we can build scalable ![]() architectures
architectures ![]() well up into a million elements and I think, beyond. But how far beyond and with what economics are complications we're going to mess with for quite a while. It's one of those science-versus-engineering problems. It's far enough away that it doesn't matter for the near future, like 10 years hence.
well up into a million elements and I think, beyond. But how far beyond and with what economics are complications we're going to mess with for quite a while. It's one of those science-versus-engineering problems. It's far enough away that it doesn't matter for the near future, like 10 years hence.
Giving some other names to this space, let me use the concepts of serial processing, shared memory, message passing, and data parallel. Those are styles of programming, or styles of computer construction. And they're arbitrarily chosen.
Let me use that same context, and let me talk about this whole idea of computer design and the various styles of computing. If you're starting out fresh, standing back and looking at things objectively, you say, "Gee, the issue probably is interconnectivity and software, so go for it—figure this stuff out, and then pour the technology in it over time." That's an interesting way to go at the question. Slightly biased view, of course.
The problem with this path, as you confront these boundaries (I sort of view them as hedgerows that you have to take your tanks over, like in Europe during World War II), is that you basically have to do everything over again as you change the number of processors while you're finding different algorithms.
But I want to change this whole software discussion from a debate about tools (i.e., a debate about whether it's easy or hard to program) to a more fundamental one—a debate about algorithms. Now we say, "Gee, let's jump right in. If we're lucky, we can skip a few of these hedgerows, and everybody's going to be absolutely sure we're totally crazy, everybody!" I didn't attend the supercomputing conference held here seven years ago, so for me this is the first visit. I hadn't joined the company quite yet. But for the first few years, this looked like total insanity because it made no sense whatsoever.
The important part of this is our users. They're the ones who are helping us really figure this out.
Of course, Gordon wants it to be hard to program (with Mobil winning the Gordon Bell prize, and then a student at Michigan winning the second prize. We didn't even know what the student was up to; he was using the network machine that the Defense Advanced Research Projects Agency had, in fact, helped us sponsor). So I'm sure it's hard to program. It's really tough. But one way or another, people are doing it. You know, there are videotapes in the computer museum in Boston. There's Edward R. Murrow, there's Seymour Cray. And Seymour gives a really beautiful speech about—I think it was the CRAY-1 or something. He was being interviewed, and somebody asks, "Well, Seymour, isn't software compatibility really important?" And Seymour has kind of a twinkle in his eye, and he says, "Yeah, but if I give them a computer that's three or four times faster, it doesn't matter."
Although I may not subscribe to that exact model, I'll admit that if you give the user a machine that's a lot faster, and if there's a promise of cost-performance for these really humongous piles of data, then there's kind of an interesting problem here. And that, to me, is what this idea of massive parallelism is about.
So I think what's interesting is that the really data-intensive part coexists very well with the heterogeneous model and with vector computers that have been around for quite a while.
Let me say one more thing about this software idea. The software problem is one we've seen before. The problem is, we've got this large amount of investment in applications—in real programs—and they're important, and we're going to use them forever. And they don't work on these kinds of machines.
The reasons they don't work are actually fairly simple. The correct algorithms for these large machines are algorithms that essentially have a fair bit of data locality and a machine model that essentially is shared memory, but humongous.
The whole idea in designing machines like Thinking Machines Corporation's Connection Machine or like these massively parallel machines is that you start with an interconnect model. And the interconnect model really supports a programming model. Let me ask, why not make it a shared-memory programming model—start right from the beginning with a shared-memory model and let the interconnect support the software models so that you can develop algorithms to make it happen? You've got to do something else, though, with this interconnect model. You've also got to move data back and forth real fast.
But there's no free lunch. When you build machines with thousands or tens of thousands of processors, it's probably true that getting to a piece of data in another processor ain't nearly so fast as getting to the data locally. And we heard, 10 different ways, the statement that memory bandwidth is where it's at. I completely agree.
So you've got a pile of memory and then you've got processors. But you've got to have a model, an interconnect model, that lets you get at all of that data simply and at relatively low cost. That's what drives us. In fact, I think that's how you design these machines; you start with this interconnect and software model and then memories; in some sense, processors are commodities that you put under this interconnect/software model.
The one thing that's different about these machines is this new idea of locality. Not all memory references are created equal. That was the implicit assumption of software compatibility: all memory references are created equal. Gee, they're not any longer. Some are faster than others if they're local.
Do we have any history of a similar example? Once upon a time, about 15 or 18 years ago, some people in Minnesota led us from serial computing to vector computing. It wasn't, you know, a megabyte of local data
that was fast; it was a few hundred words. But there is a model, and it does make the transition.
There are no free lunches. Some real matrix-multiply performance on a 64K Connection Machine is now—this is double-precision stuff—is now up to five GFLOPS. The first serial algorithms we did were 10 MFLOPS, and we've gone through several explorations of the algorithm space to figure out how to get there. More importantly, our users have led us through it by the nose. I was reminded, during another presentation, that we are not fully acknowledging all the people that have beat us over the head out here.
Where do we see Fortran going? Algorithms coded in Fortran 77, twisted around, go fairly well. Start to parallelize them, and then go to Fortran 8X, where you can express the parallelism directly. We see that's where it's headed in the 1990s. We really feel good about the Fortran compilers we've now got and where they're going—very much in line with where we're taking the machines.
New algorithms are required. Standard languages will do fine; the problem is education and the problem is learning. Our users are really helping us get shaped up in the software. We've now got a timesharing system out that's beginning to help speed the program development for multiple users.
There is work being done at Los Alamos National Laboratory on a variable grid-structured problem for global weather modeling. And in fact, this dynamically changes during the calculation. We all know , of course, that you can't have irregular grid structures on SIMD or massively parallel machines. And we've, of course, learned that we were wrong.
Hardware conclusions: building TFLOPS machines will be possible fairly early in the 1990s. It's a little expensive. A big socioeconomic problem, but it's going to happen.
Massively parallel computers work well for data-intensive applications. You've got to have a lot of data to make this really worth doing. But where that's the case, it really does make sense. And there's still plenty of room for the software that is already written and for the problems that don't have this massively parallel, data-intensive kind of characteristic.
Now for some ideas about where all this might be going in the mid-1990s. Everybody wins here, everybody's a winner. Have it any way you want. You can pick the year that satisfies you.
By number of programs, this massively parallel stuff is going to be pretty small. By number of cycles, it's going to be pretty big, pretty fast. Gordon's got a bet that it isn't going to happen very soon, but he's already lost.
And finally, by number of dollars it's just so cost effective a way to go that it may be that way longer than we think is smart. But then, you never know.
To conclude, we're having a ball. We think it's a great way to build computers to work with really very large amounts of data. The users—whether at Los Alamos, at Mobil, anyplace—they're all beating the heck out of us. They're teaching us really fast. The machines, the algorithms, and the hardware are getting so much better. And it's a ball. We're really enjoying it.
A Scalable, Shared-Memory, Parallel Computer
Burton Smith
Burton J. Smith is Chief Scientist of Tera Computer Company in Seattle, Washington. He has a bachelor's degree in electrical engineering from the University of New Mexico, Albuquerque, and a doctorate from MIT. He was formerly chief architect of the HEP computer system, manufactured by Denelcor, in Denver, Colorado. His abiding interest since the mid-1970s has been the design and implementation of general-purpose parallel computer systems.
I would like to investigate with you what it means for a parallel computer to be scalable. Because I do not know what a scalable implementation is, I would like to talk about scalable ![]() architecture
architecture ![]() .
.
An ![]() architecture
architecture ![]() is s (p )-scalable with respect to the number of processors, p , if
is s (p )-scalable with respect to the number of processors, p , if
• the programming model does not change with p and is independent of p ,
• the parallelism needed to get Sp = q (p ), that is, linear speedup, is O(p · s (p )), and
• the implementation cost is O(p · s (p ) · log(p )).
The meaning of the term "parallelism" depends on the programming model. In the case of a shared-memory multiprocessor, the natural parallelism measure is how many program counters you have. The log term in the last expression is there because we are going from a conventional complexity model into a bit-complexity model, and hence, we need a factor of log to account for the fact that the addresses are getting wider, for example.
Most ![]() architectures
architectures ![]() scale with respect to some programming model or other. Unfortunately, there are some
scale with respect to some programming model or other. Unfortunately, there are some ![]() architectures
architectures ![]() that do not scale with respect to any model at all, although most scale with respect to something that might be called the "nearest-neighbor message-passing" model. Many an
that do not scale with respect to any model at all, although most scale with respect to something that might be called the "nearest-neighbor message-passing" model. Many an ![]() architecture
architecture ![]() is routinely used with a programming model that is stronger than its scaling model. There are no "scaling police" that come around and say, "You can't write that kind of program for that kind of machine because it's only a 'nearest-neighbor' machine."
is routinely used with a programming model that is stronger than its scaling model. There are no "scaling police" that come around and say, "You can't write that kind of program for that kind of machine because it's only a 'nearest-neighbor' machine."
I would now like to discuss the shared-memory programming model. In this model, data placement in memory does not affect performance, assuming that there is enough parallel slackness. The parallel slackness that Leslie Valiant (1990) refers to is used to tolerate synchronization latency, or in Valiant's case, barrier synchronization latency, as well as memory latency.
In the shared-memory programming model, the memory should be distributed with addresses hashed over what I believe should be a hierarchy or selection of neighborhoods rather than merely two different neighborhoods, as is common practice today. Also, synchronization using short messages is desirable. Message-passing is a good idea because it is the best low-level synchronization and data-communication machinery we have.
Many of us today think a k-ary n-cube network with an adaptive routing algorithm is probably best because adaptive routing avoids certain difficulties that arise with pessimistic permutations and other phenomena.
Tera Computer is developing a high-performance, scalable, shared-memory computer system. Remember, a shared-memory machine has the amusing property that the performance is independent of where the data is placed in memory. That means, for example, there are no data caches.
The Tera system ![]() architecture
architecture ![]() has a scaling factor of p1/2 . We build a pretty big network to get shared memory to work and to make performance insensitive to data location. The factor p1/2 is optimal for scalable, shared-memory systems that use wires or fibers for network interconnections. Using VLSI-complexity arguments (i.e., the implications of very-large-scale integration) in three dimensions instead of two for messages that occupy volume, one can show that scalable, shared-memory machines cannot be built for a lesser exponent of p .
has a scaling factor of p1/2 . We build a pretty big network to get shared memory to work and to make performance insensitive to data location. The factor p1/2 is optimal for scalable, shared-memory systems that use wires or fibers for network interconnections. Using VLSI-complexity arguments (i.e., the implications of very-large-scale integration) in three dimensions instead of two for messages that occupy volume, one can show that scalable, shared-memory machines cannot be built for a lesser exponent of p .
The network has a bisection bandwidth of around 1.6 terabytes per second. Each processor has a sustained network bandwidth of around 3.2
gigabytes per second. The bandwidth of the switch nodes that compose the network is about five times that amount, or 16 gigabytes per second.
However, if free-space optics were employed, one could conceivably use four of the six dimensions available and thereby pack more messages into the computer, thereby decreasing s (p ) to p1/3 .
As far as I know, no other company is developing a scalable, shared-memory system. However, there is a lot of research in scalable, shared-memory systems at Stanford University and MIT, for example. Most ![]() architectures
architectures ![]() that purport to be scalable are less so than Tera's machine, and with respect to a weaker model than shared memory.
that purport to be scalable are less so than Tera's machine, and with respect to a weaker model than shared memory.
Shared memory is better than nonshared memory. One can dynamically schedule and automatically balance processor workloads. One can address irregularly without any difficulties, either in software or hardware. Shared memory is friendlier for explicit parallel programs, although certainly explicit parallelism is perhaps the only salvation of some machine models. Most important, shared memory is needed for machine-independent parallel languages, that is, portable parallel languages and their optimizing compilers. What is surprising about all this is that performance and price/performance need not suffer.
I would like to point out some of the Tera hardware characteristics. The processors are fast, both in millions of instructions per seconds (MIPS) and millions of floating-point operations per second (MFLOPS). There are
• 1.2 scalar GFLOPS per processor (64 bits),
• 1200 equivalent MIPS per processor,
• 16 or 32 megawatts (128 or 256 megabytes) of data memory per processor,
• one gigabyte of I/O memory per processor,
• two 200-megabytes-per-second high-performance parallel interface channels per processor, and
• disk arrays (RAID) for local storage.
The gigabyte of I/O memory per processor is the layer in the storage hierarchy lying between processors and the disk arrays.
These processor characteristics add up to 300 gigaflops and 300,000 MIPS for a 256-processor system, which is interconnected by a 16-ary 3-cube of network routing nodes with one-third of the links missing. Details on the hardware are available in Alverson et al. (1990).
You may be asking why we need to use fast, expensive logic and processors yielding 1.2 GFLOPS. The Tera system clock period will be three nanoseconds or less. Why doesn't Tera use a slower clock and more processors? Although emitter-coupled logic (ECL) and gallium arsenide
gates both cost about three times more than complementary metal oxide semiconductor (CMOS) gates do, ECL and gallium arsenide gates are six times as fast as CMOS. BiCMOS, by the way, with bipolar output drivers on some cells, could reduce that number a bit. If most of the logic is pipelined and kept usefully busy, ECL and gallium arsenide are, therefore, twice as cost effective as CMOS.
Our interconnection network achieves a performance of 2X because the network gate count grows faster than p . As wires become more expensive, we must use them better. I think we will see more fast networks because of this. We will also find not-too-fast processors of all sorts being multiplexed to very fast network nodes, maybe even built from Josephson logic.
How massively parallel is a 256-processor Tera machine? Each Tera processor will need to have 64 or so memory references "in the air" to keep it busy. This is comparable to the needs of a fast vector processor. Main memory chip latency is about 20 nanoseconds these days and is not going to improve too quickly.
If one is seeking 100 gigawords per second of memory bandwidth, a latency of 20 nanoseconds per word implies 2000-fold parallelism simply to overcome memory chip latency. Every latency or bandwidth limitation in an ![]() architecture
architecture ![]() will consume still more parallelism in time or space, respectively. One could rightly conclude that all fast computers are massively parallel computers.
will consume still more parallelism in time or space, respectively. One could rightly conclude that all fast computers are massively parallel computers.
Tera's system software characteristics include the following:
• automatic whole-program analysis and parallelization,
• Fortran and C (C++), with parallel extensions,
• parallel extensions that are compatible with automatic analysis and parallelization,
• symbolic debugging of optimized programs,
• workstation-grade UNIX, including network file system, transmission control protocol/Internet protocol, and sockets, and
• parallel I/O to a log-structured file system.
It is the ![]() architecture
architecture ![]() that will make this software feasible.
that will make this software feasible.
In the remainder of the decade, supercomputers will continue to creep up in price. A dynamic random-access memory chip is $40 million per terabyte today, and it will halve in cost every three years. Tera will build and deliver a TFLOPS system sometime in 1996, when it becomes affordable. Also by 1996, 64-bit multi-stream microprocessors will appear.
My last predictions are that single-application, "shrink-wrapped" supercomputers will be popular for circuit simulation, structural analysis, and molecular modeling in chemistry and biology. These systems will be highly programmable, but not by the customers.
References
L. Valiant, "A Bridging Model for Parallel Computation," Communications of the ACM33 (8), 103 (1990).
R. Alverson et al., "The Tera Computer System," in Conference Proceedings. 1990 International Conference on Supercomputing , ACM, New York, pp. 1-6 (1990).
Looking at All of the Options
Jerry Brost
Gerald M. Brost, Vice President of Engineering for Cray Research, Inc. (CRI), has been with the company since 1973 and has made significant contributions to the development and evolution of CRI supercomputers, from the CRAY-1 through the Y-MP C90. His responsibilities have included overall leadership for projects involving the CRAY X-MP, the CRAY-2, the CRAY Y-MP, CRAY Y-MP follow-on systems, and Cray's integrated-circuit facilities and peripheral products. Today, his responsibilities include overall leadership for the CRAY Y-MP EL, the CRAY Y-MP C90, the MPP Project, and future product development.
Before joining Cray, Mr. Brost worked for Fairchild Industries on a military system project in North Dakota. He graduated from North Dakota State University (NDSU) with a bachelor of science degree in electrical and electronics engineering and has done graduate work in the same field at NDSU.
To remain as the leaders in supercomputing, one of the things that we at Cray Research, Inc., need to do is continue looking at what technology is available. That technology is not just circuits but also ![]() architecture
architecture ![]() . We need to keep looking at all the technological pieces that have to be examined in order to put together a system.
. We need to keep looking at all the technological pieces that have to be examined in order to put together a system.
Cray Research looked at technologies like gallium arsenide about eight years ago and chose gallium arsenide because of its great potential.
Today it still has a lot of potential, and I think someday it is going to become the technology of the supercomputer.
We also looked at optical computing and fiber optics, which is an area in which we will see continued growth. However, we are not committed to optical-circuit technology to build the next generation of Cray supercomputers.
Several years ago, we looked at software technology and chose UNIX because we saw that was a technology that could make our systems more powerful and more usable by our customers.
Superconductors look like a technology that has a lot of potential. However, we are unable to build anything with superconductors today.
It may come as a surprise to some that massively parallel ![]() architectures
architectures ![]() have been out for at least 20 years. Some people might say that these
have been out for at least 20 years. Some people might say that these ![]() architectures
architectures ![]() have been out longer than that, but they have been out at least 20 years.
have been out longer than that, but they have been out at least 20 years.
Even in light of the available technologies, are we at a point where, to satisfy the customers, we should incorporate the technologies into our systems? Up to now, I think the answer has been no.
We have gone out and talked to our customers and surveyed the customers on a number of things. First of all, when we talked about ![]() architectures
architectures ![]() , we were proposing what all of you know as the C90 Program. What should that
, we were proposing what all of you know as the C90 Program. What should that ![]() architecture
architecture ![]() look like? We have our own proposal, and we gave that to some of the customers.
look like? We have our own proposal, and we gave that to some of the customers.
We talked about our view of massive parallelism. We asked the customers where they saw massive parallelism fitting into their systems. It is something that really works? Although you hear all the hype about it, is it running at a million floating-point operations per second—a megaflop? Or is it just a flop? One of the things that we learned in our survey on massive parallelism is that there are a number of codes that do run at two- to five-billion floating-point operations per second (two to five GFLOPS).
If I listen to my colleagues today, I hear that there are large numbers of codes all running at GFLOPS ranges on massively parallel machines. Indeed, there has been significant progress made with massively parallel machines. There has been enough progress to convince us that massively parallel is an element that needs to be part of our systems in the future. Today at Cray we do have a massively parallel program, and it will be growing from now on.
Massively parallel systems do have some limitations. First of all, they are difficult ![]() architectures
architectures ![]() to program. For many of the codes that are running at the GFLOPS or five-GFLOPS performance level, it probably
to program. For many of the codes that are running at the GFLOPS or five-GFLOPS performance level, it probably
took someone a year's time to get the application developed. But that is because the tools are all young, the ![]() architecture
architecture ![]() is young, and there are a lot of unknowns.
is young, and there are a lot of unknowns.
Today there are probably at least 20 different efforts under way to develop massively parallel systems. If we look at progress in massive parallelism, it is much like vector processing was. If we go back in time, basically all machines were scalar processing machines.
We added vector processing to the CRAY-1 back in 1976. At first it was difficult to program because there were not any compilers to help and because people didn't know how to write special algorithms. It took some time before people started seeing the advantage of using vector processing. Next, we went on to parallel processors. Again, it took some time to get the software and to get the applications user to take advantage of the processors.
I see massively parallel as going along the same lines. If I look at the supercomputer system of the future, it is going to have elements of all of those. Scalar processing is not going to go away. Massively parallel is at an infant stage now, where applications are starting to be moved into and people are starting to learn how to make use of them.
Vector processing is not going to go away either. If I look at the number of applications that are being moved to vector processors, I find a great many.
Our goal at Cray is to integrate the massively parallel, the vector processor, and the scalar processor into one total system and make it a tightly coupled system so that we can give our customers the best overall solution. From our view, we think that for the massively parallel element, we will probably have to have at least 10 times the performance over what we can deliver in our general-purpose solution. When you can take an application and move it to the massively parallel, there can be a big payback that can justify the cost of the massively parallel element.
Work that has been done by the Defense Advanced Research Projects Agency and others has pushed the technology along to the point where now it is usable. More work is going to have to be done in optical circuits. Still more work has to be done in gallium arsenide until that is truly usable.
These are all technologies that will be used in our system at Cray. It is just a matter of time before we incorporate them into the system and make the total system operative.
To conclude, Cray does believe that massively parallel systems can work. Much work remains to be done that will be a part of a Cray Research supercomputer solution in the future. We see that as a way to
move up to TFLOPS performance. I think when we can deliver TFLOPS performance, the timing will have been determined by somebody's ability to afford it. We could probably do it in 1995, although I don't know if users will have enough money to buy a TFLOPS computer system by 1995.
Massively parallel developments will be driven by technology—software and the ![]() architecture
architecture ![]() . A lot of elements are needed to make the progress, but we are committed to putting a massively parallel element on our system and to being able to deliver TFLOPS performance to our customers by the end of the decade.
. A lot of elements are needed to make the progress, but we are committed to putting a massively parallel element on our system and to being able to deliver TFLOPS performance to our customers by the end of the decade.