9—
INDUSTRIAL SUPERCOMPUTING
Panelists in this session discussed the use of supercomputers in several industrial settings. The session focused on cultural issues and problems, support issues, experiences, efficiency versus ease of use, technology transfer, impediments to broader use, encouragement of industrial use, and industrial grand challenges.
Session Chair
Kenneth W. Neves,
Boeing Computer Services
Overview of Industrial Supercomputing
Kenneth W. Neves
Kenneth W. Neves is a Technical Fellow of the Boeing Company (in the discipline of scientific computing) and Manager of Research and Development Programs for the Technology Division of Boeing Computer Services. He holds a bachelor's degree from San Jose State University, San Jose, California, and master's and doctorate degrees in mathematics from Arizona State University, Tempe, Arizona. He developed and now manages the High-Speed Computing Program dedicated to exploration of scientific computing issues in distributed/parallel computing, visualization, and multidisciplinary analysis and design.
Abstract
This paper summarizes both the author's views as panelist and chair and the views of other panelists expressed during presentations and discussions in connection with the Industrial Supercomputing Session convened at the second Frontiers of Supercomputing conference. The other panel members were Patric Savage, Senior Research Fellow, Computer Science Department, Shell Development Company; Howard E. Simmons, Vice President and Senior Advisor, du Pont Company; Myron Ginsberg, Consultant Systems Engineer, EDS Advanced Computing Center, General Motors Corporation; and Robert Hermann, Vice President for Science and Technology, United Technologies Corporation. Included in these remarks is an overview of the basic issues related to high-performance computing needs of private-sector industrial users. Discussions
that ensued following the presentations of individual panel members focused on supercomputing questions from an industrial perspective in areas that include cultural issues and problems, support issues, efficiency versus ease of use, technology transfer, impediments to broader use, encouraging industrial use, and industrial grand challenges.
Introduction
The supercomputer industry is a fragile industry. In 1983, when this conference first met, we were concerned with the challenge of international competition in this market sector. In recent times, the challenge to the economic health and well-being of this industry in the U.S. has not come from foreign competition but from technology improvements at the low end and confusion in the primary market, industry. The economic viability of the supercomputing industry will depend on the acceptance by private industrial users. Traditional industrial users of supercomputing have come to understand that using computing tools at the high end of the performance spectrum provides a competitive edge in product design quality. Yet, the question is no longer one of computational power alone. The resource of "supercomputing at the highest end" is a very visible expense on most corporate ledgers.
In 1983 a case could be made that in sheer price/performance, supercomputers were leaders and if used properly, could reduce corporate computing costs. Today, this argument is no longer true. Supercomputers are at the leading edge of price/performance, but there are alternatives equally competitive in the workstation arena and in the midrange of price and performance. The issue then, is not simply accounting but one of capability. With advanced computing capability, both in memory size and computational power, the opportunity exists to improve product designs (e.g., fuel-efficient airplanes), optimize performance (e.g., enhanced oil recovery), and shorten time from conceptual design to manufacture (e.g., find a likely minimal-energy state for a new compound or medicine). Even in industries where these principles are understood, there still are impediments to the acquisition and use of high-performance computing tools. In what follows we attempt to identify these issues and look at aspects of technology transfer and collaboration among governmental, academic, and industrial sectors that could improve the economic health of the industry and the competitiveness of companies that depend on technology in their product design and manufacturing processes.
Why Use Supercomputing at All?
Before we can analyze the inhibitors to the use of supercomputing, we must have a common understanding of the need for supercomputing. First, the term supercomputer has become overused to the point of being meaningless, as was indicated in remarks by several at this conference. By a supercomputer we mean the fastest, most capable machine available by the only measure that is meaningful—sustained performance on an industrial application of competitive importance to the industry in question. The issue is not which machine is best, at this point, but that some machines or group of machines are more capable than most others, and this class we shall refer to as "supercomputers." Today this class is viewed as large vector computers with a modest amount of parallelism, but the future promises to be more complicated, since one general type of ![]() architecture
architecture ![]() probably won't dominate the market.
probably won't dominate the market.
In the aerospace industry, there are traditional workhorse applications, such as aerodynamics, structural analysis, electromagnetics, circuit design, and a few others. Most of these programs analyze a design. One creates a geometric description of a wing, for example, and then analyzes the flow over the wing. We know that today supercomputers cannot handle this problem in its full complexity of geometry and physics. We use simplifications in the model and solve approximations as best we can. Thus, the traditional drivers for more computational power still exist. Smaller problems can be run on workstations, but "new insights" can only be achieved with increased computing power.
A new generation of computational challenges face us as well (Neves and Kowalik 1989). We need not simply analysis programs but also design programs. Let's consider three examples of challenging computing processes. First, consider a program in which one could input a desired shock wave and an initial geometric configuration of a wing and have the optimal wing geometry calculated to most closely simulate the desired shock (or pressure profile). With this capability we could greatly reduce the wing design cycle time and improve product quality. In fact, we could reduce serious flutter problems early in the design and reduce risk of failure and fatigue in the finished product. This type of computation would have today's supercomputing applications as "inner loops" of a design system requiring much more computing power than available today. A second example comes from manufacturing. It is not unusual for a finalized design to be forwarded to manufacturing just to find out that the design cannot be manufactured "as designed" for some
unanticipated reason. Manufacturability, reliability, and maintainability constraints need to be "designed into" the product, not discovered downstream. This design/build concept opens a whole new aspect of computation that we can't touch with today's computing equipment or approaches. Finally, consider the combination of many disciplines that today are separate elements in design. Aerodynamics, structural analyses, thermal effects, and control systems all could and should be combined in design evaluation and not considered separately. To solve these problems, computing power of greater capability is required; in fact, the more computing power, the "better" the product! It is not a question of being able to use a workstation to solve these problems. The question is, can a corporation afford to allow products to be designed on workstations (with yesterday's techniques) while competitors are solving for optimal designs with supercomputers?
Given the rich demand for computational power to advance science and engineering research, design, and analysis as described above, it would seem that there would be no end to the rate at which supercomputers could be sold. Indeed, technically there is no end to the appetite for more power, but in reality each new quantum jump in computational power at a given location (user community) will satisfy needs for some amount of time before a new machine can be justified. The strength in the supercomputer market in the 1980s came from two sources: existing customers and "new" industries. Petrochemical industries, closely followed by the aerospace industry, were the early recruits. These industries seem to establish a direct connection between profit and/or productivity and computing power. Most companies in these industries not only bought machines but upgraded to next-generation machines within about five years. This alone established an upswing in the supercomputing market when matched by the already strong government laboratory market from whence supercomputers sprang. Industry by industry, market penetration was made by companies like Cray Research, Inc. In 1983 the Japanese entered the market, and several of their companies did well outside the U.S. New market industries worldwide included weather prediction, automobiles, chemicals, pharmaceuticals, academic research institutions (state- and NSF-supported), and biological and environmental sciences. The rapid addition of "new" markets by industries created a phenomenal growth rate.
In 1989 the pace of sales slackened at the high end. The reasons are complex and varied, partly because of the options for users with "less than supercomputer problems" to find cost-effective alternatives; but the biggest impact, in my opinion, is the inability to create new industry
markets. Most of the main technically oriented industries are already involved in supercomputing, and the pace of sales has slowed to that of upgrades to support the traditional analysis computations alluded to above. This is critical to the success of these companies but has definitely slowed the rate of sales enjoyed in the 1980s. This might seem like a bleak picture if it weren't for one thing: as important as these traditional applications are, they are but the tip of the iceberg of scientific computing opportunities in industry . In fact, at Boeing well over a billion dollars are invested in computing hardware. Supercomputers have made a very small "dent" in this computing budget. One might say that even though supercomputers exist at almost 100 per cent penetration by company in aerospace, within companies, this penetration is less than five per cent.
Certainly supercomputers are not fit for all computing applications in large manufacturing companies. However, the acceptance of any computing tool, or research tool such as a wind tunnel, is a function of its contribution to the "bottom line." The bottom line is profit margin and market share. To gain market share you must have the "best product at the least cost." Supercomputing is often associated with design and hence, product quality. The new applications of concurrent engineering (multidisciplinary analysis) and optimal design (described above) will achieve cost reduction by ensuring that manufacturability, reliability, and maintainability are included in the design. This story needs to be technically developed and understood by both scientists and management. The real untapped market, however, lies in bringing high-end computation to bear on manufacturing problems ignored so far by both technologists and management in private industry.
For example, recently at Boeing we established a Computational Modeling Initiative to discover new ways in which the bottom line can be helped by computing technology. In a recent pilot study, we examined the rivet-forming process. Riveting is a critical part of airplane manufacturing. A good rivet is needed if fatigue and corrosion are to be minimized. Little is known about this process other than experimental data. By simulating the riveting process and animating it for slow-motion replay, we have utilized computing to simulate and display what cannot be seen experimentally. Improved rivet design to reduce strain during the riveting has resulted in immediate payoff during manufacturing and greatly reduced maintenance cost over the life of the plane. Note that this contributes very directly to the bottom line and is an easily understood contribution. We feel that these types of applications (which in this case required a supercomputer to handle the complex structural analysis simulation) could fill many supercomputers productively once the
applications are found and implemented. This latent market for computation within the manufacturing sectors of existing supercomputer industries is potentially bigger than supercomputing use today. The list of opportunities is enormous: robotics simulation and design, factory scheduling, statistical tolerance analysis, electronic mockup (of parts, assemblies, products, and tooling), discrete simulation of assembly, spares inventory (just-in-time analysis of large, complex manufacturing systems), and a host of others.
We have identified three critical drivers for a successful supercomputing market that all are critical for U.S. industrial competitiveness: 1) traditional and more refined analysis; 2) design optimization, multidisplinary analysis, and concurrent engineering (design/build); and 3) new applications of computation to manufacturing process productivity.
The opportunities in item 3 above are so varied, even at a large company like Boeing, it is hard to be explicit. In fact, the situation requires those involved in the processes to define such opportunities. In many cases, the use of computation is traditionally foreign to the manufacturing process, which is often a "build and test" methodology, and this makes the discovery of computational opportunities difficult. What is clear, however, is that supercomputing opportunities exist (i.e., a significant contribution can be made to increased profit, market share, or quality of products through supercomputing). It is worthwhile to point out broadly where supercomputing has missed its opportunities in most industries, but certainly in the aerospace sector:
• manufacturing—e.g., rivet-forming simulation, composite material properties;
• CAD/CAM—e.g., electronic mockup, virtual reality, interference modeling, animated inspection of assembled parts;
• common product data storage—e.g., geometric-model to grid-model translation; and
• grand-challenge problems—e.g., concurrent engineering, data transfer: IGES, PDES, CALS.
In each area above, supercomputing has a role. That role is often not central to the area but critical in improving the process. For example, supercomputers today are not very good database machines, yet much of the engineering data stored in, say, the definition of an airplane is required for downstream analysis in which supercomputing can play a role. Because supercomputers are not easily interfaced to corporate data farms, much of that analysis is often done on slower equipment, to the detriment of cost and productivity.
With this as a basis, how can there be any softness in the supercomputer market? Clearly, supercomputers are fundamental to competitiveness, or are they?
Impediments to Industrial Use of Supercomputers
Supercomputers have been used to great competitive advantage throughout many industries (Erisman and Neves 1987). The road to changing a company from one that merely uses computers on routine tasks to one that employs the latest, most powerful machines as research and industrial tools to improve profit is a difficult one indeed. The barriers include technical, financial, and cultural issues that are often complex; and even more consternating, once addressed, they can often reappear over time. The solution to these issues requires both management and technologists in a cooperative effort. We begin with what are probably the most difficult issues—cultural and financial barriers.
The cultural barriers that prevent supercomputing from taking its rightful place in the computing venue abound. Topping the list is management understanding of supercomputing's impact on the bottom line. Management education in this area is sorely needed, as most managers who have wrestled with these issues attest. Dr. Hermann, one of the panelists in this session, suggested that a successful "sell" to management must include a financial-benefits story that very few people can develop. To tell this story one must be a technologist who understands the specific technical contributions computing can have on both a company's product/processes and its corporate competitive and profit goals. Of the few technologists who have this type of overview, how many would take on what could be a two-year "sell" to management? History can attest that almost every successful supercomputer placement in industry, government, or academia has rested on the shoulders of a handful of zealots or champions with that rare vision. This is often true of expensive research-tool investments, but for computing it is more difficult because of the relative infancy of the industry. Most upper-level managers have not personally experienced the effective use of research computing. When they came up through the "ranks," computing, if it existed at all, was little more than a glorified engineering calculator (slide rule). Managers in the aerospace industry fully understand the purpose of a $100 million investment in a wind tunnel, but until only in the last few years did any of them have to grapple with a $20 million investment in a "numerical" wind tunnel. Continuing with this last aerospace example, how did the culture change? An indispensable ally in the aerospace
industry's education process has been the path-finding role of NASA, in both technology and collaboration with industry. We will explore government-industry collaboration further in the next section.
Cultural issues are not all management in nature. As an example, consider the increasing need for collaborative (design-build) work and multidisciplinary analysis. In these areas, supercomputing can be the most important tool in creating an environment that allows tremendous impact on the bottom line, as described above. However, quite often the disciplines that need to cooperate are represented by different (often large) organizations. Nontechnical impediments associated with change of any kind arise, such as domain protection, fear of loss of control, and career insecurities owing to unfamiliarity with computing technology. Often these concerns are never stated but exist at a subliminal level. In addition, organizations handle computing differently, often on disparate systems with incompatible geometric description models, and the technical barriers from years of cultural separation are very real indeed.
Financial barriers can be the most frustrating of all. Supercomputers, almost as part of their definition, are expensive. They cost from $10 to $30 million and thus are usually purchased at the corporate level. The expense of this kind of acquisition is often distributed by some financial mechanism that assigns that cost to those who use it. Therein lies the problem. To most users, their desk, pencils, paper, phone, desk-top computer, etc., are simply there. For example, there is no apparent charge to them, their project, or their management when they pick up the phone. Department-level minicomputers, while a visible expense, are controlled at a local level, and the expenses are well understood and accepted before purchase. Shared corporate resources, however, look completely different. They often cost real project dollars. To purchase X dollars of computer time from the company central resource costs a project X dollars of labor. This tradeoff applies pressure to use the least amount of central computing resources possible. This is like asking an astronomer to look through his telescope only when absolutely necessary for the shortest time possible while hoping he discovers a new and distant galaxy.
This same problem has another impact that is more subtle. Supercomputers like the Cray Research machines often involve multiple CPUs. Most charging formulas involve CPU time as a parameter. Consequently, if one uses a supercomputer with the mind set of keeping costs down, one would likely use only one CPU at a time. After all, a good technologist knows that if he uses eight CPUs, Amdahl's law will probably only let him get the "bang" of six or seven and then only if he
is clever. What is the result? A corporation buys an eight-CPU supercomputer to finally tackle corporate grand-challenge problems, and the users immediately bring only the power of one CPU to bear on their problems for financial reasons. Well, one-eighth of a supercomputer is not a supercomputer, and one might opt for a lesser technological solution. In fact, this argument is often heard in industry today by single-CPU users grappling with financial barriers. This is particularly frustrating since the cost-reduction analysis is often well understood, and the loss in product design quality by solving problems on less competitive equipment is often not even identified!
The technological barriers are no less challenging. In fact, one should point out that the financial billing question relative to parallel processing will probably require a technological assist from vendors in their hardware and operating systems. To manage the computing resource properly, accounting "hooks" in a parallel environment need be more sophisticated. Providing the proper incentives to use parallel equipment when the overhead of parallelization is a real factor is not a simple matter. These are issues the vendors can no longer leave to the user but must become a partner in solving.
Supercomputers in industry have not really "engaged" the corporate enterprise computing scene. Computers have had a long history in most companies and are an integral part of daily processes in billing, CAD/CAM, data storage, scheduling, etc. Supercomputers have been brought into companies by a select group and for a specific need, usually in design analysis. These systems, like these organizations, are often placed "over there"—in a corner, an ivory tower, another building, another campus, or any place where they don't get in the way. Consequently, most of the life stream of the corporation, its product data, is out of reach, often electronically and culturally from the high-performance computing complex. The opportunities for supercomputing alluded to in the previous section suggest that supercomputers must be integrated into the corporate computing system. All contact with the central computing network begins at the workstation. From that point a supercomputer must be as available as any other computing resource. To accomplish this, a number of technical barriers must be overcome, such as
• transparent use,
• software-rich environment,
• visualization of results, and
• access to data.
If one delves into these broad and overlapping categories, a number of issues arise. Network topology, distributed computing strategy, and
standards for data storage and transport immediately spring to mind. Anyone who has looked at any of these issues knows the solutions require management and political savvy, as well as technical solutions. At a deeper level of concern are the issues of supercomputer behavior. On the one hand, when a large analysis application is to be run, the supercomputer must bring as much of its resources to bear on the computation as possible (otherwise it is not a supercomputer). On the other hand, if it is to be an equal partner on a network, it must be responsive to the interactive user. These are conflicting goals. Perhaps supercomputers on a network need a network front end, for example, to be both responsive and powerful. Who decides this issue? The solution to this conflict is not solely the responsibility of the vendor. Yet, left unresolved, this issue alone could "kill" supercomputer usage in any industrial environment.
As supercomputer ![]() architectures
architectures ![]() become increasingly more complex, the ability to transfer existing software to them becomes a pacing issue. If existing programs do not run at all or do not run fast on new computers, these machines simply will not be purchased. This problem, of course, is a classic problem of high-end computing. Vectorization and now parallelization are processes that we know we must contend with. The issue of algorithms and the like is well understood. There is a cultural issue for technologists, however. The need to be 100 per cent efficient on a parallel machine lessens as the degree of parallelism grows. For example, if we have two $20 million computers, and one runs a problem at 90 per cent efficiency at a sustained rate of four GFLOPS (billion floating-point operations per second), and the other runs a problem at 20 per cent efficiency at 40 GFLOPS, which would you choose? I would choose the one that got the job done the cheapest! (That can not be determined from the data given! For example, at 40 GFLOPS, the second computer might be using an algorithm that requires 100 times more floating-point operations to reach the same answer. Let us assume that this is not the case and that both computers are actually using the same algorithm.) The second computer might be favored. It probably is a computer that uses many parallel CPUs. How do we charge for the computer time? How do we account for the apparently wasted cycles? I ask these two questions to emphasize that, at all times, the corporate resource must be "accounted" for with well-understood accounting practices that are consistent with corporate and government regulations!
become increasingly more complex, the ability to transfer existing software to them becomes a pacing issue. If existing programs do not run at all or do not run fast on new computers, these machines simply will not be purchased. This problem, of course, is a classic problem of high-end computing. Vectorization and now parallelization are processes that we know we must contend with. The issue of algorithms and the like is well understood. There is a cultural issue for technologists, however. The need to be 100 per cent efficient on a parallel machine lessens as the degree of parallelism grows. For example, if we have two $20 million computers, and one runs a problem at 90 per cent efficiency at a sustained rate of four GFLOPS (billion floating-point operations per second), and the other runs a problem at 20 per cent efficiency at 40 GFLOPS, which would you choose? I would choose the one that got the job done the cheapest! (That can not be determined from the data given! For example, at 40 GFLOPS, the second computer might be using an algorithm that requires 100 times more floating-point operations to reach the same answer. Let us assume that this is not the case and that both computers are actually using the same algorithm.) The second computer might be favored. It probably is a computer that uses many parallel CPUs. How do we charge for the computer time? How do we account for the apparently wasted cycles? I ask these two questions to emphasize that, at all times, the corporate resource must be "accounted" for with well-understood accounting practices that are consistent with corporate and government regulations!
We have paid short shrift to technological issues, owing to time and space. It is hoped that one point has become clear—that the cultural, financial, and technical issues are quite intertwined. Their resolution and
the acceptance of high-end computing tools in industry will require collaboration and technology transfer among all sectors—government, industry, and academia.
Technology Transfer and Collaboration
Pending before Congress are several bills concerning tremendous potential advances in the infrastructure that supports high-performance computing. We at this meeting have a great deal of interest in cooperative efforts to further the cause of high-performance computing—to insure the technological competitiveness of our companies, our research institutions, and, indeed, our nation. To achieve these goals we must learn to work together to share fruitfully technological advances. The definition of infrastructure is perhaps a good starting point for discussing technology transfer challenges. The electronic thesaurus offers the following substitutes for infrastructure:
• chassis, framework, skeleton;
• complex, maze, network, organization, system;
• base, seat; and
• cadre, center, core, nucleus.
The legislation pending has all these characteristics. In terms of a national network that connects high-performance computing systems and large data repositories of research importance, the challenge goes well beyond simply providing connections and hardware. We want a national network that is not a maze but an organized, systematized framework to advance technology. Research support is only part of the goal, for research must be transferred to the bottom line in a sense similar to that discussed in previous sections. No single part of the infrastructure can be singled out, nor left out, for the result to be truly effective. We have spoken often in this forum of cooperative efforts among government, academia, and industry. I would like to be more explicit. If we take the three sectors one level of differentiation further, we have Figure 1.
Just as supercomputers must embrace the enterprise-wide computing establishment within large companies, the national initiatives in high-performance computing must embrace the end-user sector of industry, as well. The payoff is a more productive economy. We need a national network, just like we needed a national highway system, an analogy often used by Senator Albert Gore. Carrying this further, if we had restricted the highway system to any particular sector, we would not have seen the birth of the trucking industry, the hotel and tourism industries, and so on. Much is to be gained by cooperative efforts, and many benefits cannot be predicted in advance. Let us examine two
|
Figure 1.
Technological sectors.
examples of technology transfer that came about through an investment in infrastructure, one by government and another by industry.
First is an example provided by Dr. Riaz Abdulla, from Eli Lilly Research Laboratories, in a private communication. He writes:
For your information, supercomputing, and particularly network supercomputing at Eli Lilly became successful owing to a mutually supportive research and management position on the matter. Both the grass-roots movement here, as well as enlightened management committed to providing the best possible tools to the research staff made the enhancement of our research computer network among the best. . . . We are well on the way to establishing a network of distributed processors directly linked to the supercomputing system via high-speed links modeled after the National Center for Supercomputing Applications [at the University of Illinois, one of the NSF-funded supercomputer centers] and the vision of Professor Larry Smarr. Without the model of the NCSA, its staff of scientists, consultants, engineers and software and visualization experts, Lilly's present success in supercomputing would have been impossible.
Clearly, the government investment in supercomputing for the academic world paid off for Eli Lilly. While this was not an original goal of the NSF initiatives, it clearly has become part of the national infrastructure that NSF has become a part of in supercomputing.
In the second example, technology is transferred from the private sector to the academic and government sectors. Boeing Computer Services
has been involved in supercomputing for almost two decades, from before the term was coined. We purchased Serial No. 2 of Control Data Corporation's CDC 6600, for example—a supercomputer in its day. As such, we owned and operated a national supercomputer time sales service when the NSF Advanced Scientific Computing Program was launched. We responded to a request for proposals to provide initial supercomputer time in Phase I of this program. Under contract with NSF we were able to give immediate access to supercomputing cycles. We formed a team to train over 150 research users in access to our system. This was done on location at 87 universities across the country. We provided three in-depth Supercomputing Institutes, the model of which was emulated by the centers themselves after they were established. In subsequent years we helped form, and are a member of, the Northwest Academic Computing Consortium (NWACC), along with 11 northwest universities. In collaboration we have secured NSF funding to create NWNet, the northwest regional NSF network. Boeing designed and initially operated this network but has since turned the operation over to NWACC and the University of Washington in Seattle. In other business activities, Boeing designed, installed, operates, and trains users of supercomputer centers in academia (the University of Alabama system) and government laboratories (NASA and the Department of Energy). Indeed, technology transfer is often a two-way street. The private sector is taking some very aggressive steps to advanced technology in our research laboratories, as well. (For example, see the paper following in this session, by Pat Savage, Shell Development Company, discussing Shell's leadership to the community in parallel computing tools and storage systems.)
Conclusion
We are delighted to see that much of the legislation before Congress recognizes the importance of technology transfer and collaboration among the Tier I entities of Figure 1. We are confident that all elements of Tier II will be included, but we exhort all concerned that this collaboration be well orchestrated and not left to serendipity. Transferring technology among organizations or Tier I sectors is the most difficult challenge we have, and our approach must be aggressive. The challenges of the supercomputing industry are no less difficult. They too can only be overcome by cooperation. These challenges are both technical and cultural and present an awesome management responsibility.
References
A. Erisman and K. W. Neves, "Advanced Computing for Manufacturing," Scientific American257 (4), 162-169 (1987).
K. W. Neves and J. S. Kowalik, "Supercomputing: Key Issues and Challenges," in NATO Advanced Research Workshop on Supercomputing, NATO ASI Series F, Vol. 62 , J.S. Kowalik, Ed., Springer-Verlag, New York (1989).
Shell Oil Supercomputing
Patric Savage
Patric Savage is a Senior Research Fellow in the Computer Science Department of Shell Development Company. He obtained a B.A. degree in mathematics from Rice University, Houston, in 1952 and began his career in computing in 1955, when he left graduate school to become Manager of Computer Programming at Hughes Tool Company. There, he led Hughes's pioneering efforts in the use of computers for inventory management, production control, and shop scheduling, using IBM-650, 305, and 1410 computers. Following a brief stint in the aerospace industry, he joined IBM in Los Angeles, where he designed a large grocery billing system and took part in a comprehensive study of hospital information systems.
Mr. Savage began his career with Shell in 1965 in seismic processing. This is an area that has grown into one of the world's largest nonmilitary computing endeavors, and Mr. Savage has remained active in this field since then as a computer scientist, consultant, and advisor. Since 1980 he has been very active in parallel and distributed computing systems R&D. For the past year he has been regularly attending the HIPPI and Fibre Channel Standards Working Group meetings. Recently he helped establish an Institute of Electrical and Electronics Engineers (IEEE) Standards Project that will eventually lead to a Storage System Standards protocol.
Mr. Savage is a member of the Computer Society, the IEEE, and the IEEE Mass Storage Technical Committee, which h e
chaired from 1986 through 1988 and for which he now chairs the Standards Subcommittee. He also chairs the Storage and Archiving Standards Subcommittee for the Society of Exploration Geophysicists and holds a life membership in Sigma Xi, the Society for Scientific Research.
I will give you a quick overview and the history of supercomputing at Shell Oil Company and then discuss our recent past in parallel computing. I will also discuss our I/O and mass-storage facility and go into what we are now doing and planning to do in parallel computing in our problem-solving environment that is under development.
Shell's involvement in high-performance computing dates from about 1963. When I arrived at Shell in 1965, seismic processing represented 95 per cent of all the scientific computing that was done in the entire company. Since then there has a been steady increase in general scientific computing at Shell. We now do a great many more reservoir simulations, and we are using codes like NASTRAN for offshore platform designs. We are also heavily into chemical engineering modeling and such.
Seismic processing has always required array processors to speed it up. So from the very beginning, we have had powerful array processors at all times. Before 1986 we used exclusively UNIVAC systems with an array processing system whose design I orchestrated. That was a machine capable of 120 million floating-point operations per second (MFLOPS) and was not a specialized device. It was a very flexible, completely programmable special processor on the UNIVAC system. We "maxed out" at 11 of those in operation. At one time we had a swing count of 13, and, for the three weeks that it lasted, we had more MFLOPS on our floor than Los Alamos National Laboratory.
In about 1986, our reservoir-simulation people were spending so much money renting time on Cray Research, Inc., machines that it was decided we could half-fund a Cray of our own. Other groups at Shell were willing to fund the other half. So that is how we got into using Cray machines. We were able and fortunate to acquire complete seismic programming codes externally and thus, we were able to jump immediately onto the Crays. Otherwise, we would have had an almost impossible conversion problem.
We began an exploratory research program in parallel computing about 1982. We formed an interdisciplinary team of seven people: three geophysicists, who were skilled at geophysical programming, and four Ph.D. computer scientists. Our goal was to enable us to make a truly giant leap ahead—to be able to develop applications that were hitherto totally
unthinkable. We have not completely abandoned that goal, although we have pulled in our horns a good bit. We acquired an nCUBE 1, a 512-node research vehicle built by nCUBE Corporation, and worked with it. That was one of the very first nCUBEs sold to industry. In the process, we learned a great deal about how to make things work on a distributed-memory parallel computer.
In early 1989, we installed a single application on our nCUBE 1 at our computer center on a 256-node machine. It actually "blows away" a CRAY X-MP CPU on that same application. But the fact that it was convincingly cost effective to management is the thing that really has spurred further growth in our parallel computing effort.
To deviate somewhat, I will now discuss our I/O and mass-storage system. (The mass-storage system that many of you may be familiar with was designed and developed at Shell in conjunction with MASSTOR Corporation.) We have what we call a virtual-tape system. The tapes are in automated libraries. We do about 8000 mounts a day. We import 2000 reels and export another 2000 every day into that system. The concept is, if a program touches a tape, it has to swallow it all. So we stage entire tapes and destage entire tapes at a time. No program actually owns a tape drive; it only is able to own a virtual tape drive. We were able to have something like 27 tape drives in our system, and we were able to be dynamically executing something like 350 virtual tape units.
The records were delivered on demand from the computers over a Network Systems Hyperchannel. This system has been phased out, now that we have released all of the UNIVACs, and today our Crays access shared tape drives that are on six automated cartridge libraries. We will have 64 tape drives on those, and our Cray systems will own 32 of those tape drives. They will stage tapes on local disks. Their policy will be the same: if you touch a tape, you have to swallow the whole tape. You either have to stage it on your own local disk immediately, as fast as you can read it off of the tape, or else you have to consume it that fast.
This system was obviously limited by the number of ports that we can have. Three Crays severely strain the number of ports that you can have, which would be something like eight. Our near-term goal is to develop a tape data server that will be accessed via a switched high-performance parallel interface (HIPPI) and do our staging onto a striped-disk server that would also be accessed over a switched HIPPI. One of the problems that we see with striped-disk servers is that there is a tremendous disparity between the bandwidth of a striped-disk system and the current 3480 tape. We now suddenly come up with striped disks that will run at rates like 80 to 160 megabytes per second. You cannot handle a
striped disk and do any kind of important staging or destaging using slow tape. I am working with George Michael, of Lawrence Livermore National Laboratory, on this problem. We have discussed use of striped tape that will be operating at rates like 100 megabytes per second. We believe that a prototype can be demonstrated in less than two years at a low cost.
Going back to parallel computing, I will share some observations on our nCUBE 1 experience. First, we absolutely couldn't go on very far without a whole lot more node memory, and the nCUBE 2 solved that problem for us. We absolutely have to have high-bandwidth external I/O. The reason that we were able to run only that one application was because that was a number-crunching application that was satisfied by about 100 kilobytes per second, input and output. So it was a number-cruncher. We were spoon-feeding it with data.
We have discovered that the programmers are very good at designing parallel programs. They do not need a piece of software that searches over the whole program and automatically parallelizes it. We think that the programmer should develop the strategy. However, we have found that programmer errors in parallel programs are devastating because they create some of the most obscure bugs that have ever been seen in the world of computing.
Because we felt that a parallel programming environment is essential, we enlisted the aid of Pacific-Sierra Research (PSR). They had a "nifty" product that many of you are familiar with, called FORGE. It was still in late development when we contacted them. We interested them in developing a product that they chose to call MIMDizer. It is a programmer's workbench for both kinds of parallel computers: those with distributed memories and those with shared memories. We have adopted this. The first two target machines are the Intel system and the nCUBE 2.
The thing that MIMDizer required in its development was that the target machine must be described by a set of parameters so that new target machines can be added easily. Then the analysis of your program will give a view of how the existing copy of your program will run on a given target machine and will urge you to make certain changes in it to make it run more effectively on a different target machine. I have suggested to PSR that they should develop a SIMDizer that would be applicable to other ![]() architectures
architectures ![]() , such as the Thinking Machines Corporation CM-2.
, such as the Thinking Machines Corporation CM-2.
I have been seriously urging PSR to develop what I would call a PARTITIONizer. I would see a PARTITIONizer as something that would help a programmer tear a program apart and break it up so that it can be
run in a distributed heterogeneous computing environment. It would be a powerful tool and a powerful adjunct to the whole package.
Our immediate plans for the nCUBE 2 are in the first quarter of 1991, when we will install a 128-node nCUBE 2, in production. For that, we will have five or six applications that will free up a lot of Cray time to run other applications that today are highly limited by lack of Cray resources.
I now want to talk about the problem-solving environment because I think there is a message here that you all should really listen to. This system was designed around 1980. Three of us in our computer science research department worked on these concepts. It actually was funded in 1986, and we will finish the system in 1992. Basically, it consists of a library of high-level primitive operations. Actually, many of these would be problem domain primitives.
The user graphically builds what we call a "flownet," or an acyclic graph. It can branch out anywhere that it wants. The user interface will not allow an illegal flownet. Every input and every output is typed and is required to attach correctly.
Every operation in the flownet is inherently parallel. Typical jobs have hundreds of operations. We know of jobs that will have thousands of operations. Some of the jobs will be bigger than you can actually run in a single machine, so we will have a facility for cutting up a superjob into real jobs that can actually be run. There will be lots of parallelism available.
We have an Ada implementation—every operation is an Ada task—and we have Fortran compute kernels. At present, until we get good vectorized compilers for Ada, we will remain with Fortran and C compute kernels. That gives us an effectiveness on the 20 per cent of the operations that really are squeaking wheels. We have run this thing on a CONVEX Computer Corporation Ada system. CONVEX, right now, is the only company we found to have a true multiprocessing Ada system. That is, you can actually run multiple processors on the CONVEX Ada system, and you will get true multiprocessing. We got linear speedup when we ran on the CONVEX system, so we know that this thing is going to work. We ran it on a four-processor CONVEX system, and it ran almost four times as fast—something like 3.96 times as fast—as it did with a single processor.
This system is designed to run on workstations and Crays and everything else in between. There has been a very recent announcement of an Ada compiler for the nCUBE 2, which is cheering to us because we did not know how we were going to port this thing to the nCUBE 2. Of course, I still do not know how we will port to any other parallel environment unless they develop some kind of an Ada capability.
Government's High Performance Computing Initiative Interface with Industry
Howard E. Simmons
Howard E. Simmons is Vice President and Senior Science Advisor in E. I. du Pont de Nemours and Company, where for the past 12 years he headed corporate research. He has a bachelor's degree from MIT in chemistry and a Ph.D. from the same institution in physical organic chemistry. He was elected to the National Academy of Sciences in 1975 and has been a Visiting Professor at Harvard University and the University of Chicago. His research interests have ranged widely from synthetic and mechanistic chemistry to quantum chemistry. Most recently, he has coauthored a book on mathematical topological methods in chemistry with R. E. Merrifield
It is a pleasure for me to participate in this conference and share with you my perspectives on supercomputing in the industrial research, development, and engineering environments.
I will talk to you a little bit from the perspective of an industry that has not only come late to supercomputing but also to computing in general from the science standpoint. Computing from the engineering standpoint, I think, came into the chemical industry very early, and E. I. du Pont de Nemours and Company (du Pont) was one of the leaders.
Use of supercomputers at du Pont is somewhat different from the uses we see occurring in the national laboratories and academia. The differences are created to a large extent by the cultures in which we operate and
the institutional needs we serve. In that context, there are three topics I will cover briefly. The first is "culture." The second is supercomputer applications software. The third is the need for interfaces to computer applications running on PCs, workstations, minicomputers, and supercomputers of differing types—for example, massively parallels.
As I mentioned in regard to culture, the industrial research, development, and engineering culture differs from that of the national laboratories and academia. I think this is because our objective is the discovery, development, manufacture, and sale of products that meet customer needs and at the same time make a profit for the company. This business orientation causes us to narrow the scope of our work and focus our efforts on solving problems of real business value in those areas in which we have chosen to operate. Here I am speaking about the bulk of industrial research, although work at AT&T's Bell Laboratories, du Pont's Central Research, and many other corporate laboratories, for instance, do follow more closely the academic pattern.
A second cultural difference is that most of the R&D effort, and consequently our staffing, has been directed toward traditional experimental sciences. We have rarely, in the past, been faced with problems that could be analyzed and solved only through computational methods. Hence, our computational science "tradition" is neither as long-standing nor as diverse as found in the other sectors or in other industries.
A significant limitation and hindrance to broad industrial supercomputer use is the vision of what is possible by the scientists and engineers who are solving problems. So long as they are satisfied with what they are doing and the way they are doing it, there is not much driving force to solve more fundamental, bigger, or more complex problems. Thus, in our industry, a lot of education is needed, not only for the supercomputer area but also in all advanced computing. We believe we are making progress in encouraging a broader world view within our technical and managerial ranks. We have been having a lot of in-house symposia, particularly in supercomputing, with the help of Cray Research, Inc. We invited not just potential users of the company but also middle managers, who are key people to convince on the possible needs that their people will have in more advanced computing.
Our company has a policy of paying for resources used. This user-based billing practice causes some difficulty for users in justifying and budgeting for supercomputer use, particularly in the middle of a fiscal cycle. A typical example is that scientists and engineers at a remote plant site—in Texas, for example—may see uses for our Cray back in Wilmington, Delaware. They have a lot of trouble convincing their
middle management that this is any more than a new toy or a new gimmick. So we have done everything that we can, including forming SWAT teams that go out and try to talk to managers throughout the corporation in the research area and give them some sort of a reasonable perspective of what the corporation's total advanced computing capabilities are.
The cultural differences between the national laboratories, universities, and industry are certainly many, but they should not preclude mutually beneficial interactions. The diversity of backgrounds and differences in research objectives can and should be complementary if we understand each other's needs.
The second major topic I will discuss is software, specifically applications software. We presume for the present time that operating systems, communications software, and the like will be largely provided by vendors, at least certainly in our industry. There are several ways to look at the applications software issue. The simplest is to describe our strategies for acquiring needed analysis capabilities involving large "codes." In priority, the questions we need to ask are as follows:
• Has someone else already developed the software to solve the problem or class of problems of interest to us? If the answer is yes, then we need to take the appropriate steps to acquire the software. In general, acquisition produces results faster and at lower cost than developing our own programs.
• Is there a consortium or partnership that exists or might be put together to develop the needed software tools? If so, we should seriously consider buying in. This type of partnering is not without some pitfalls, but it is one that appeals to us.
• Do we have the basic expertise and tools to develop our own special-purpose programs in advanced computing? The answer here is almost always yes, but rarely is it a better business proposition than the first two options. This alternative is taken only when there is no other viable option.
To illustrate what's been happening, our engineers have used computers for problem solving since the late 1950s. Since we were early starters, we developed our own programs and our own computer expertise. Today, commercial programs are replacing many of our "home-grown" codes. We can no longer economically justify the resources required to develop and maintain in-house versions of generic software products. Our engineers must concentrate on applying the available computational tools faster and at lower life-cycle costs than our competition.
Our applications in the basic sciences came later and continue to undergo strong growth. Many of our scientists write their own code for their original work, but here, too, we face a growing need for purchased software, particularly in the molecular-dynamics area.
Applications software is an ever-present need for us. It needs to be reasonably priced, reliable, robust, and have good documentation. In addition, high-quality training and support should be readily available. As we look forward to parallel computers, the severity of the need for good applications software will only increase, since the old and proven software developed for serial machines is becoming increasingly inadequate for us.
Finally, integration of supercomputers into the infrastructure or fabric of our R&D and engineering processes is not easy. I believe it to be one of the primary causes for the slow rate of penetration in their use.
For the sake of argument, assume that we have an organization that believes in and supports computational science, that we have capable scientists and engineers who can use the tools effectively, that the computers are available at a reasonable cost, and that the needed software tools are available. All of these are necessary conditions, but they are not sufficient.
Supercomputers historically have not fit easily into the established computer-based problem-solving environments, which include personal computers, workstations, and minicomputers. In this context, the supercomputer is best viewed as a compute engine that should be almost transparent to the user. To make the supercomputer transparent requires interfaces to these other computing platforms and the applications running on them. Development of interfaces is an imperative if we are going to make substantial inroads into the existing base of scientific and engineering applications. The current trend toward UNIX-based operating systems greatly facilitates this development. However, industry tends to have substantial investments in computer systems running proprietary operating systems (e.g., IBM/MVS, VAX/VMS, etc.).
Three brief examples of our supercomputer applications might help to illustrate the sort of things we are doing and a little bit about our needs. In the first example, we design steel structures for our manufacturing plants using computer-aided design tools on our Digital Equipment Corporation VAX computers. Central to this design process is analysis of the structure using the NASTRAN finite-element analysis program. This piece of the design process is, of course, very time consuming and compute intensive. To break that bottleneck, we have interfaced the
design programs to our CRAY X-MP, where we do the structural analyses. It is faster by a factor of 20 to 40 in our hands, a lot lower in cost, and it permits us to do a better design job. We can do a better job with greater compute power so that we can do seismic load analyses even when the structures are not in high-risk areas. This, simply for economic reasons, we did not always do in the past. This capability and vision lead to new approaches to some old problems.
The second example is—as we explore new compounds for application and new products—part of the discovery process that requires the determination of bulk physical properties. In selected cases we are computing these in order to expedite the design and development of commercial manufacturing facilities. We find high value in areas ranging from drug design to structural property relations in polymers. A good example is the computation of basic thermodynamic properties of such small halocarbons as Freon chlorofluorocarbon replacements. This effort is critical to our future and the viability of some of our businesses. It is very interesting to note that these are ab initio quantum mechanical calculations that are being used directly in design of both products and plants. So in this case we have had no problem in convincing the upper management in one of the most traditional businesses that we have of the great value of supercomputers because this is necessary to get some of these jobs done. We gain a substantial competitive advantage by being able to develop such data via computational methodologies and not just experimentally. Experimental determination of these properties can take much longer and cost more.
A third example, atmospheric chemistry modeling to understand and to assess the impact of particular compounds in the ozone-depletion problem—and now global warming—is another area where we have had a significant supercomputer effort over many years. This effort is also critical to the future and viability of some of our businesses. As a consequence, this is an area where we chose to develop our own special-purpose programs, which are recognized as being state of the art.
In looking forward, what can we do together? What would be of help to us in industry?
One answer is to explore alternatives for integrating supercomputers into a heterogeneous network of computer applications and workstations so they can be easily accessed and utilized to solve problems where high-performance computing is either required or highly desirable.
Second, we could develop hardware and software to solve the grand challenges of science. Although it may not be directly applicable to our
problems, the development of new and novel machines and algorithms will benefit us, particularly in the vectorization and parallelization of algorithms.
Third, we might develop applications software of commercial quality that exploits the capabilities of highly parallel supercomputers.
Fourth, we could develop visualization hardware and software tools that could be used effectively and simply by our scientists and engineers to enhance their projects. We would be anxious to cooperate with others jointly in any of these sorts of areas.
The bottom line is that we, in our innocence, believe we are getting real business value from the use of supercomputers in research, development, and engineering work. However, to exploit this technology fully, we need people with a vision of what is possible, we need more high-quality software applications—especially for highly parallel machines—and we need the capability to easily integrate supercomputers into diverse problem-solving environments. Some of those things, like the latter point, are really our job. Yet we really need the help of others and would be very eager, I think, to work with a national laboratory in solving some problems for the chemical industry.
An Overview of Supercomputing at General Motors Corporation
Myron Ginsberg
Myron Ginsberg currently serves as Consultant Systems Engineer at the Electronic Data Systems Advanced Computing Center, General Motors Research and Environmental Staff, Warren, Michigan. Until May 1992, he was Staff Research Scientist at General Motors Research Laboratories.
During a 13-year tenure at General Motors, Dr. Ginsberg was significantly involved in GM's initial and continuing supercomputer efforts, which led to the first installation of a Cray supercomputer in the worldwide auto industry. He is also Adjunct Associate Professor in the Electrical Engineering and Computer Science Department, College of Engineering, at the University of Michigan. He has edited four volumes on vector/parallel computing applications in the auto industry. He has three times been the recipient of the Society of Automotive Engineers' (SAE's) Award for Excellence in Oral Presentation and has earned the SAE Distinguished Speaker Plaque, as well. Dr. Ginsberg serves on the Editorial Board of Computing Systems in Engineering and on the Cray Research, Inc., Fortran Advisory Board. He has also been a Distinguished National Lecturer for the American Society of Mechanical Engineers, the Society for Industrial and Applied Mathematics, and the Association for Computing Machinery .
Abstract
The use of supercomputers at General Motors Corporation (GM) began in the GM Research Laboratories (GMR) and has continued there, spreading to GM Divisions and Staffs, as well. Topics covered in this paper include a review of the computing environment at GM, a brief history of GM supercomputing, worldwide automotive use of supercomputers, primary GM applications, long-term benefits, and the challenges for the future.
Introduction
In this paper, we will review the computing environment at GM, give a brief history of corporate supercomputing, indicate worldwide automotive utilization of supercomputers, list primary applications, describe the long-term benefits, and discuss the needs and challenges for the future.
People and the Machine Environment
Supercomputing activities at GM have been focused primarily on projects in GMR and/or cooperative activities between GMR and one or more GM Divisions or Staffs.
There are approximately 900 GMR employees, with about 50 per cent of these being R&D professionals. In this latter group, 79 per cent have a Ph.D., 18 per cent an M.S., and 3 per cent a B.S. as their highest degree. In addition, there are Electronic Data Systems (EDS) personnel serving in support roles throughout GM.
General Motors was the first automotive company to obtain its own in-house Cray Research supercomputer, which was a CRAY 1S/2300 delivered to GMR in late 1983. Today, GM has a CRAY Y-MP4/364 at GMR, a CRAY Y-MP4/232 at an EDS center in Auburn Hills, Michigan, and a CRAY X-MP/18 at Adam Opel in Germany. Throughout GM, there is a proliferation of smaller machines, including a CONVEX Computer Corporation C-210 minisuper at B-O-C Flint, Michigan, IBM mainframes, Digital Equipment Corporation (DEC) minis, a Stardent 2000 graphics super at C-P-C Engineering, numerous Silicon Graphics high-end workstations, and a large collection of workstations from IBM, Sun Microsystems, Inc., Apollo (Hewlett-Packard), and DEC. There is extensive networking among most of the machines to promote access across GM sites.
History of Supercomputing at GM
Table 1 summarizes GM's involvement with supercomputers. In 1968, GMR entered into a joint effort with Control Data Corporation (CDC) to explore the potential use of the STAR-100 to support graphics consoles. A prototype of that machine, the STAR 1-B, was installed at GMR. This project was terminated in 1972.
GM next started looking at supercomputers in late 1979. At that time the GM computing environment was dominated by several IBM mainframes (IBM 3033). Scientists and engineers developed an intuitive feel with respect to sizing their programs. They were aware that if they exceeded certain combinations of memory size and CPU time, then their job would not be completed the same day. They tried to stay within those bounds, but that became extremely difficult to do as the physical problems being considered grew increasingly complex and as they sought to develop two- and three-dimensional models.
In 1981, benchmarks were gathered both from GMR and GM Staffs and Divisions for testing on the CRAY-1 and on the CDC CYBER 205. These benchmarks included representative current and anticipated future work that would require very-large-scale computations. The results indicated that the CRAY-1 would best satisfy our needs. To get initial experience of our employees on that machine, we began to use a CRAY-1 at Boeing Computer Services and tried to ramp up our usage until such time as we could economically utilize our own in-house CRAY. Finally, in late 1983, a CRAY-1S/2300 was delivered to GMR and was in general use in early 1984. The utilization of that machine steadily grew until it was replaced by a CRAY X-MP/24 in 1986, and then that machine was replaced by a two-processor CRAY Y-MP in late 1989, with an additional CPU upgrade in early 1991. Other Cray supercomputers at GM were introduced at Adam Opel in 1985 and at EDS in 1991.
Automotive Industry Interest in Supercomputers
At about the same time GM acquired its own Cray supercomputer in late 1983, Chrysler obtained a CDC CYBER 205 supercomputer. Then in early 1985, Ford obtained a CRAY X-MP/11. As of late 1991, there were approximately 25 Cray supercomputers worldwide in automotive companies in addition to several nonautomotive Crays used by auto companies.
| ||||||||||||||||||||||||||
Figure 1 portrays an interesting trend in the growth of supercomputers within the worldwide automotive community. It depicts the number of Cray CPUs (not machines), including both X-MP and Y-MP processors, in the U.S., Europe, and the Far East in 1985, 1988, and 1991. In 1985, no automotive Cray CPUs existed in the Far East, and only two were in use in the U.S. (GM and Ford). In sharp contrast, at the end of 1991, there were 26 Cray CPUs (13 machines) in the Far East, compared with a total of 14 (four machines) in all U.S. auto companies! The specific breakdown by machines is given in Table 2; the ranking used is approximately by total CPU computational power and memory. We note that the Far East, specifically Japanese, auto companies occupy five of the top 10 positions. Their dominance would be even more obvious in Figure 1 if Japanese supercomputer CPUs were included; several of the Far East auto companies own or have access to one or more such machines in addition to their Crays.
It is interesting to note that once the first supercomputer was delivered to the automotive industry in late 1983, just about every major car company in the world began to acquire one or more such machines for in-house use within the following eight years, as evidenced by Figure 1 and Table 2.
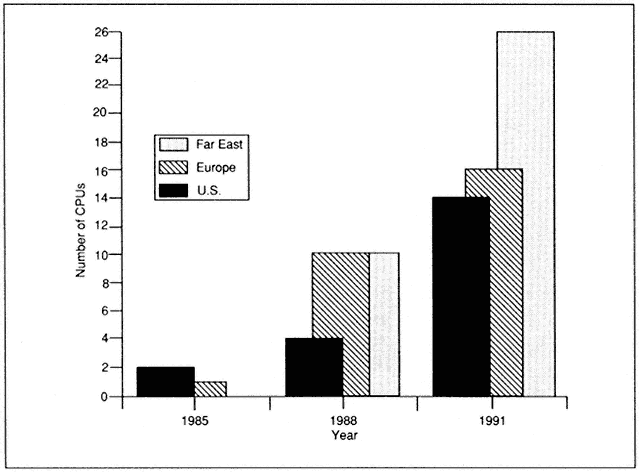
Figure 1.
Geographic distribution of installed Cray CPUs in the world auto industry, 1985–91.
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
One of the reasons for the initial delay to introduce supercomputers in the auto industry was a significant economic downturn in the early 1980s, combined with the high cost of supercomputers at that time ($5 million to $10 million range). There was also a reluctance to acquire a machine that might not be filled to capacity for quite a while after acquisition. Nevertheless, U.S., European, and the Far East auto companies began experimenting with supercomputers at service bureaus during the early 1980s.
The early acquisition of supercomputers by U.S. government labs, such as Los Alamos and Livermore, helped to spearhead the future use of supercomputers by auto companies, as well as by other businesses in private industry. The experience gained with adapting programs to
supercomputers was reported in the open literature, as well as at professional meetings where people from the automotive industry could interact with personnel from the national laboratories. Furthermore, many of the programs developed at those labs became available in the public domain. Also, some joint cooperative projects began to develop between the national labs and U.S. auto companies.
Applications
Table 3 summarizes many of the supercomputer applications currently running at GM.
Most of the supercomputer applications represent finite element or finite difference two- or three-dimensional mathematical models of physical phenomena. Both early and current applications at GM have been dominated by work in the aerodynamics area (computational fluid dynamics), combustion modeling, and structural analysis (including crashworthiness analysis); see, for example, Hammond (1985), Meintjes
|
(1986), Grubbs (1985), Haworth and El Tahry (1990), Haworth et al. (1990), El Tahry and Haworth (1991), Ginsberg (1988, 1989), Ginsberg and Johnson (1989), Ginsberg and Katnik (1990), Johnson and Skynar (1989), Khalil and Vander Lugt (1989), and Shkolnikov et al. (1989). This work involves both software developed in-house (primarily by GMR personnel) and use of commercial packages (used primarily by personnel in GM Divisions and Staffs). Within the past several years, additional applications have utilized the GMR supercomputer; see, for example, sheet-metal-forming applications as discussed by Chen (May 1991, July 1991), Chen and Waugh (1990), and Stoughton and Arlinghaus (1990). A most recent application by the newly formed Saturn Corporation is using the GMR Cray and simulation software to design strategically placed "crush zones" to help dissipate the energy of a crash before it reaches vehicle occupants (General Motors Corporation 1991).
In addition to the use of the Cray supercomputer, GMR scientists and engineers have been experimenting with other high-performance computers, such as hypercube and transputer-based ![]() architectures
architectures ![]() . Such machines provide a low-cost, distributed parallel computing facility. Recent work in this area on such machines includes that described by Baum and McMillan (1988, 1989), Malone (1988, 1989, 1990), Malone and Johnson (1991a, 1991b), and Morgan and Watson (1986, 1987). A more complete list of GM applications of high-performance computers is given by Ginsberg (1991).
. Such machines provide a low-cost, distributed parallel computing facility. Recent work in this area on such machines includes that described by Baum and McMillan (1988, 1989), Malone (1988, 1989, 1990), Malone and Johnson (1991a, 1991b), and Morgan and Watson (1986, 1987). A more complete list of GM applications of high-performance computers is given by Ginsberg (1991).
Long-Term Benefits
There are several factors that justify the use of supercomputers for automotive applications. For example, the speed of such machines makes it possible to perform parameter studies early in the design cycle, when there is only a computer representation of the vehicle, and even a physical prototype may not yet exist; at that stage, a scientist or engineer can ask "what if" questions to try to observe what happens to the design as specific parameters or combination of parameters are changed. Such observations lead to discarding certain design approaches and adopting others, depending upon the results of the computer simulations. This can reduce the amount of physical prototyping that has to be done and can lead to significant improvements in quality of the final product. Other long-term benefits include improved product safety via crashworthiness modeling and greater fuel economy via aerodynamics simulations.
Accurate computer simulations have the potential to save money by reducing both the number of physical experiments that need to be
performed and the time to prepare for the physical testing. For example, in the crashworthiness area, each physical crash involves a custom, handmade car that can only be used once and may take several months to build. Furthermore, the typical auto industry cost of performing one such physical crash on a prototype vehicle can be upwards of $750,000 to $1,000,000 per test! It thus becomes apparent that realistic computer simulations have the potential to produce substantial cost savings.
The successful application of supercomputers in all phases of car design and manufacturing can hopefully lead to significant reductions in the lead time necessary to bring a new product to market. The use of supercomputers in the auto industry is still in its infancy. Creative scientists and engineers are just beginning to explore the possibilities for future automotive applications.
Needs and Challenges
Los Alamos National Laboratory received its first Cray in 1976, but the American automotive community did not begin acquiring in-house supercomputers until over seven years later. The American automobile industry needs more immediate access to new supercomputer technologies in order to rapidly utilize such machines for its specific applications. This will require growth in cooperative efforts with both government laboratories and universities to explore new ![]() architectures
architectures ![]() , to create highly efficient computational algorithms for such
, to create highly efficient computational algorithms for such ![]() architectures
architectures ![]() , and to develop the necessary software support tools.
, and to develop the necessary software support tools.
Another challenge for the future is in the networking area. Supercomputers must be able to communicate with a diverse collection of computer resources, including other supercomputers, and this requires very high bandwidth communication networks, particularly if visualization systems are to be developed that allow real-time interaction with supercomputer simulations.
The demand for faster and more realistic simulations is already pushing the capabilities of even the most sophisticated uniprocessor ![]() architectures
architectures ![]() . Thus, we must increase our investigation of parallel
. Thus, we must increase our investigation of parallel ![]() architectures
architectures ![]() and algorithms. We must assess the tradeoffs in using supercomputers, minisupers, and graphics supers. We must determine where massively parallel machines are appropriate. We must be able to develop hybrid approaches where portions of large problems are assigned to a variety of
and algorithms. We must assess the tradeoffs in using supercomputers, minisupers, and graphics supers. We must determine where massively parallel machines are appropriate. We must be able to develop hybrid approaches where portions of large problems are assigned to a variety of ![]() architectures
architectures ![]() , depending upon which machine is the most efficient for dealing with a specific section of computation. This again requires cooperative efforts among private industry, government labs,
, depending upon which machine is the most efficient for dealing with a specific section of computation. This again requires cooperative efforts among private industry, government labs,
and universities; commercial tools must be developed to assist scientists and engineers in producing highly efficient parallel programs with a minimal amount of user effort.
Realistic simulations demand visualization rather than stacks of computer paper. Making videos should become routine for scientists and engineers; it should not be necessary for such persons to become graphics experts to produce high-quality, realistic videos. In the automotive industry, videos are being produced, particularly in the crashworthiness (both side-impact and frontal-barrier simulations) and aerodynamics areas.
The challenges above are not unique to the auto industry alone. Rapid U.S. solutions to these needs could help the American automotive industry to increase its competitiveness in the world marketplace.
References
A. M. Baum and D. J. McMillan, "Message Passing in Parallel Real-Time Continuous System Simulations," General Motors Research Laboratories publication GMR-6146, Warren, Michigan (January 27, 1988).
A. M. Baum and D. J. McMillan, "Automated Parallelization of Serial Simulations for Hypercube Parallel Processors," in Proceedings, Eastern Multiconference on Distributed Simulation , Society for Computer Simulation, San Diego, California, pp. 131-136 (1989).
K. K. Chen, "Analysis of Binder Wrap Forming with Punch-Blank Contact," General Motors Research Laboratories publication GMR-7330, Warren, Michigan (May 1991).
K. K. Chen, "A Calculation Method for Binder Wrap with Punch Blank Contact," General Motors Research Laboratories publication GMR-7410, Warren, Michigan (July 1991).
K. K. Chen and T. G. Waugh, "Application of a Binder Wrap Calculation Model to Layout of Autobody Sheet Steel Stamping Dies," Society of Automotive Engineers paper 900278, Warrendale, Pennsylvania (1990).
S. H. El Tahry and D. C. Haworth, "A Critical Review of Turbulence Models for Applications in the Automotive Industry," American Institute of Aeronautics and Astronautics paper 91-0516, Washington, DC (January 1991).
General Motors Corporation, "Saturn Sales Brochure," S02 00025 1090 (1991).
M. Ginsberg, "Analyzing the Performance of Physical Impact Simulation Software on Vector and Parallel Processors," in Third International Conference on Supercomputing: Supercomputing 88, Vol. 1, Supercomputer Applications , L. P. Kartashev and S. I. Kartashev, Eds., International Supercomputer Institute, Inc., St. Petersburg, Florida, pp. 394-402 (1988).
M. Ginsberg, "Computational Environmental Influences on the Performance of Crashworthiness Programs," in Crashworthiness and Occupant Protection in Transportation Systems , T. B. Khalil and A. I. King, Eds., American Society of Mechanical Engineers, New York, pp. 11-21 (1989).
M. Ginsberg, "The Importance of Supercomputers in Car Design/Engineering," in Proceedings, Supercomputing USA/Pacific 91 , Meridian Pacific Group, Inc., Mill Valley, California, pp. 14-17 (1991).
M. Ginsberg and J. P. Johnson, "Benchmarking the Performance of Physical Impact Simulation Software on Vector and Parallel Computers," in Supercomputing '88, Vol. II, Science and Applications , J. L. Martin and S. F. Lundstrom, Eds., Institute of Electrical and Electronics Engineers Computer Society Press, Washington, D.C., pp. 180-190 (1989).
M. Ginsberg and R. B. Katnik, "Improving Vectorization of a Crashworthiness Code," Society of Automotive Engineers paper 891985, Warrendale, Pennsylvania; also in SAE Transactions , Sec. 3, Vol. 97, Society of Automotive Engineers, Warrendale, Pennsylvania (September 1990).
D. Grubbs, "Computational Analysis in Automotive Design," Cray Channels7 (3), 12-15 (1985).
D. C. Hammond Jr., "Use of a Supercomputer in Aerodynamics Computations at General Motors Research Laboratories," in Supercomputers in the Automotive Industry , M. Ginsberg, Ed., special publication SP-624, Society of Automotive Engineers, Warrendale, Pennsylvania, pp. 45-51 (July 1985).
D. C. Haworth and S. H. El Tahry, "A PDF Approach for Multidimensional Turbulent Flow Calculations with Application to In-Cylinder Flows in Reciprocating Engines," General Motors Research Laboratories publication GMR-6844, Warren, Michigan (1990).
D. C. Haworth, S. H. El Tahry, M. S. Huebler, and S. Chang, "Multidimensional Port-and-Cylinder Flow Calculations for Two- and Four-Valveper-Cylinder Engines: Influence of Intake Configuration on Flow Structure," Society of Automotive Engineers paper 900257, Warrendale, Pennsylvania (February 1990).
J. P. Johnson and M. J. Skynar, "Automotive Crash Analysis Using the Explicit Integration Finite Element Method," in Crashworthiness and Occupant Protection in Transportation Systems , T. B. Khalil and A. I. King, Eds., American Society of Mechanical Engineers, New York, pp. 27-32 (1989).
T. B. Khalil and D. A. Vander Lugt, "Identification of Vehicle Front Structure Crashworthiness by Experiments and Finite Element Analysis," in Crashworthiness and Occupant Protection in Transportation Systems , T. B. Khalil and A. I. King, Eds., American Society of Mechanical Engineers, New York, pp. 41-51 (1989).
J. G. Malone, "Automated Mesh Decomposition and Concurrent Finite Element Analysis for Hypercube Multiprocessor Computers," Computer Methods in Applied Mechanics and Engineering70 (1), 27-58 (1988).
J.G. Malone, "High Performance Using a Hypercube ![]() Architecture
Architecture ![]() for Parallel Nonlinear Dynamic Finite Element Analysis," in Proceedings, Fourth International Conference on Supercomputing: Supercomputing 89, Vol. 2, Supercomputer Applications , L. P. Kartashev and S. I. Kartashev, Eds., International Supercomputer Institute, Inc., St. Petersburg, Florida, pp. 434-438 (1989).
for Parallel Nonlinear Dynamic Finite Element Analysis," in Proceedings, Fourth International Conference on Supercomputing: Supercomputing 89, Vol. 2, Supercomputer Applications , L. P. Kartashev and S. I. Kartashev, Eds., International Supercomputer Institute, Inc., St. Petersburg, Florida, pp. 434-438 (1989).
J. G. Malone, "Parallel Nonlinear Dynamic Finite Element Analysis of Three-Dimensional Shell Structures," Computers and Structures35 (5), 523-539 (1990).
J. G. Malone and N. L. Johnson, "A Parallel Finite Element Contact/Impact Algorithm for Nonlinear Explicit Transient Analysis: Part I, The Search Algorithm and Contact Mechanics," General Motors Research Laboratories publication GMR-7478, Warren, Michigan (1991a).
J. G. Malone and N. L. Johnson, "A Parallel Finite Element Contact/Impact Algorithm for Nonlinear Explicit Transient Analysis: Part II, Parallel Implementation," General Motors Research Laboratories publication GMR-7479, Warren, Michigan (1991b).
K. Meintjes, "Engine Combustion Modeling: Prospects and Challenges," Cray Channels8 (4), 12-15 (1987); extended version in Supercomputer Applications in Automotive Research and Engineering Development , C. Marino, Ed., Computational Mechanics Publications, Southhampton, United Kingdom, pp. 291-366 (1986).
A. P. Morgan and L. T. Watson, "Solving Nonlinear Equations on a Hypercube," in ASCE Structures Congress '86: Super and Parallel Computers and Their Impact on Civil Engineering , M. P. Kamat, Ed., American Society of Civil Engineers, New Orleans, Louisiana, pp. 1-15 (1986).
A. P. Morgan and L. T. Watson, "Solving Polynomial Systems of Equations on a Hypercube," in Hypercube Multiprocessors , M. T. Heath, Ed., Society for Industrial and Applied Mathematics, Philadelphia, Pennsylvania, pp. 501-511 (1987).
M. B. Shkolnikov, D. M. Bhalsod, and B. Tzeng, "Barrier Impact Test Simulation Using DYNA3D," in Crashworthiness and Occupant Protection in Transportation Systems , T. B. Khalil and A. I. King, Eds., American Society of Mechanical Engineers, New York, pp. 33-39 (1989).
T. Stoughton and F. J. Arlinghaus, "Sheet Metal Forming Simulation Using Finite Elements," Cray Channels12 (1), 6-11 (1990).
Barriers to Use of Supercomputers in the Industrial Environment
Robert Hermann
Robert J. Hermann was elected Vice President, Science and Technology, at United Technologies Corporation (UTC) in March 1987. In this position, Dr. Hermann is responsible for assuring the development of the company's technical resources and the full exploitation of science and technology by the corporation. He also has responsibility for the United Technologies Research Center and the United Technologies Microelectronics Center. Dr. Hermann joined UTC in 1982 as Vice President, Systems Technology, in the electronics sector. He was named Vice President, Advanced Systems, in the Defense Systems Group in 1984.
Dr. Hermann served 20 years with the National Security Agency, with assignments in research and development, operations, and NATO. In 1977 he was appointed principal Deputy Assistant Secretary of Defense for Communications, Command, Control, and Intelligence. He was named Assistant Secretary of the Air Force for Research, Development, and Logistics in 1979 and Special Assistant for Intelligence to the Undersecretary of Defense for Research and Engineering in 1981.
He received B.S., M.S., and Ph.D. degrees in electrical engineering from Iowa State University, Ames, Iowa. Dr. Hermann is a member of the National Academy of Engineering, the Defense Science Board, and the National Society of Professional Engineers' Industry Advisory Group. He is also
Chairman of the Naval Studies Board and of the Executive Committee of the Navy League's Industrial Executive Board.
I will discuss my point of view, not as a creator of supercomputing-relevant material or even as a user. I have a half-step in that primitive class called management, and so I will probably reflect most of that point of view.
United Technologies Corporation (UTC) makes jet engines under the name of Pratt and Whitney. We make air conditioners under the name of Carrier. We make elevators under the name of Otis. We make a very large amount of automobile parts under our own name. We make helicopters under the name of Sikorsky and radars under the name of Norden.
There is a rich diversity between making elevators and jet engines. At UTC we are believers in supercomputation—that is, the ability to manage the computational advantages that are qualitatively different today than they were five years ago; and they will probably be qualitatively different five years from now.
The people in Pratt and Whitney and in the United Technologies Research Center who deal with jet engines have to deal with high-temperature, high-Mach-number, computational fluid dynamics where the medium is a plasma. These are nontrivial technical problems, and the researchers are interested in three-dimensional Navier-Stokes equations, and so on. It is in an industry where being advanced has visible, crucial leverage, which in turn results in motivation. Thus, there are pockets in UTC where I would say we really do believe, in an analytic sense, in design, process, simulation, and visualization.
It seems to me that when I use the term "supercomputation," I have to be in some sense connoting doing things super—doing things that are unthinkable or, at least, unprecedented. You have to be able to do something that you just would not have even tried before. Thus, an important barrier in "supercomputation" is that it requires people who can think the unthinkable, or at least the unprecedented. They have to have time, they have to have motivation, and they have to have access.
Also, those same people clearly have to have hardware, software, math, physics, application, and business perspectives in their head. The critical ingredient is that you need, in one intellect, somebody who understands the software, the hardware, the mathematics to apply it, the physics to understand the principles, and the business application. This is a single-intellect problem or, at least, a small-group problem. If you do not have this unity, you probably cannot go off and do something that was either unthinkable or unprecedented. Getting such individuals and groups together is indeed a barrier.
A business point of view will uncover another big barrier in the way we organize our businesses and the way that businesses are practiced routinely. The popular way of doing business is that the total business responsibility for some activity is placed in the hands of a manager. Total business responsibility means that there are many opportunities to invest various kinds of resources: time, money, management. Supercomputation is certainly not the thing that leaps to mind the first time when someone in most businesses is asked, "What are some of the big, burning problems you have?"
In our environment, you legitimately have to get the attention of the people who have the whole business equation in their heads and in their responsibility packages. One thing that does get attention is to say that small purchases are easier to make than large purchases. UTC is a very large corporation. At $20 billion and 200,000 employees, you would think that at that level you could afford to make large purchases. However, we have broken the company down in such a way that there are no large outfits. It is a collection of small outfits such that it is more than ten times easier to make ten $100,000 purchases than one $1 million purchase. That equation causes difficulty for the general problem of pulling in the thing called supercomputation because in some sense, supercomputation cannot be bought in small packages. Otherwise, it isn't super.
It is also true that the past experiences of the people who have grown up in business are hard to apply to supercomputation. It is not like building a factory. A factory, they know, makes things.
UTC is an old-line manufacturing outfit. We are one of thousands of old-line manufacturing outfits that exist on a global basis. We are the class of folks who make the money in the world that supports all the research, development, and investment.
The people who are in charge do not naturally think in terms of supercomputation because it is moving too fast. We have to educate that set of people. It is not an issue of pointing fingers in blame, although we are representative. But I would also say to someone who is trying to promote either the application of supercomputation as a field or national competitiveness through the use of supercomputation, "This is a barrier that has to be overcome." It will probably not be overcome totally on the basis of the motivation of the structure of the corporation itself.
We need to be educated, and I have tried to figure out what is inhibiting our using supercomputers. Several possible answers come to mind.
First, we do not know how to relate the advantage to our business. And we do not have time to do it, because our nose is so pressed to the grindstone trying to make money or cash flow or some other financial equation. The
dominance of the financial equation is complete as it is, and it is fundamental to the existence of the economic entity. But somehow or another, there has to be some movement toward making people know more about the application of supercomputers to their business advantage.
Another issue is the question of how to pay for supercomputers. If you purchase large items that are larger than the normal business element can buy, you have to cooperate with somebody else, which is a real big barrier because cooperating with somebody else is difficult.
Also, how you do the cost accounting is a nontrivial business. Indeed, we at UTC probably would not have a Cray if it had not been forced on us by the National Aerospace Plane Program Office. When we got it, we tried to figure out how to make it useful across the corporation, and we were hindered, obstructed, and eventually deterred in every way by the cost-accounting standards applied by the government.
Now, what are we doing about it? I would say we are trying to do something about it, although we may be way behind as a culture and as a group. We are trying to build on those niche areas where we have some capability, we are trying to use our own examples as precedents, we are surveying ourselves to try to understand what is meaningful, and we are trying to benchmark ourselves against others.
In 1989 we participated in some self-examination that we did over the course of the year. We have agreed that we are going to establish a network in which we can do scientific computation in a joint venture with laboratories, etc., to transport the necessary technology.
This is also a national issue. The national competitiveness issue must be somewhere out there at the forefront. In the national competitiveness area, to become a patriot, supercomputation is important—as infrastructure, not as a subsidy. I would think that some notion of an infrastructure, which has some geographic preference to it, is likely to be needed. I would therefore argue that networked data highways and attached supercomputation networks have some national competitiveness advantages, which are a little bit different from the totally distributed minicomputer that you can ship anywhere and that does not have a particular geographic or national preference associated with it.
From a national point of view, and as a participant in national affairs, I can have one view. But from a corporate point of view, I am somewhat neutral on the subject: if we do not do it in the U.S., the Europeans probably will, and the Japanese probably will; and we will then have to use the European-Japanese network because it is available as a multinational corporation.