LINPACK Benchmark
Perhaps the best-known part of that package—indeed, some people think it is LINPACK—is the benchmark that grew out of the documentation. The so-called LINPACK Benchmark (Dongarra 1991) appears in the appendix to the user's guide. It was intended to give users an idea of how long it would take to solve certain problems. Originally, we measured
the time required to solve a system of equations of order 100. We listed those times and gave some guidelines for extrapolating execution times for about 20 machines.
The times were gathered for two routines from LINPACK, one (SGEFA) to factor a matrix, the other (SGESL) to solve a system of equations. These routines are called the BLAS, where most of the floating-point computation takes place. The routine that sits in the center of that computation is a SAXPY, taking a multiple of one vector and adding it to another vector:
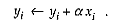
Table 1 is a list of the timings of the LINPACK Benchmark on various high-performance computers.
The peak performance for these machines is listed here in millions of floating-point operations per second (MFLOPS), in ascending order from 16 to 3000. The question is, when we run this LINPACK Benchmark,
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
what do we actually get on these machines? The column labeled "Actual MFLOPS" gives the answer, and that answer is quite disappointing in spite of the fact that we are using an algorithm that is highly vectorized on machines that are vector architectures. The next question one might ask is, why are the results so bad? The answer has to do with the transfer rate of information from memory into the place where the computations are done. The operation—that is, a SAXPY—needs to reference three vectors and do essentially two operations on each of the elements in the vector. And the transfer rate—the maximum rate at which we are going to transfer information to or from the memory device—is the limiting factor here.
Thus, as we increase the computational power without a corresponding increase in memory, memory access can cause serious bottlenecks. The bottom line is MFLOPS are easy, but bandwidth is difficult .
Transfer Rate
Table 2 lists the peak MFLOPS rate for various machines, as well as the peak transfer rate (in megawords per second).
Recall that the operation we were doing requires three references and returns two operations. Hence, to run at good rates, we need a ratio of three to two. The CRAY Y-MP does not do badly in this respect. Each
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
processor can transfer 50 million (64-bit) words per second; and the complete system, from memory into the registers, runs at four gigawords per second. But for many of the machines in the table, there is an imbalance between those two. One of the particularly bad cases is the Alliant FX/80, which has a peak rate of 188 MFLOPS but can transfer only 22 megawords from memory. It is going to be very hard to get peak performance there.
Memory Latency
Another issue affecting performance is, of course, the latency: how long (in terms of cycles) does it actually take to transfer the information after we make a request? In Table 3, we list the memory latency for seven machines. We can see that the time ranges from 14 to 50 cycles. Obviously, a memory latency of 50 cycles is going to impact the algorithm's performance.