The Connection Machine CM-2:
Overlapping Communication with Computation
The Connection Machine CM-2 affords another good example of how a powerful compiler can provide a highly effective user interface and free the user from most communication issues. The Connection Machine is a distributed-memory (hypercube) SIMD computer, which in principle might have been programmed using standard message-passing procedures. For a more detailed description of the CM-2, see McBryan (1990).
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||
In fact, the assembly language of the system supports such point-to-point communication and broadcasting. However, Connection Machine high-level software environments provide basically a virtual shared-memory view of the system. Each of the three high-level supported languages, CM Fortran, C*, and *Lisp, makes the system look to the user as if he is using an extremely powerful uniprocessor with an enormous extended memory. These languages support parallel extensions of the usual arithmetic operations found in the base language, which allows SIMD parallelism to be specified in a very natural and simple fashion. Indeed, CM-2 programs in Fortran or C* are typically substantially shorter than their serial equivalents from workstations or Cray Research, Inc., machines because DO loops are replaced by parallel expressions.
However, in this discussion I would like to emphasize that very significant communication optimization is handled by the software. This is best illustrated by showing the nature of the optimizations involved in code generation for the same generic relaxation-type operation discussed in the previous section. We will see that without communication optimization the algorithm runs at around 800 MFLOPS, which increases to 3.8 GFLOPS when compiler optimizations are used to overlap computation and communication.
For the simple case of a Poisson-type equation, the fundamental operation v = Au takes the form (with r and s scalars)
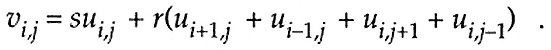
The corresponding CM-2 parallel Fortran takes the form
v = s*u + r*(cshift(u,1,1) + cshift(u,1,-1) + cshift(u,2,1)
+ cshift(u,2,-1)) .
Here, cshift (u,d,l) is a standard Fortran 90 array operator that returns the values of a multidimensional array u at points a distance l away in dimension direction d .
The equivalent *Lisp version of a function applya for v = Au is
(defun *applya (u v)
(*set v (-!! (*!! (!! s) u)
(*!! (!! r) (+!! (news!! u -1 0)
(news!! u 1 0)
(news!! u 0 -1) (news!! u 0 1)
)))))
*Lisp uses !! to denote parallel objects or operations, and as a special case, !! s is a parallel replication of a scalar s . Here (news!! u dx dy ) returns in each processor the value of parallel variable u at the processor dx processors away horizontally and dy away vertically. Thus, cshift (i + 1,j ) in Fortran would be replaced by (news!! u 1 1) in *Lisp.
The *Lisp source shown was essentially the code used on the CM-1 and CM-2 implementation described in McBryan (1988). When first implemented on the CM-2, it yielded a solution rate of only 0.5 GFLOPS. Many different optimization steps were required to raise this performance to 3.8 GFLOPS over a one-year period. Probably the most important series of optimizations turned out to be those involving the overlap of communication with computation. Working with compiler and microcode developers at Thinking Machines Corporation, we determined the importance of such operations, added them to the microcode, and finally improved the compiler to the point where it automatically generated such microcode calls when presented with the source above.
We will illustrate the nature of the optimizations by discussing the assembly language code generated by the optimized compiler for the above code fragment. The language is called PARIS, for PARallel Instruction Set. The PARIS code generated by the optimizing *Lisp compiler under version 4.3 of the CM-2 system is shown in the code displayed below. Here, the code has expanded to generate various low-level instructions, with fairly recognizable functionality, including several that overlap computation and communication, such as
cmi:get-from-east-with-f-add-always ,
which combines a communication (getting data from the east) with a floating-point operation (addition). Here is the optimized PARIS code for relaxation:
(defun *applya (u v)
(let* ((slc::stack-index *stack-index*)
(-!!-index-2 (+ slc::stack-index 32))
(pvar-location-u-11 (pvar-location u))
(pvar-location-v-12 (pvar-location v))) ,
(cm:get-from-west-always -!!-index-2
pvar-location-u-11 32)
(cm:get-from-east-always *!!-constant-index4
pvar-location-u-11 32)
(cmi::f+always-!!-index-2 *!!-constant-index4 23 8)
(cmi::get-from-east-with-f-add-always -!!-index-2
pvar-location-u-11 23 8)
(cmi::f-multiply-constant-3-always pvar-location-v-12
pvar-location-u-11 s 23 8)
(cmi::f-subtract-multiply-constant-3-always
pvar-location-v-12 pvar-location-v-12
-!!-index-2 r 23 8)
(cmi:get-from-north-always -!!-index-2
pvar-location-u-11 32)
(cmi::f-always slc::stack-index -!!-index-2 23 8)
(cmi::get-from-north-with-f-subtract-always
pvar-location-v-12 pvar-location-u-11 23 8)
(cm:get-from-south-always -!!-index-2
pvar-location-u-11 32)
(cmi::float-subtract pvar-location-v-12 slc::
stack-index -!!-index-2 23 8)
(cmi::get-from-south-with-f-subtract-always
pvar-location-v-12 -!!-index-2 23 8)
)
)
Obviously, the generated assembly code is horrendously complex. If the user had to write this code, the Connection Machine would not be selling today—even if the performance were higher than 3.8 GFLOPS! The key to the success of Thinking Machines in the last two years has been to produce a compiler that generates such code automatically, and this is where the user interface is most enhanced by the compiler. The development of an optimizing compiler of this quality, addressing communication instructions, as well as computational instructions, is a major achievement of the CM-2 software system. Because of its power, the compiler is essentially the complete user interface to the machine.