Parallel Architecture and the User Interface
Gary Montry
Gary R. Montry is a freelance consultant for Southwest Software in Albuquerque, New Mexico. Until 1990, he was a Consulting Systems Engineer at Myrias Computer Corporation in Albuquerque. Gary has worked in the area of computer simulations for over 20 years. Since 1985, he has concentrated on simulation codes for massively parallel computers. In 1988, he was a recipient of the first Gordon Bell Award for achievements in parallel processing. He also received the Karp Challenge Award for his work as part of the first team ever to demonstrate parallel speedup of 200 on a parallel MIMD computer. In 1989, he received an R&D 100 Award for Contributions in Parallel Computing Software for Scientific Problems. He was the first person to successfully run a computer program using over 1000 MIMD processors. He also has the unique experience of having run parallel codes on both distributed-memory and shared-memory computers with more than 1000 processing elements.
I want to focus on parallel architectures and the user interface. My background is in parallel processing, and I have been working for vendors specializing in parallel software and shared-memory computers since 1989.
Figure 1 is a tree showing what I consider to be a parallel-architecture hierarchy. If you look at it very closely, you will see that none of the branches have any relationship to the other branches. The reason I drew it this way is because it helps me to enforce the points of view that I want to discuss.
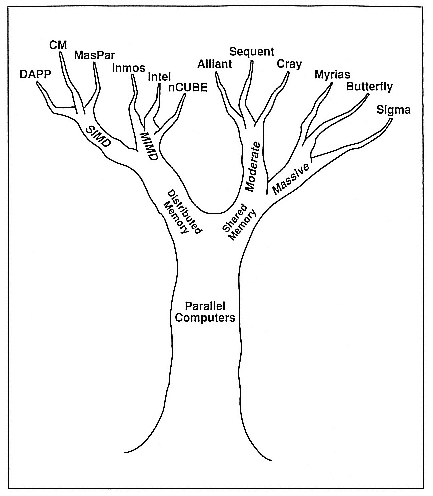
Figure 1.
Four major divisions of parallel architectures.
On the left side of the tree, I have the distributed-memory architectures—the SIMD branch and the MIMD branch. On the right-hand side of the tree, I have the shared-memory machines grouped into two branches, which I call the moderately parallel and the massively parallel branches. Massively parallel would be 200 or more processors, but the number is kind of nebulous. The reason I did the tree this way is because the interface difficulties in providing usability for the user of parallel machines are directly dependent on which side of the tree you happen to be.
On the left side of the tree, the MIMD machines provide us with Fortran and C and a couple of message-passing primitives. The same holds true for SIMD. Thus, the interface is pretty much fixed. We are given the language, a few instructions, and a few directives that allow us to pass messages. From there it is possible to build more complex interfaces that make it easier for the user to interact with the machine. A good example of that, I think, is the way Thinking Machines Corporation has brought out a new Fortran language to support their SIMD architecture, which helps to do automatic layout of the variables across the memory.
If you are on the right-hand side of the tree, it is a lot more difficult because you have a lot more options. On the massively parallel side, I have identified three particular architectures or companies that are working on massively parallel, shared-memory machines. One company, Myrias Computer Corporation, has tried to build and market a machine that has distributed memory physically but supports shared memory globally, with a global address base across disparate processors that are connected in some kind of hierarchical fashion. (The figure reflects developments through mid-1990; a Kendall Square Research machine based on similar architecture had already been produced at that time, but the work had not yet been made public.)
Butterfly architecture—represented by the TC2000 from Bolt Beranek & Newman (BBN), the RP3 from IBM, and the Ultra Project at New York University—uses shuffle-exchange networks in order to support shared memory. One difference between these three machines and the Myrias is that while for the former there is only one copy of the operating system in the memory, for the Myrias there is a copy of the operating system on every processor.
I have included the Sigma machine, which is actually the first machine of a family of data-flow machines being built at Electro-Technical Laboratories in Japan. It has already been superseded by their new M machine. Their goal is to have a 1000-processor machine by 1994. Although they are currently lacking floating-point hardware and a little software, that does not mean they won't succeed—their gains have been very impressive.
The typical view of looking at the software and hardware together is a layered approach, where you have the high-level language at the top of the stack, followed by the compilers, the debuggers, and the linkers, some kind of a supervisor that is used to do I/O or to communicate with the user, and the kernel, which interacts with the hardware at the bottom level. This structure is considered to be layered because it has been
viewed historically as the way to develop software for workstations and single-processor machines. For those single-processor machines, software development can usually take place separately in each level, which contributes to the notion of independent layers of software.
On top of that, everybody wants another level of abstraction, some kind of user interface or metalanguage—maybe a graphic user interface (GUI)—to help them interact with the actual language that interacts with the machine (Figure 2). My assertion is that for parallel processors, it is too soon to have to worry about this. There are several problems in the lower layers that we have to address for massively parallel machines before we can even think about the user interface.
If we correctly design the actual interface at the language level for shared-memory parallel processors, then we will be able to leverage off work that is done for GUIs with metalanguages and user interfaces from serial-like machines in the future. So really, the programming language is the user interface. It is what you have now, and what you are going to have for the next five, six, or seven years, and it is not really going to change much. The difficulty with parallel processors is that the user interface reflects hardware and architecture dependency through the use of language extensions and/or compiler directives.
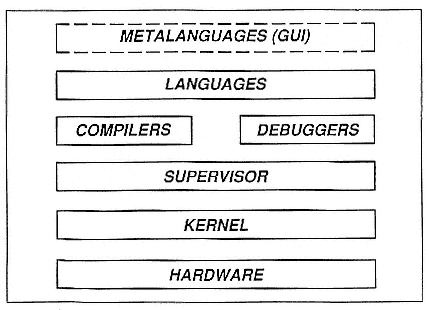
Figure 2.
A layered approach to developing software for workstations and
single-processor machines, with metalanguages as another level on top to
help the user interact with the languages that in turn interact with the machine.
For distributed-memory machines we have message-passing subprogram calls. For a shared-memory machine we can have message-passing or locks and semaphores. For parallel processors like those from Alliant Computer Systems and the Cedar Project, in which you have lots of compiler assist, there are compiler directives, or pragmas, to indicate to the compiler and to the computer exactly what we are trying to do and how to decompose the problem ideally.
For shared-memory machines, the design of the human-machine interface at the language level is intimately tied to the particular underlying hardware and software. That means that you cannot think of the whole stack of software and hardware in the classical sense, as you would for a workstation or a serial processor. You have to think of it as a seamless environment in which the software and the hardware all have to work together at all different levels in order to cooperate and provide the parallelism.
From a functional point of view, what you really want is for all the software and hardware infrastructure to sit below a level at which the user has to view it. At the top, you only want the high-level interface of the languages to show, like the tip of an iceberg (Figure 3). To do that, you have to develop an interface that is very complex underneath but looks very simple to the user. The complexity that the user sees is inversely proportional to the amount of work that went into the interface to support it.
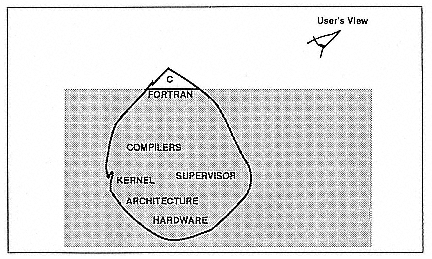
Figure 3.
Functionality of the software and hardware of a simple interface based on a
complex system.
The corollary to this concept is that complex interfaces are cheap, and simple interfaces are expensive, which is the reason you have complex interfaces on distributed-memory machines, or on the first generations thereof, because they were simple to implement and they were not very costly. An iceberg model of this interface would result in an apparent violation of the laws of physics in which the iceberg would float 90 per cent above the water and 10 per cent below the water (Figure 4).
There is another reason for wanting to have a serial look and feel to a shared-memory machine: you would like to get the feeling that when a program is run, you get the right result. You would like to have the feeling that you have an interface that is actually reproducible and trustworthy.
I can tell you some stories about the early days on the ELXSI—about a code of mine that ran for six months. Bob Benner (a Session 7 panelist) and I put it together. It was a finite-element code, and we used it to test the machine's integrity. We ran it for six months, and it always gave the same answers. I went in one day and I ran it, and it didn't give the same answer anymore. It gave different answers. So I went out and had a drink and came back later and ran it, and there was no one on the machine, and it gave the right answers. I studied the problem for a week, and I finally called up the ELXSI company and said, "You have a problem with your machine." They said, "Oh, no, you're a user; you have a problem with your code." We went around and around, and a week later I finally
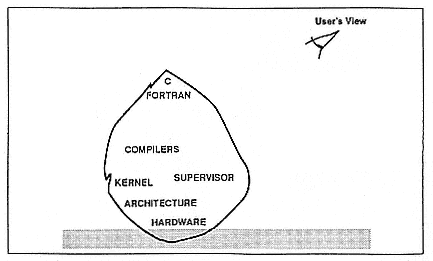
Figure 4.
Functionality of the software and hardware of a complex interface based on a
simple system.
convinced them to look at the microcode. It turned out that they had changed the microcode in their caching scheme and had failed to fully flush all caches during context switch.
So there are problems with shared-memory parallel processors in the sense of really trying to give people the feeling that both the vendor and the user have something solid. We really do want to have the look and feel of serial interfaces. To accomplish these goals, there are several requirements:
• language and compiler extensions that have the look and feel people are used to when working with computer codes;
• automatic generation of independent tasks for concurrent execution, whereby the generation is initiated by the compiler at compile time and then instantiated by the operating system during the run;
• dynamic scheduling and load balancing of independent tasks;
• automatic distribution and collection of data from concurrently executed tasks; and
• the ability to relieve the user of the burden of data locality, which is the toughest constraint of all (the easiest way to meet this last requirement is to build a common-memory machine, although such a machine is very expensive).
The machine discussed by Burton Smith in Session 4 is really a common-memory machine. It is a single-level machine, and it is very expensive. The hope is that we can build machines with memory that is distributed with the processors and still relieve the user of the burden of data locality. We can explicitly relieve the user of the burden if we have an interconnect that is fast enough, but no one can afford to build it. Actually, it is not even technologically possible to do that right now. The alternative way of eliminating the data-locality problem is with latency hiding, and asynchronous machines can do quite a bit of that.
When you look at all of these requirements and you say you want to have a number of independent tasks that you would like to be able to schedule across some kind of interconnect, you have to decide as a computer designer and builder what kind of tasks you are going to have. Are you going to have lightweight threads with very little context that could move very easily, although you might have to generate many of them? If you do, that puts particular constraints on the interconnect system that you have. Or are you going to have fewer heavyweight processes, which are larger-grained, which don't have to move quite as often, but which also don't put quite the strain on the interconnect? The interconnect is very costly in shared-memory machines, so you need to make the decision about what you want to do at the top level, which will affect your compiler and perhaps the constructs that you show to the
user, which in turn will affect the hardware at the bottom of the software/hardware hierarchy.
Now that I have outlined the technical requirements to build the machine, I will discuss the programmatic requirements.
There are five requirements I have identified that are important and that every project has to meet to build a massively parallel, shared-memory machine:
• You have to have a lot of good parallel software expertise to write the operating system and the kernel and the compilers, and they all have to work together.
• You have to have parallel hardware expertise. For that, you have to have hardware resources and people who understand how parallel machines work and what the costs and tradeoffs are for doing certain things in certain ways.
• You have to have teamwork. This may sound corny, but this is one of the most important points. There has got to be teamwork that is driven by end-users, people who are actually going to use the machine at the end so you have something that is usable. A good example of a lack of teamwork here would be the Floating Point Systems T-Series machine, for which there was plenty of hardware built, but the software was left out.
• You have to have commitment. These are long projects that last many years. If you don't think commitment is important, ask the people at Evans & Sutherland about commitment, for example.
• Finally, you need on the order of $50 to $100 million to solve the problems.
Many companies and various entities in the U.S. meet some of those five requirements, but they don't meet them all. Unless the situation changes substantially in the next few years, you probably won't see a massively parallel, shared-machine from a new entity in the U.S. It will either have to come from BBN or Myrias or the companies that are already in business.
In summary, we need to develop a somewhat standardized language implementation at the top level for shared-memory parallel processors so that we can start designing hardware and building the machines to execute that code. These hardware experiments are expensive, and in the current political and economic climate, it is not too likely that private industry is going to take on this particular challenge.