5—
SYSTEMS SOFTWARE
This session focused on developments and limitations of systems software for supercomputers and parallel processing systems. The panelists discussed operating systems, compilers, debuggers, and utilities, as well as load balancing, multitasking, automatic parallelization, and models of computation.
Session Chair
Paul Schneck, Supercomputing Research Center
Parallel Software
Fran Allen
Frances E. Allen is an IBM Fellow and Senior Manager of Parallel Software at the IBM Thomas J. Watson Research Center in Yorktown Heights, New York. She joined IBM Research in 1957 and has since specialized in compilers, compiler optimization, programming languages, and parallelism. She has been an Institute of Electrical and Electronics Engineers (IEEE) Distinguished Visitor, an Association for Computing Machines (ACM) National Lecturer, a member of the NSF Computer Science Advisory Board, a Visiting Professor at New York University, and a Consulting Professor at Stanford University. Dr. Allen has also served as General, Program, and Tutorial Chair of the ACM SIGPLAN Compiler Construction Conference.
In 1987, Dr. Allen was elected to the National Academy of Engineering, and she was appointed the Chancellor's Distinguished Lecturer and the Mackay Lecturer for 1988–89 at the University of California, Berkeley. In 1990, she became an IEEE Fellow and in 1991 was awarded an Honorary Doctor of Science degree from the University of Alberta.
Parallel hardware is built and bought for performance. While cost/performance is a significant, sometimes overriding factor, performance is the primary motivation for developing and acquiring supercomputers and massively parallel machines. Advances in hardware such as the astounding increase in CPU speeds, increases in communication bandwidth, and
reduction in communication latencies are changing both the raw performance of available hardware systems and their structure. An even more profound change is in the diversity of computational models provided by the hardware. These range from the multiple-CPU, shared-memory systems typified by Cray Research, Inc., to the single instruction, multiple data (SIMD) Connection Machine from Thinking Machines Corporation, to a variety of multiple instruction, multiple data (MIMD), distributed-memory machines. However, these technological advances have not resulted in widespread use of parallelism, nor has the promised performance been easily and frequently realized. Parallel software is the key to realizing the potentials of parallelism: performance and pervasive use. The purpose of this discussion is to assess briefly the state of parallel software for numeric-intensive computing on parallel systems and to indicate promising directions.
Fortran, the lingua franca for scientific and engineering programming, was designed for shared-memory uniprocessors. Traditional optimizing Fortran compilers generate high-performance code, sometimes perfect code, for such a machine. Traditionally, however, the user is responsible for managing storage so that memory and caches are used effectively. With the advent of vector hardware on the uniprocessors, Fortran compilers needed to compose vector instructions out of the multiple statements used to iterate through the elements of arrays. Dependence analysis to determine the relative order of references to the same storage location and loop transformations to reorder the references have been developed. When applied to Fortran codes, these transformations are now powerful enough so that vectorization is usually left to the compiler, with little or no intervention by the user.
Parallelism in any form involving more than one processor presents a very different challenge to the user and to the parallel software. There are two fundamental problems: forming parallel work and reducing overheads. Solutions to these problems involve the user and all aspects of the parallel software: the compiler, the run-time environment, the operating system, and the user environment. However, the user is often unwilling to rework the code unless there is a significant performance gain; currently, at least a factor of 10 speedup is expected for rework to be worth the effort. Even when the user does rework the algorithm and the code, what target machine model should be targeted? Given the plethora of supercomputers and massively parallel machines and, more importantly, the variety of computational models supported, users are reluctant to choose one. Thus, the challenge of parallel software is both performance and portability.
Two recent developments are very promising for numeric-intensive computing: Fortran 90 and a user-level single computational model. Fortran 90 array language allows the user to succinctly express computations involving arrays. An operand in a statement can be an entire array or a subsection of an array, and because all operands in a statement must be conformable, all the implicit, element-level operations such as add or multiply can be executed in parallel. While the designers of Fortran 90 primarily had vectors in mind, the array language is very appropriate as a computational model potentially applicable to several hardware computational models.
Fortran 90 array statements can also be compiled easily to shared-memory machines, though to do this, compilers must eliminate the transformational functions used to provide conformable operands, replacing them with appropriate index reference patterns to the operand elements. Fortran 90 array statements can be compiled very effectively to SIMD architectures. The distributed-memory MIMD architectures pose a bigger problem.
Computation can only be performed on data accessible to the computation. Data must be in registers, in cache, or in addressable memory. The delay or latency in accessing the data is critical to the performance of the machine because delays due to data accesses only reduce the effective speed of the computational units. As stated earlier, one of the two challenges for achieving parallel performance is the reduction of overheads. Delays in data movement in the system are often the most significant contributors to overhead. For shared-memory machines, this is alleviated by effective use of registers and caches, with appropriately placed synchronization and refreshing of shared memory so that shared values are correct. For distributed-memory MIMD machines, the cost of assuring that correct data is available to the computation can be very significant, hundreds or thousands of cycles in many cases, with explicit sends and receives being required at the hardware level to move information from one machine to another. It becomes important, therefore, to preplan the placement and movement of information through the system. An effort is currently under way to augment the Fortran 90 language with user directives indicating how data can be partitioned.
Another factor contributing to overhead is synchronization. While the SIMD architectures do not incur explicit synchronization overhead because the machine is synchronized at every instruction, all other forms of parallel hardware assume software-controlled synchronization to coordinate work and data availability. Programs running on massively
parallel MIMD machines often have a data-driven, intermachine model. As soon as data is computed, it is sent to the appropriate machine(s), which can then start computing with it. This model of computation, a direct extension of the basic hardware-level, send-and-receive model, generally requires a total recasting of the solution and rewrite of the code.
An emerging computational model that has great promise is SPMD: single program, multiple data. A program written in Fortran 90, augmented with data-partitioning directives, can be executed concurrently on multiple processors but on different data partitions. It has some of the characteristics of SIMD but is much more flexible in that different control paths can be taken on different parallel executions of the same code. But the most important aspect of SPMD is that it may not require extensive problem rework, yet the programs may be portable across very diverse parallel systems. It should be emphasized that parallel software systems do not currently support the approach, so the hoped-for performance and portability goals may not be achievable.
Advances in parallel software toward the goals of performance, portability, and ease of use requires enlarging the scope of software in two directions. Whole programs or applications should be analyzed, transformed, and managed by the system, and the whole parallel software system should participate as an integrated unit.
The traditional functional boundaries among operating systems, runtime, compilers, and user environments must be revised. For example, scheduling of work to processors can be done by the compiler and the run-time system and even by the user, not just the operating system. Fast protocols avoiding operating system calls are needed to reduce overheads. The user and compiler need information about the performance of the running program so that adjustments can be made in the source code or the compilation strategy. Debugging of parallel code is a major problem, and integrated tools to facilitate that solution are needed. For the foreseeable future, the user must be an active participant in enabling the parallelism of the application and should be able to participate interactively with the entire system.
Whole-program analysis and transformation is essential when compiling programs to target machines such as distributed-memory MIMD systems because of the relatively large granularity of parallel work and the need to partition data effectively. This analysis is both broad and deep, involving interprocedural analysis and analyses for data and control dependence and for aliases. The transformations involve transforming loops, regions, and multiple procedures to create appropriate
parallelism for the target machine. They also involve modifying the size, shape, location, and lifetimes of variables to enable parallelism.
It is widely recognized that the major challenge in parallelism is in developing the parallel software. While there are products and active research on whole-program analysis and transformation, there is less effort on whole-system integration, including an integrated user environment. A totally unanswered question is how effective these parallel software directions will be on massively parallel MIMD machines. What does seem certain is that without advances in parallel software and in problem-solving languages, the true potential of parallel systems will not be realized.
Supercomputer Systems-Software Challenges
David L. Black
David L. Black is a Research Fellow at the Cambridge office of the Open Software Foundation (OSF) Research Institute, where he participates in research on the evolution of operating systems. Before joining OSF in 1990, he worked on the Mach operating system at Carnegie Mellon University (CMU), from which he received a Ph.D. in computer science. Dr. Black also holds an M.S. in computer science from CMU and an M.A. in mathematics from the University of Pennsylvania. His current research is on microkernel-based operating system environments, incorporating his interests in parallel, distributed, and real-time computation.
Abstract
This paper describes important systems-software challenges to the effective use of supercomputers and outlines the efforts needed to resolve them. These challenges include distributed computing, the availability and influence of high-speed networks, interactions between the hardware architecture and the operating system, and support for parallel programming. Technology that addresses these challenges is crucial to ensure the continued utility of supercomputers in the heterogeneous, functionally specialized, distributed computing environments of the 1990s.
Introduction
Supercomputers face important systems-software challenges that must be addressed to ensure their continued productive use. To explore these issues and possible solutions, Lawrence Livermore National Laboratory and the Supercomputing Research Center sponsored a workshop on Supercomputer Operating Systems and related issues in July 1990. This paper is based on the results of the workshop[*] and covers four major challenges: distributed computing, high-speed networks, architectural interactions with operating systems (including virtual memory support), and parallel programming.
Distributed Computing
Distributed computing is an important challenge because supercomputers are no longer isolated systems. The typical supercomputer installation contains dozens of systems, including front ends, fileservers, workstations, and other supercomputers. Distributed computing encompasses all of the problems encountered in convincing these systems to work together in a cooperative fashion. This is a long-standing research area in computer science but is of increasing importance because of greater functional specialization in supercomputing environments.
Functional specialization is a key driving force in the evolution of supercomputing environments. The defining characteristic of such environments is that the specialization of hardware is reflected in the structure of applications. Ideally, applications are divided into components that execute on the most appropriate hardware. This reserves the supercomputer for the components of the application that truly need its high performance and allows other components to execute elsewhere (e.g., a researcher's workstation, a graphics display unit, etc.). Cooperation and coordination among these components is of paramount importance to the successful use of such environments. A related challenge is that of partitioning problems into appropriate components. Communication costs are an important consideration in this regard, as higher costs require a coarser degree of interaction among the components.
Transparency and interoperability are key system characteristics that are required in such environments. Transparent communication mechanisms work in the same fashion, independent of the location of the communicating
[*] The views and conclusions in this document are those of the author and should not be interpreted as representing the workshop as a whole, its sponsors, other participants, or the official policies, expressed or implied, of the Open Software Foundation.
components, including whether the communication is local to a single machine. Interoperability ensures that communication mechanisms function correctly among different types of hardware from different manufacturers, which is exactly the situation in current supercomputing environments. Achieving these goals is not easy but is a basic requirement for systems software that supports functionally specialized supercomputing environments.
High-Speed Networks
High-speed networks (gigabit-per-second and higher bandwidth) cause fundamental changes in software at both the application and systems levels. The good news is that these networks can absorb data at supercomputer rates, but this moves the problem of coping with the high data rate to the recipient. To illustrate the scope of this challenge, consider a Cray Research, Inc., machine with a four-nanosecond cycle time. At one gigabit per second, this Cray can handle the network in software because it can execute 16 instructions per 64-bit word transmitted or received. This example illustrates two problem areas. The first is that a Cray is a rather expensive network controller; productive use of networks requires that more cost-effective interface hardware be employed. The second problem is that one gigabit per second is slow for high-speed networks; at least another order of magnitude in bandwidth will become available in the near future, leaving the Cray with less than two instructions per word.
Existing local area networking practice does not extend to high-speed networks because local area networks (LANs) are fundamentally different from their high-speed counterparts. At the hardware level, high-speed networks are based on point-to-point links with active switching hardware rather than the common media access often used in LANs (e.g., Ethernet). This is motivated both by the needs of the telecommunications industry (which is at the forefront of development of these networks) and the fact that LAN media access techniques do not scale to the gigabit-per-second range. On a 10-megabit-per-second Ethernet, a bit is approximately 30 meters long (about 100 feet); since this is the same order of magnitude as the physical size of a typical LAN, there can only be a few bits in flight at any time. Thus, if the entire network is idled by a low-level media-management event (e.g., collision detection), only a few bits are lost. At a gigabit per second, a bit is 30 centimeters long (about one foot), so the number of bits lost to a corresponding media-management event on the same-size network is a few hundred; this can be a significant
source of lost bandwidth and is avoided in high-speed network protocols. Using point-to-point links can reduce these management events to the individual link level (where they are less costly) at the cost of active switching and routing hardware.
The bandwidth of high-speed networks also raises issues in the areas of protocols and hardware interface design. The computational overhead of existing protocols is much more costly in high-speed networks because the bandwidth losses for a given amount of computation are orders of magnitude larger. In addition, the reduced likelihood of dropped packets may obviate protocol logic that recovers from such events. Bandwidth-related issues also occur in the design of hardware interfaces. The bandwidth from the network has to go somewhere; local buffering in the interface is a minimum requirement. In addition, the high bandwidth available from these networks has motivated a number of researchers to consider memory-mapped interface architectures in place of the traditional communication orientation. At the speeds of these networks, the overhead of transmitting a page of memory is relatively small, making this approach feasible.
The importance of network management is increased by high-speed networks because they complement rather than replace existing, slower networks. Ethernet is still very useful, and the availability of more expensive, higher-bandwidth networks will not make it obsolete. Supercomputing facilities are likely to have overlapping Ethernet, fiber-distributed data interface, and high-speed networks connected to many machines. Techniques for managing such heterogeneous collections of networks and subdividing traffic appropriately (e.g., controlling traffic via Ethernet, transferring data via something faster) are extremely important. Managing a single network is challenging enough with existing technology; new technology is needed for multinetwork environments.
Virtual Memory
Virtual memory originated as a technique to extend the apparent size of physical memory. By moving pages of memory to and from backing storage (disk or drum) and adjusting virtual to physical memory mappings, a system could allow applications to make use of more memory than existed in the hardware. As applications executed, page-in and page-out traffic would change the portion of virtual memory that was actually resident in physical memory. The ability to change the mapping of virtual to physical addresses insulated applications from the effects of
not having all of their data in memory all the time and allowed their data to occupy different physical pages as needed.
Current operating systems emphasize the use of virtual memory for flexible mapping and sharing of data. Among the facilities that depend on this are mapped files, shared memory, and shared libraries. These features provide enhanced functionality and increased performance to applications. Paging is also provided by these operating systems, but it is less important than the advanced mapping and sharing features supported by virtual memory. Among the operating systems that provide such features are Mach, OSF/1,[*] System V Release 4,[**] and SunOS.[***] These features are an important part of the systems environment into which supercomputers must fit, now and in the future. The use of standard operating systems is important for interoperability and commonality of application development with other hardware (both supercomputers and other systems).
This shift in the use of virtual memory changes the design tradeoffs surrounding its use in supercomputers. For the original paging-oriented use, it was hard to justify incorporating virtual memory mapping hardware. This was because the cycle time of a supercomputer was so short compared with disk access time that paging made little sense. This is still largely the case, as advances in processor speed have not been matched by corresponding advances in disk bandwidth. The need for virtual memory to support common operating systems features changes this tradeoff. Systems without hardware support for virtual memory are unable to support operating systems features that depend on virtual memory. In turn, loss of these features removes support for applications that depend on them and deprives both applications and the system as a whole of the performance improvements gained from these features. This makes it more difficult for such systems to operate smoothly with other systems in the distributed supercomputing environment of the future. The next generation of operating systems assumes the existence of virtual memory; as a result, hardware that does not support it will be at a disadvantage.
[*] OSF/1 is a trademark of the Open Software Foundation.
[**] System V is a trademark of UNIX Systems Laboratories, Inc.
[***] SunOS is a trademark of Sun Microsystems, Inc.
Resource Management
The increasing size and scale of supercomputer systems pose new resource-management problems. Enormous memories (in the gigabyte range) require management techniques beyond the LRU-like paging that is used to manage megabyte-scale memories. New scheduling techniques are required to handle large numbers of processors, nonuniform memory access architectures, and processor heterogeneity (different instruction sets). A common requirement for these and related areas is the need for more sophisticated resource management, including the ability to explicitly manage resources (e.g., dedicate processors and memory to specific applications). This allows the sophistication to be moved outside the operating system to an environment- or application-specific resource manager. Such a manager can implement appropriate policies to ensure effective resource usage for particular applications or specialized environments.
Parallel Processing
Supercomputer applications are characterized by the need for the fastest possible execution; the use of multiple processors in parallel is an important technique for achieving this performance. Parallel processing requires support from multiple system components, including architecture, operating systems, and programming language. At the architectural level, the cost of operations used to communicate among or synchronize processors (e.g., shared-memory access, message passing) places lower bounds on the granularity of parallelism (the amount of computation between successive interactions) that can be supported. The operating system must provide fast access to these features (i.e., low-overhead communication mechanisms and shared-memory support), and provide explicit resource allocation, as indicated in the previous section. Applications will only use parallelism if they can reliably obtain performance improvements from it; this requires that multiple processors be readily available to such applications. Much work has been done in the areas of languages, libraries, and tools, but more remains to be done; the goal should be to make parallel programming as easy as sequential programming. A common need across all levels of the system is effective support for performance analysis and debugging. This reflects the need for speed in all supercomputer applications, especially in those that have been structured to take advantage of parallelism.
Progress
Progress has been made and continues to be made in addressing these challenges. The importance of interconnecting heterogeneous hardware and software systems in a distributed environment has been recognized, and technology to address this area is becoming available (e.g., in the forthcoming Distributed Computing Environment offering from the Open Software Foundation). A number of research projects have built and are gaining experience with high-speed networks, including experience in the design and use of efficient protocols (e.g., ATM). Operating systems such as Mach and OSF/1 contain support for explicit resource management and parallel programming. These systems have been ported to a variety of computer architectures ranging from PCs to supercomputers, providing an important base for the use of common software.
Future Supercomputing Elements
Bob Ewald
Robert H. Ewald is Executive Vice President for Development at Cray Research, Inc., in Chippewa Falls, Wisconsin, having joined the company in 1984. From 1977 to 1984, he worked at Los Alamos National Laboratory, serving during the last five years of his tenure as Division Leader in the Computing and Communications Division.
This discussion will focus on the high-performance computing environment of the future and will describe the software challenges we see at Cray Research, Inc., as we prepare our products for these future environments.
Figure 1 depicts the environment that Cray Research envisions for the future and is actively addressing in our strategic and product plans. This environment consists of machines that have traditional, or general-purpose, features, as well as special architectural features that provide accelerated performance for specific applications. It's currently unclear how these elements must be connected to achieve optimum performance—whether by some processor, memory, or network interconnect. What is clear, however, is that the successful supercomputer architecture of the future will be an optimal blend of each of these computing elements. Hiding the architectural implementation and delivering peak performance, given such a heterogeneous architecture, will certainly be a challenge for software. We currently have a number of architectural study teams looking at the best way to accomplish this.
Another key consideration in software development is what the future workstation architecture will look like. The view that we have today is something like that depicted in Figure 2. These will be very fast scalar machines with multiple superscalar and specialized processors combined to deliver enhanced real-time, three-dimensional graphics. Not only will tomorrow's software be required to optimize application performance on a heterogeneous-element supercomputer, as described earlier, but it will also be required to provide distributed functionality and integration with these workstations of tomorrow.
Figure 1.
Future supercomputer elements.
Figure 2.
Future workstation elements.
Figure 3 is Cray Research's view of what our customer networks look like or will look like. It is a heterogeneous network with systems and network components from a broad array of vendors. The four key elements of the network are workstations, networks of networks, compute servers (either general purpose or dedicated), and file servers. The networks are of varying speed, depending on the criticality and bandwidth of the resources that are attached. The key point of this scenario is that every resource is "available" to any other resource. Security restrictions may apply and the network may be segmented for specialized purposes, but basically the direction of networking technology is toward more open architectures and network-managed resources.
Figure 4 portrays the conceptual model that we are employing in our product development strategy. The idea of the client-server model is that the workstation is the primary user interface, and it transparently draws upon other resources in the network to provide specialized services. These resources are assigned to optimize the delivery of a particular service to the user. Cray Research's primary interest is in providing the highest performance compute and file servers. This hardware must be complemented with the software to make these systems accessible to the user in a transparent manner.
Currently, Cray Research provides a rich production environment that incorporates the client-server model. Our UNICOS software is based on AT&T UNIX System V with Berkeley Standard Distribution extensions and is designed for POSIX compliance. This enables application portability and a common cross-system application development environment. Through the use of X Windows and the network file system, CRAY-2s, X-MPs, and Y-MPs have connected to a variety of workstations from Sun Microsystems, Inc., Silicon Graphics IRIS, IBM, Digital Equipment Corporation, Apollo (Hewlett-Packard), and other vendors. Coupled with our high-speed interconnects, distributing an application across multiple Cray systems is now a practical possibility. In fact, during the summer of 1990, we achieved 3.3 × 109 floating-point operations per second (GFLOPS) on a matrix multiply that was distributed between a CRAY-2 and a Y-MP. Later that summer, a customer prospect was able to distribute a three-dimensional elastic FEM code between three Cray systems at the Cray Research Computing Center in Minnesota and achieved 1.7 GFLOPS sustained performance. Aside from the performance, what was incredible about this is that this scientist was running a real application, had only three hours of time to make the coding changes, and did this all without leaving his desk in Tokyo. The technology is here today to do this kind of work as a matter of course. I think
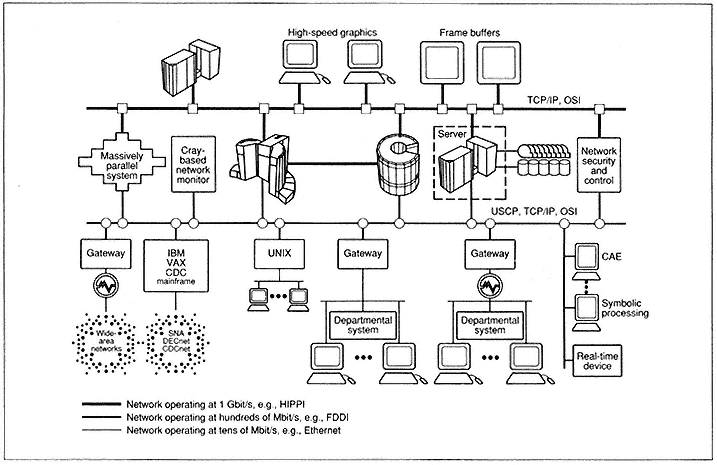
Figure 3.
Network supercomputing.
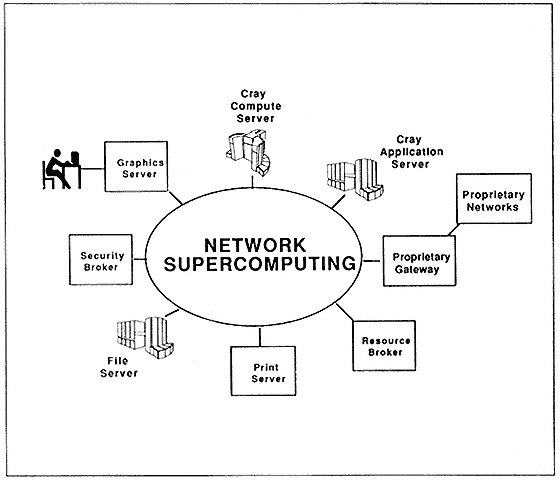
Figure 4.
Client-server model.
you'll see significant progress in the next year or two in demonstrating sustained high performance on real-world distributed applications.
These technologies present a number of software challenges to overcome. First, there is a growing need to improve automatic recognition capabilities. We must continue to make progress to improve our ability to recognize and optimize scalar, vector, and parallel constructs. Data-element recognition must utilize long vectors or massively parallel architectures as appropriate. Algorithm recognition must be able to examine software constructs and identify the optimal hardware element to achieve maximum performance. As an example, an automatic recognition of fast Fourier transforms might invoke a special processor optimized for that function, similar to our current arithmetic functional units.
Second, because this environment is highly distributed, we must develop tools that automatically partition codes between heterogeneous systems in the network. Of course, a heterogeneous environment also implies a mix of standard and proprietary software that must be taken
into account. Security concerns will be a big challenge, as well, and must extend from the supercomputer to the fileserver and out to the workstation.
Not only must we make it easy to distribute applications, but we must also optimize them to take advantage of the strengths of the various network elements. The size of the optimization problem is potentially immense because of different performance characteristics of the workstation, network, compute, and fileserver elements. The problem is exacerbated by discontinuities in such performance characteristics as a slow network gateway or by such functional discontinuities as an unavailable network element. Ultimately, we will have to develop expert systems to help distribute applications and run them.
Finally, to operate in the computing environment of the future, the most critical software components will be the compilers and the languages that we use. If we cannot express parallelism through the languages we use, we will have limited success in simulation because the very things we are trying to model are parallel in nature. What we have been doing for the last 30 years is serializing the parallel world because we lack the tools to represent it in parallel form. We need to develop a new, non-von Neumann way of thinking so that we do not go through this parallel-to-serial-back-to-parallel computational gyration. A language based on physics or some higher-level abstraction is needed.
In terms of existing languages, Fortran continues to be the most important language for supercomputer users, and we expect that to continue. Unfortunately, its current evolution may have some problems. Because of the directions of the various standards organizations, we may see three different Fortran standards emerge. The American National Standards Institute (ANSI), itself, will probably have two standards: the current Fortran 77 standard and the new Fortran 9X standard. The International Standardization Organization may become so frustrated at the ANSI developments that they will develop yet another forward-looking Fortran standard. So what was once a standard language will become an unstandard set of standards. Nevertheless, we still envision that Fortran will be the most heavily used language for science and engineering through the end of this decade.
The C language is gaining importance and credibility in the scientific and engineering community. The widespread adoption of UNIX is partly responsible for this. We are seeing many new application areas utilizing C, and we expect this to continue. We also can expect to see additions to C for parallel processing and numeric processing. In fact,
Cray Research is quite active with the ANSI numerical-extensions-to-C group that is looking at improving its numeric processing capabilities.
Ada is an important language for a segment of our customer base. It will continue to be required in high-performance computing, in part because of Department of Defense mandates placed on some software developed for the U.S. government.
Lisp and Prolog are considered important because of their association with expert systems and artificial intelligence. In order to achieve the distributed-network optimization that was previously discussed, expert systems might be employed on the workstation acting as a resource controller on behalf of the user. We need to determine how to integrate symbolic and numeric computing to achieve optimal network resource performance with minimal cost. A few years ago we thought that most expert systems would be written in Lisp. We are seeing a trend, however, that suggests that C might become the dominant implementation language for expert systems.
In summary, today's languages will continue to have an important role in scientific and engineering computing. There is also, however, a need for a higher-level abstraction that enables us to express the parallelism found in nature in a more "natural" way. Nevertheless, because of the huge investment in existing codes, we must develop more effective techniques to prolong the useful life of these applications on tomorrow's architectures.
On the systems side, we need operating systems that are scalable and interoperable. The implementation of the system may change "under the hood" and, indeed, must change to take advantage of the new hybrid architectures. What must not change, however, is the user's awareness of the network architecture. The user interface must be consistent, transparent, and graphically oriented, with the necessary tools to automatically optimize the application to take advantage of the network resources. This is the high-performance computing environment of the future.
Compiler Issues for TFLOPS Computing
Ken Kennedy
Ken Kennedy received a B.A. in mathematics from Rice University, Houston, in 1967, an M.S. in mathematics from New York University in 1969, and a Ph.D. in computer science from New York University in 1971. He has been a faculty member at Rice since 1971, achieving the rank of Professor of Mathematical Sciences in 1980. He served as Chairman of the Department of Computer Science from its founding in 1984 until 1989 and was appointed Noah Harding Professor in 1985. He is currently Director of the Computer and Information Technology Institute at Rice and heads the Center for Research on Parallel Computing, an NSF Science and Technology Center at Rice, Caltech, and Los Alamos National Laboratory.
From 1985 to 1987, Professor Kennedy chaired the Advisory Committee to the NSF Division of Computer Research and has been a member of the Board of the Computing Research Association since 1986. In 1990, he was elected to the National Academy of Engineering.
Professor Kennedy has published over 60 technical articles on programming support software for high-performance computer systems and has supervised the construction of two significant software systems for programming parallel machines: a vectorizer for Fortran and an integrated scientific software development environment.
Professor Kennedy's current research focuses on extending techniques developed for automatic vectorization to programming tools for parallel computer systems and high-performance microprocessors. Through the Center for Research on Parallel Computation, he is seeking to develop new strategies for supporting architecture-independent parallel programming, especially in science and engineering.
I would like to ponder the notion of TFLOPS computing, which is a sort of subgoal of our high-performance computing initiative. I opposed this subgoal when I was first on the subcommittee of the Federal Coordinating Committee on Science, Engineering, and Technology that wrote the report on high-performance computing, but now I've warmed up to it a lot, primarily because I've seen the kind of scientific advances that we can achieve if we're able to get to the level of a TFLOPS and the corresponding memory sizes.
I want to talk about what I see as the compiler issues if we build such a machine. There are many ways one might consider building such a machine. I'll pick the way Session 13 presenter Justin Rattner would build it, which is to take Intel's latest microprocessors. Although I don't know exactly what the peaks are going to be, I'm sure that we won't be able to achieve more than about half of peak out of those things. Intel's study indicates they're going to achieve all of these in the middle-to-late 1990s and that they're going to have all sorts of performance out of single-chip processors. I'm counting on about 250 in the middle-to-late 1990s. That means that we'll have to have at least 8000 processors. If we are able to get Intel to give them to us for $10,000 a processor, which is less than they're currently offering for their iPSC/860s, that will be an $80 million machine, which is reasonable in cost. This means that we have to think about how to use 4000 to 8000 processors to do science. So I'd like to reflect on how we're using parallelism today.
The good news is that we have machines, and we're doing science with them. Some people in the audience can talk about the real achievements in which science and engineering calculations have been done at very low cost relative to conventional supercomputers, with high degrees of parallelism. Unfortunately, the other side of the coin is that there's some bad news. The bad news is that we have a diverse set of architectures, and the programming systems for those machines are primitive in the sense that they reflect a great deal of the architecture of the machine in the programming system. Thus, the user is, in fact, programming a specific
architecture quite frequently rather than writing general parallel programs.
In addition, there are the ugly new kinds of bugs that we have to deal with and all sorts of performance anomalies that, when you have a thousand processors and you get a speedup of two, people wonder what's gone wrong. You have to have some mechanism to help people to deal with these things.
So all sorts of problems exist in the programming. I think that the really critical issue is that we have not achieved the state where commercial firms with those zillions of dollars of investment will leap into the massive-parallelism world; they're afraid of losing that investment, and they're afraid of a major reprogramming effort for a particular machine that will be lost the next time a new machine has a different architecture.
I think people in the commercial world are standing back and looking at parallelism with a bit of a skeptical eye. Some of the scientists aren't, but I think a lot of scientists are. That means if we want parallelism to be successful in the way that previous generations of supercomputers have been successful, we have to provide some form of machine-independent parallel programming, at least enough so that people feel comfortable in protecting their investments.
It is useful for us to look at the legacy of automatic vectorization, which I think really made it possible for vector supercomputers to be well programmed. I want to dispel what may be a misconception on the part of some people. Vectorization technology did not make it possible for people to take dusty decks and run them on their local supercomputer and expect high performance. What it did was provide us with a subdialect of Fortran 77, a sort of vectorizable Fortran 77, which the whole community learned. Once they had this model of how to write vectorizable programs in Fortran 77, people could write them and run them with high performance on a variety of different vector machines. In that sense, a great deal of the architectural specificity was factored out. I think that's one of the main reasons for the success of this technology.
Now, the question is, can we achieve the similar success with automatic parallelization? As Fran Allen pointed out earlier in this session, there are a lot of people on this panel and elsewhere who are doing very hard work on this problem of automatic parallelization. I've got to say that our system, like that of Fran and of Dave Black (also a Session 5 presenter)—all of those systems—can do many impressive things. I think each of us can give you some examples in which our system does not just do impressive things but amazing things.
Unfortunately, in general we can't bet on that, which has to do with all sorts of technical problems. Mainly it has to do with the fact that if we're dealing with parallelism, at least of the MIMD asynchronous variety, we have to deal with the overhead, and that means we have to find larger and larger regions of parallelism. The imprecision of dependence analysis and all the interprocedural effects that Fran talked about are really causing problems.
Thus, I think this technology is going to make a contribution, but it's not going to be the answer in the same way vectorization technology was. That means we have to support explicit parallel programming. However, can we support that in a machine-independent way? The goal of our efforts, I think, should be to let the programmer specify parallelism at a fairly high level of abstraction, which may be contradictory if we stay within Fortran. But even within Fortran, I think we should be able to do it at a high level of abstraction, in the sense that it shouldn't depend on the machine. The programmer should specify the strategy, and the compiler should take care of the details.
If we're going to address this problem, what are the issues we have to deal with? The first issue is that we don't even know what the right programming paradigm is for these machines. If I pick anyone in the audience, I can probably get that person to tell me which paradigm he or she "knows" to be the right one. But the fact of the matter is that we can't bet on any of these because they're not proven.
There are a lot of candidates for parallel languages that we have to consider. We have to consider that the shared-memory community is centering on the Parallel Computing Forum (PCF) effort, which is, I think, going to provide at least some machine independence across all shared-memory machines. Unfortunately, not many of the massively parallel machines, except for that of the Cedar Project and IBM's RP3-Mach project, are still trying to implement shared-memory hardware. So we have to concern ourselves with the generality of PCF.
Then there's Fortran 90, which is the language of choice for the SIMD community led by Thinking Machines Corporation; also there's Linda and other languages. So one can have Fortran extensions.
There are also all sorts of efforts in compositional specifications of programming, where one takes Fortran and combines it with some specification of how to combine various Fortran modules and runs them in parallel. Then there are people who are using STRAND88 and its successors to specify parallel compositions, with Fortran as the components. Also there is the functional community, which makes the very good point that in functional languages, the dependence analysis is
precise. Unfortunately, we have a problem with mapping that down to a finite amount of memory. So the efficiencies in this area are still a major question, although there have been some strides in that direction in getting better efficiencies.
I think the language and abstract-programming model we provide is not yet clear. If we're going to have machine-independent programming, we have to have some model, and there's no resolution on what that should be like.
Another question is, how much of the tradeoff of machine independence versus efficiency can we tolerate? One of the reasons we can't do machine-independent programming right now is because the ways that we could do it are unacceptably inefficient on the machines available. A fraction of the user community agrees that they could do it in a particular language available today, but the programs that come out aren't efficient enough and have to be reprogrammed. Therefore, I think we have to understand how far we can go in abstracting the parallel decomposition process. I think a major issue is how far we can go in combining the compiler and operating system and managing the memory hierarchy, which is a major dependency that we have to deal with.
Yet another issue is, of course, that although compilers exist within an environment, I think we've seen the end of the day when a compiler sits by itself and is an independent component of the programming system. Every compiler will exist in an environment because all the tools in the environment will be intimately intertwined in their design. The debugger has to understand what the compiler does in order to present in an understandable way the execution of the program as it happened to the user. Performance tuners have to be able to explain in a language understandable to the user why the compiler chose to do the strange things that it did, not just spit out lines and lines of assembly code that are hard to trace to anything. The performance tuner has to explain how the program ran and why in somewhat high-level terms that the average user is able to grasp.
Fran talked about interprocedural compilation. Environmental support will need to be provided in order to manage that in a way that programmers will find acceptable. We have to have tools that help people prepare well-formed parallel programs in whatever language we have.
Finally, I think there's an issue of what we do if we're going to manage a memory hierarchy in a way that's transparent to the user so that we can have true machine-independent programming. To do so, I think we have to have some help from the architecture. What the form of that help is, I'm
not certain. I think that if I knew, we would be farther along in the research line than we are right now.
I think the ideas of virtual shared memory, when combined with compiler ideas, may be very promising. The Cedar Project, led by the next presenter in this session, Dave Kuck, incorporates some very interesting ideas about what things you can do with memory to support a more programmable interface. The architecture and operating system have to do more and more to support debugging and performance modeling, since those are going to be so critical in the environment that is part of the compiler system. We need to have some support to make sure we're not paying an enormous amount to achieve that.
To summarize, I think we have to have machine-independent parallel programming or we are going to waste a generation of physicists and chemists as low-level programmers. I think we need to provide a level of programming support that is consistent with what we did in vectorization. We have a long research agenda if we're going to achieve that by the end of this decade, when TFLOPS computing is to arrive.
Performance Studies and Problem-Solving Environments
David Kuck
David J. Kuck is Director of the Center for Supercomputing Research and Development, which he organized in 1984, and is a Professor of Computer Science and Electrical and Computer Engineering at the University of Illinois-Urbana/Champaign, where he has been a faculty member since 1965. He is currently engaged in the development and refinement of the Cedar parallel processing system and, in general, in theoretical and empirical studies of various machine and software organization problems, including parallel processor computation methods, interconnection networks, memory hierarchies, and the compilation of ordinary programs for such machines.
I would like to address performance issues in terms of a historical perspective. Instead of worrying about architecture or software, I think we really need to know why the architectures, compilers, and applications are not working as well as they could. At the University of Illinois, we have done some work in this area, but there is a tremendous amount of work remaining. Beyond programming languages, there are some efforts ongoing to make it possible to use machines in the "shrink-wrapped" problem-solving environment that we use in some PCs today.
Figure 1 shows a century-long view of computing, broken into a sequential (or von Neumann) era and a parallel era. The time scales show how long it takes to get the applications, architectures, compilers, etc.,
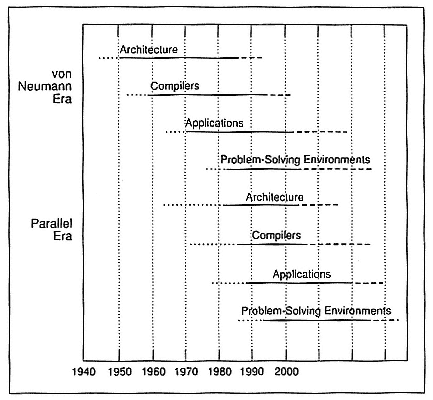
Figure 1.
Two computing eras.
that we have now and will have in the future. Because architectures, compilers, and applications are three components of performance, if you get any one of them slightly wrong, performance may be poor.
With respect to sequential machines, at about the time the RISC processors came along, you could for $5000 buy a box that you really did not program. It was a turnkey machine that you could use for lots of different purposes without having to think about it too much; you could deal with it in your own terms. I regard that kind of use of machines as an area that is going to be very important in the future.
At about the same time, in the early 1980s, companies started producing parallel architectures of all kinds. Then, with about a 30-year delay, everything in the sequential era is repeating itself. Now, for parallel machines we have compilers, and you will be able to start to buy application software one of these days.
In the von Neumann era, the performance issues were instructions, operations, or floating-point operations, reckoned in millions per second,
and the question was whether to use high-level or assembly language to achieve a 10–200 per cent performance increase. In the parallel era, the performance issues have become speedup, efficiency, stability, and tunability to vectorize, parallelize, and minimize synchronization, with performance potentials of 10X, 100X, and even 1000X. In both eras, memory-hierarchy management has been crucial, and now it is much more complex.
Some of these performance issues are illustrated in the Perfect data of Figure 2 (Berry et al. 1989), which plots 13 supercomputers from companies like Hitachi, Cray Research, Inc., Engineering Technology Associates Systems, and Fujitsu. The triangles are the peak numbers that you get from the standard arguments. The dots are the 13 codes run on all those different machines. The variation between the best and worst is about a factor of 100, all the way across. It doesn't matter which machine you run on. That is bad news, it seems to me, if you're coming from a Digital Equipment Corporation VAX. The worst news is that if I label those points, you'll see that it's not the case that some fantastic code is right up there at the top all the way across (Corcoran 1991). Things bounce around.
When you move from machine to machine, there's another kind of instability. If you decided to benchmark one machine, and you decided for price reasons to buy another, architecturally similar, one that you didn't have access to, it may not give similar performance.
The bars in Figure 2 are harmonic means. For these 13 codes on all the supercomputers shown, you're getting a little bit more that 10 million floating-point operations per second. That is one per cent of peak being delivered, and so there is a gap of two orders of magnitude there, and a gap of two orders of magnitude in the best-to-worst envelope.
If you think it's just me who is confused about all this, no less an authority than the New York Times in a two-month period during the Spring of 1990 announced, "Work Station Outperforms Supercomputer," "Cray Is Still Fastest," "Nobody Will Survive the Killer Micros," and "Japanese Computer Rated Fastest by One Measure." So there's tremendous confusion among experts and the public.
How do we get around this? Let me suggest an old remedy in a new form. Why don't we just forget about all the kinds of programming languages we have right now? If you can just specify problems and have them solved on workstations or on PCs, why can't we do that on these machines? I think we will have to eventually if parallel processing is really going to be a general success. I don't really know how to do this, but we have been thinking about it quite a bit at the Center for
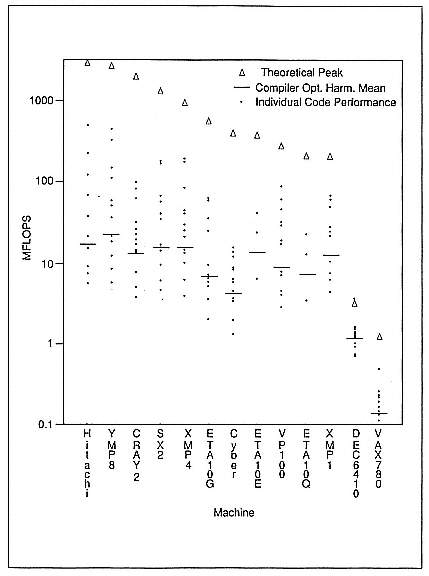
Figure 2.
Thirteen Perfect codes (instability scatter plot).
Supercomputing Research and Development (CSRD) for the last year or so on the basis of our existing software.
If you could write mathematical equations or if you could describe circuits by pictures or whatever, there would be some tremendous benefits. The parallelism that exists in nature should somehow come straight through, so you'd be able to get at that a lot easier. You would be able to adapt old programs to new uses in various ways. As examples, I should say that at Lawrence Livermore National Laboratory, there's the ALPAL system, at Purdue University there's ELLPACK, and Hitachi has something called DEQSOL. These are several examples into which parallelism is starting to creep now.
Figure 3 gives a model of what I think an adaptive problem-solving environment is. This is just your old Fortran program augmented a bit and structured in a new way. There's some logic there that represents "all" methods of solution on "all" machines. The data structures and library boxes contain lots of solution methods for lots of machines and come right out of the Perfect approach. Imagine a three-dimensional volume labeled with architectures and then for each architecture, a set of applications and each application broken down into basic algorithms. That's the way we've been attacking the Perfect database that we're building, and it flows right into this (Kuck and Sameh 1987). So you can have a big library with a lot of structure to it.
The key is that the data structures have to represent all algorithms on all machines, and I've got some ideas about how you translate from one of those to the other if you wanted to adapt a code (Kuck 1991). There are two kinds of adaptation. Take an old program and run it in some new way, e.g., on a different machine with good performance, which is the simplest case. But then, more interestingly, take two programs that should work together. You've got one that simulates big waves on the ocean, and you've got one that simulates a little airplane flying over the ocean, and you want to crash that airplane into that ocean. How would you imagine doing that? Well, I'm thinking of 20 or 30 years from now, but I think we can take steps now that might capture some of these things and lead us in that direction.
I'd like to talk a little bit about spending money. How should we spend high-performance computing money in the 1990s? I looked back at the book and the talks from the Frontiers of Supercomputing meeting in 1983, and I recalled a dozen or so companies, such as Ardent-Stellar,
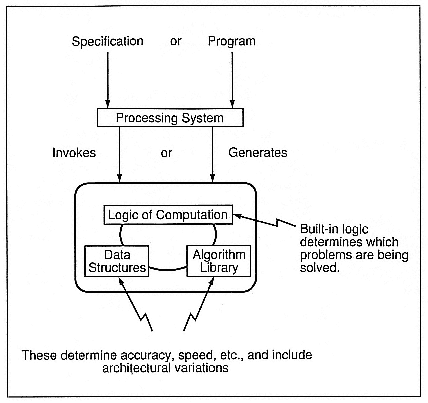
Figure 3.
Problem-solving environment model.
Masscomp-Concurrent, and Gould-Encore, that either went out of business or merged together of necessity. There were probably a billion dollars spent on aborted efforts. There are some other companies that are ongoing and have spent much more money.
On the other hand, I looked at the five universities that were represented at the 1983 meeting, and two of us, the New York University people with IBM and the Cedar group at CSRD, have developed systems (as did the Caltech group, which was not at the 1983 Frontiers meeting). Cedar has had 16 processors in four Alliant clusters running for the last year (Kuck et al. 1986). Although the machine is down right now so we can put in the last 16 processors, which will bring us up to 32, we are getting very interesting performances. We did Level 3 of the basic linear algebra subprograms and popularized parallel libraries. We've done parallelization of lots of languages, including Lisp, which I think is a big accomplishment because of the ideas that are useful in many languages. My point here is that all the money spent on university development projects is perhaps only five per cent of the industrial expenditures, so it seems to be a bargain and should be expanded.
In the 1990s the field needs money for
• research and teaching of computational science and engineering,
• development of joint projects with industry, and
• focusing on performance understanding and problem-solving environments.
For the short term, I think there is no question that we all have to look at performance. For instance, I have a piece of software now that instruments the source code, and I'm able to drive a wedge between two machines that look similar. I take the same code on machines from CONVEX Computer Corporation and Alliant Computer Systems, and frequently a program deviates from what the ratio between those machines should be, and then we are able to go down, down, down and actually locate causes of performance differences, and then we see some commonality of causes. For example, all of the loops with the middle- and inner-loop indices reversed in some subscript position are causing one machine to go down in relative performance. So those kinds of tools are absolutely necessary, and they have to be based on having real codes and real data.
I feel that we're not going to stop working on compilers; but I think we need a longer-term vision and goal, and for me that's obviously derived from the PC, after all, because it is a model that works.
References
M. Berry, D. Chen, P. Koss, D. J. Kuck, et al., "The Perfect Club Benchmarks: Effective Performance Evaluation of Supercomputers," International Journal of Supercomputer Applications3 (3), 5-40 (1989).
E. Corcoran, "Calculating Reality," Scientific American264 (1), 100-109 (1991).
D. J. Kuck, A User's View of High-Performance Scientific and Engineering Software Systems in the Mid-21st Century, Intelligent Software Systems I , North-Holland Press, Amsterdam (1991).
D. J. Kuck, E. S. Davidson, D. H. Lawrie, and A. H. Sameh, "Parallel Supercomputing Today and the Cedar Approach," Science231 , 967-974 (1986).
D. J. Kuck and A. H. Sameh, "Supercomputing Performance Evaluation Plan," in Lecture Notes in Computer Science, No. 297: Proceedings of the First International Conference on Supercomputing, Athens, Greece , T. S. Papatheodorou, E. N. Houstis, C. D. Polychronopoulos, Eds., Springer-Verlag, New York, pp. 1-17 (1987).
Systems and Software
George Spix
George A. Spix has been Director, Software Development, at Supercomputer Systems, Inc., since 1987. From 1983 to 1987, Mr. Spix was Chief Engineer, Software Development, MP Project, at Cray Research, Inc., responsible for the design and development of the user environment and operating system for the MP. From 1980 to 1983, he served in a variety of positions at Cray Research, at Los Alamos National Laboratory, and at Lawrence Livermore National Laboratory. Mr. Spix holds a B.S. in electrical engineering from Purdue University.
At Supercomputer Systems, Inc. (SSI), my main responsibility is software and systems. Our teams are responsible for the user environments; operating systems; peripherals and networks; design verification, diagnostics, testing, and quality assurance; and documentation, publications, and technical operations. The operating-systems activity, of course, has to support what we are doing in the compilation arena in terms of exposing the power of the machine to the user.
I have responsibility for peripherals and networks. This is a large area, especially because we change the balance and the resources in the machines. Every time we do that, we basically are asking the user to reprogram the application. Again, as the definition of the supercomputer changes in terms of those resources, the codes also change. Every time the codes have to be changed, that results in a loss of almost a year in terms of work hours and resources spent.
Design verification and quality assurance are currently my most difficult areas because software is typically the first victim of a hardware problem. As a result, 1990 is the year that we finished testing the machine before we built it. Also, the system does not do you much good unless you have written up how to use it, and that is another part of the challenge.
Probably our main objective at SSI is what we call minimum-time solution. This means that the users of the instrument decide they have a problem that they want to solve at the time they understand the solution. Indeed, from the first days of the company, we have been focused on that objective, which starts at the user arena in terms of how you set up your applications to the operating-system level to the I/O level. We are not just trying to build a throughput machine; we are really trying to solve the general problem and trying to lower the response time for an individual application.
Our approach has been to build architecture and hardware that have the highest performance applications and that are parallel at every level, even by default. I think, as we review hardware issues, we will see that we have succeeded in a fairly rational fashion at exploiting parallelism at almost every layer of the architecture on the machine.
Another objective at SSI is that we are focused on a visual laboratory paradigm. As you know, the early work of von Neumann at Los Alamos National Laboratory focused on the bandwidth match between the eyeball and the machine. A last, but not least, objective is to make sure that reliable software is delivered on time.
We believe we have a comprehensive parallel-processing strategy that does not leave too many stones unturned, although the massively parallel developers might look at the machine and say that we have not focused enough on massive parallelism. Our approach is to prepare for the customer an application base in terms of the relationships that SSI President and CEO Steve Chen and the company have set up with various important industrial customers or prospects, plus the relationships we have with the national laboratories. Unlike systems that were started 15 to 20 years ago, we are starting from quite a different point. We can focus our energies less on operating-system issues per se, in terms of building another type of operating system, and more on compiler problems.
There are a lot of penalties for parallel processing in the traditional world, some of which are perceptual, some architectural, and some very real. There is certainly a perception of high parallel-processing overhead because oftentimes you bring in a $20 or $30 million machine, and the administrative scheduling priorities are such that if you have 20 users
and you freeze 19 of them out to support one user well, that is not acceptable. Accounting issues relative to parallel processing come back and bite you, especially if you are doing something "automagically." If you take a 10-hour job, and it runs in two hours because the system decided that was the best way to run it, and you charge the user for 20 hours, your customer will probably be quite upset.
Compilation is viewed as expensive and complex, and it is not foreseen to change. In other words, the expertise around compilation and parallel processing tends to be kind of interesting. If you are willing to factor the user into the equation, like the massively parallel people do, and let them write the code in a form that maps well to the machine, then you have avoided some of that issue. That is a pretty elegant thing to do, but it's pretty painful in terms of user time.
Another point is that the expertise required to optimize spans a lot of disciplines. If you take the massively parallel approach, you have a physicist who not only has to understand the problem very well but also has to understand the topology of the machine that the problem is being mapped to. In the case of classical parallel processing, you have to teach a practicing scientist or engineer what it means to deal with operating-systems-type asynchronous issues and all of the problems those issues cause. We have not done a lot in terms of the Fortran development or standards development to alleviate those problems. On top of that, you get nonreproducible results. If you give a programmer asynchronous behavior in a problem, then you have to provide the tools to help with that.
I think that although we talk about parallel processing, we are actually working it in traditional fashion, somewhat against the user's interest in the sense that we are placing additional algorithmic constraints on the user's ability to get the work done. We have not provided standard languages and systems to the point where you can implement something and move it across systems. A whole different set of disciplines is required in terms of understanding and mapping a problem. In that, I think we are creating a full-employment role for system programmers, although I suspect that is against our interest as a country. We need to basically deliver tools to get the job done for the end user who is being productive and the end user who is not a programmer.
In 1976, Seymour Cray said that one of the problems with being a pioneer is that you always make mistakes. In view of that remark, I never, never want to be a pioneer; it is always best to come second, when you can look at the mistakes the pioneers made. Put another way, the fast drives out the slow, even if the fast is wrong, which kind of goes with the
idea that good software is never noticed. As a software developer, I would not like to be in a position of saying that our software will never be noticed.
Lagging I/O is certainly a focus at SSI because as the machines change balances, you add compute power and memory power and do not necessarily deal with the I/O problem. You end up again bending the user's view of the machine and bending the user's ability to get an application to run.
I think Los Alamos National Laboratory is to be commended for Don Tolmie's efforts in the arena of high-performance parallel interface (HIPPI). I think because of the 200-megabyte HIPPI, there is some chance that we will be able to bring I/O back into balance in the next generation of machines.
We can start looking at data-parallel applications and start talking about what it means to really deliver 1012 floating-point operations per second (TFLOPS), or even hundreds of TFLOPS. And having done so, we will realize what it means when memory is the processor. The challenge of the future architectures is less about the processor as an entity unto itself with some memory access and more about the memory actually being a processor.
My bottom line is that the massively parallel work that is going on—in which people actually look at algorithms in terms of data-parallel applications and look at vector machines and multiple-processor vector machines—does us nothing but good in the traditional world. The memory-as-processor is probably what will develop in the next five years as the real solution to get a TFLOPS at a reasonable rate, perhaps bypassing the people that have focused on the floating-point, 32- or 64-bit domain.