Massively Parallel SIMD Computing on Vector Machines Using PASSWORK
Ken Iobst
Kenneth Iobst received a B.S. degree in electrical engineering from Drexel University, Philadelphia, in 1971 and M.S. and Ph.D. degrees in electrical engineering/computer science from the University of Maryland in 1974 and 1981, respectively. Between 1967 and 1985, he worked as an aerospace technologist at the NASA Langley Research Center and the NASA Goddard Space Flight Center and was actively involved in the Massively Parallel Processor Project. In 1986 he joined the newly formed Supercomputing Research Center, where he is currently employed as a research staff member in the algorithms group. His current research interests include massively parallel SIMD computation, SIMD computing on vector machines, and massively parallel SIMD architecture.
When I first came to the Supercomputing Research Center (SRC) in 1986, we did not yet have a SIMD research machine—i.e., a machine with single-instruction-stream, multiple-data-streams capability. We did, however, have a CRAY-2. Since I wanted to continue my SIMD research started at NASA, I proceeded to develop a simulator of my favorite SIMD machine, the Goodyear MPP (Massively Parallel Processor), on the CRAY-2.
This SIMD simulator, called PASSWORK (PArallel SIMD Simulation WORKbench); now runs on seven different machines and represents a truly machine-independent SIMD parallel programming environment. Initially developed in C, PASSWORK is now callable from both C and
Fortran. It has been used at SRC to develop bit-serial parallel algorithms, solve old problems in new ways, and generally achieve the kind of performance one expects on "embarrassingly" parallel problems.
As a result of this experience, I discovered something about the equivalence between a vector machine and a real SIMD machine that I would now like to share with you. In general, the following remarks apply to both the Goodyear MPP and Thinking Machines Corporation's CM-2.
There are two basic views of a vector machine like the CRAY-2. In the traditional vector/scalar view, the CRAY-2 has four processors, each with 16K words of local memory, 256 megawords of globally shared memory, and a vector processing speed of four words per 4.1 nanoseconds. From a massively parallel point of view, the CRAY-2 has a variable number of bit-serial processors (4K per vector register) and a corresponding amount of local memory per processor equal to 234 processor bits.
Given an understanding of SIMD computing, one can see how the broadcast of a single instruction to multiple processors on a SIMD machine is analogous to the pipelined issue of vector instructions on a vector machine. There is a natural sort of equivalence here between these two seemingly different machine architectures.
As can be seen in Figure 1, there are two basic computing domains—a vector/scalar domain and a bit-serial domain. In the vector/scalar domain, we do things conventionally. In the bit-serial domain, we are more able to trade space for time and to solve the massively parallel parts of problems more efficiently. This higher performance results from operating on small fields or kernels with linear/logarithmic bit-serial computational complexity. In this bit-serial domain, we are operating on fully packed words, where the bits of a word are associated with single-bit processors, not with a physical numeric representation.
If you take a single problem and break it up into a conventional and a bit-serial part, you may find that a performance synergy exists. This is true whenever the whole problem can be solved in less time across two domains instead of one. This capability may depend heavily, however, on an efficient mechanism to translate between the computing domains. This is where the concept of corner-turning becomes very important.
The concept of corner-turning allows one to view a computer word of information sometimes as containing spatial information (one bit per processor) and at other times as containing numeric information, as is depicted in Figure 2. Corner-turning is the key to high-performance SIMD computing on vector machines and is best implemented in hardware with a separate vector functional unit in each CPU. With this support,
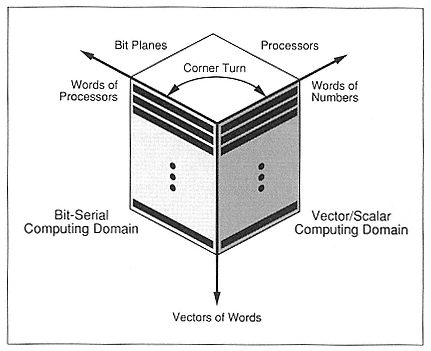
Figure 1.
Vector corner-turning operation.
vector machines would be used much more extensively for SIMD computing than they are today.
To give you an idea of how things might be done on such a machine, let's look at the general routing problem on a SIMD machine. Suppose we have a single bit of information in each of 4K processors and wish to arbitrarily route this information to some other processor. To perform this operation on a real SIMD machine requires some sort of sophisticated routing network to handle the simultaneous transmissions of data, given collisions, hot spots, etc. Typically, the latencies associated with parallel routing of multiple messages are considerably longer than in cases where a single processor is communicating with one other processor.
On a vector machine, this routing is pipelined and may suffer from bank conflicts but in general involves very little increased latency for multiple transmissions. To perform this kind of routing on a vector machine, we simply corner-turn the single bit of information across 4K processors into a 4K vector, permute the words of this vector with hardware scatter/gather, and then corner-turn the permuted bits back into the original processors.
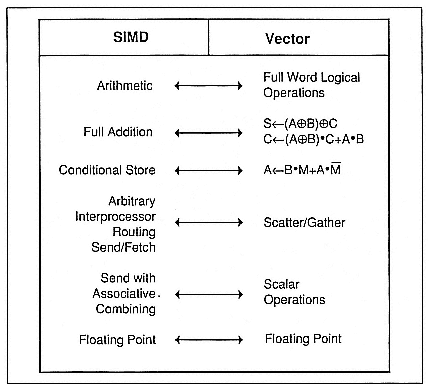
Figure 2.
SIMD/vector equivalences through corner turning.
Using this mechanism for interprocessor SIMD communication on a vector machine depends heavily on fast corner-turning hardware but in general is an order of magnitude faster than the corresponding operation on a real SIMD machine. For some problems, this routing time dominates, and it becomes very important to make corner-turning as fast as possible to minimize this "scalar part" of this parallel SIMD problem. This situation is analogous to minimizing the scalar part of a problem according to Amdahl's Law.
Figure 2 shows some other equivalences between SIMD computing and vector/scalar computing. Some of these vector/scalar operations do not require corner turning but suffer from a different kind of overhead—the large number of logical operations required to perform basic bit-serial arithmetic. For example, bit-serial full addition requires five logical operations to perform the same computation that a real SIMD machine performs in a single tick. Fortunately, a vector machine can sometimes hide this latency with multiple logical functional units. Conditional store, which is frequently used on a SIMD machine to enable or
disable computation across a subset of processors, also suffers from this same overhead.
There are some other "SIMD operations," however, that are actually performed more effectively on a vector/scalar machine than on a real SIMD machine. This seems like a contradiction, but the reference to "SIMD operation" here is used in the generic sense, not the physical sense. Operations in this class include single-bit tallies across the processors and the global "or" of all processors that is frequently used to control SIMD instruction issue.
Single-bit tallies across the processors are done much more efficiently on a vector machine using vector popcount hardware than on the much slower routing network of real SIMD machines. The global "or" of all processors on a real SIMD machine generally requires an "or" tree depth equal to the log of the number of processors. On a typical SIMD machine, the time needed to generate this signal is in the range of 300–500 nanoseconds.
On a vector machine, this global "or" signal may still have to be computed across all processors but in general can be short-stopped once one processor is found to be nonzero. Therefore, the typical time to generate the global "or" on a vector machine is only one scalar memory access, or typically 30–50 nanoseconds. This is a significant performance advantage for vector machines and clearly demonstrates that it may be much better to pipeline instructions than to broadcast them.
As stated earlier, PASSWORK was originally developed as a research tool to explore the semantics of parallel SIMD computation. It now represents a new approach to SIMD computing on conventional machines and even has some specific advantages over real SIMD machines. One of these distinct advantages is the physical mapping of real problems onto real machines. Many times the natural parallelism of a problem does not directly map onto the physical number of SIMD processors. In PASSWORK the natural parallelism of any problem is easily matched to a physical number of simulated processors (to within the next higher power of four processors).
This tradeoff between the number of processors and the speed of the processors is most important when the natural parallelism of the problem is significantly less than the physical number of SIMD processors. In this case, a vector machine, although possibly operating in a short vector mode, can always trade space for time and provide a fairly efficient logical-to-physical mapping for SIMD problems. On a real SIMD machine, there is a significant performance degradation in this case because of the underutilization of physical processors.
In a direct comparison between the CRAY-2 and the CM-2, most SIMD problems run about 10 times slower on the CRAY-2 than on the CM-2. If the CRAY-2 had hardware support for corner-turning and a memory bandwidth equivalent to the CM-2, this performance advantage would completely disappear. Most of this performance loss is due to memory subsystem design, not to basic architectural differences between the two machines; i.e., the CRAY-2 was designed with a bank depth of eight, and the CM-2 was designed with a bank depth of one. As a result, the CRAY-2 can cycle only one-eighth of its memory chips every memory cycle, whereas the CM-2 can cycle all of its memory chips every memory cycle.
As shown in Figure 3, PASSWORK basically models the MPP arithmetic logic unit (ALU), with extensions for indirect addressing and floating point. This MPP model supports both a one- and two-dimensional toroidal mesh of processors. Corner-turning is used extensively for interprocessor routing, floating point, and indirect addressing/table lookup. The PASSWORK library supports a full complement of bit-serial operations that treat bits as full-class objects. Both the massively parallel dimension and the bit-serial dimension are fully exposed to the programmer for algorithmic space/time tradeoff. Other features include
• software support for interactive bit-plane graphics on USN 3/4 workstations with single-step/animation display at 20 frames per second (512 × 512 images);
• input/output of variable-length integers expressed as decimal or hexadecimal values;
• variable-precision, unsigned-integer arithmetic, including addition, subtraction, multiplication, division, and GCD computations; and
• callable procedures from both C and Fortran.
In summary, the PASSWORK system demonstrates that a vector machine can provide the best of both SIMD and MIMD worlds in one shared-memory machine architecture. The only significant performance limits to SIMD computing on a vector machine are memory bandwidth, the ability to efficiently corner-turn data in a vector register, and the ability to perform multiple logical operations in a single tick.
In contrast to real SIMD machines, a vector machine can more easily trade space for time and provide the exact amount of parallelism needed to solve an actual problem. In addition, global operations like processor tally and global "or" are performed much faster on vector machines than on real SIMD machines.
In my opinion, the SIMD model of computation is much more applicable to general problem solving than is realized today. Causes for this
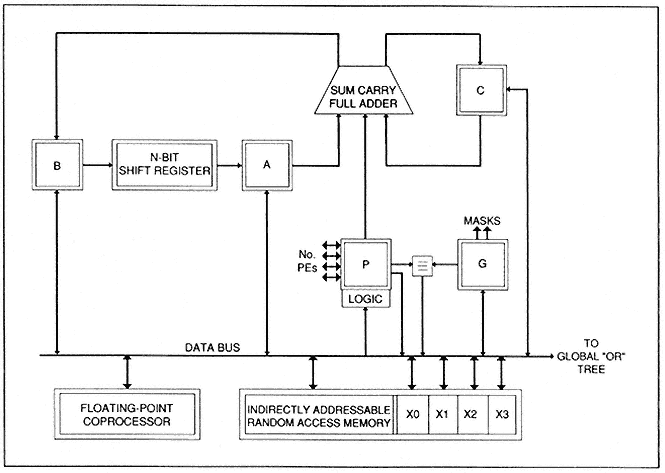
Figure 3.
MPP model.
may be more psychological than technical and are possibly due to a Catch 22 between the availability of SIMD research tools and real SIMD machines. Simulators like PASSWORK are keys to breaking this Catch 22 by providing a portable SIMD programming environment for developing new parallel algorithms on conventional machines. Ideally, results of this research will drive the design of even higher-performance SIMD engines.
Related to this last remark, SRC has initiated a research project called PETASYS to investigate the possibility of doing SIMD computing in the memory address space of a general-purpose machine. The basic idea here is to design a new kind of memory chip (a process-in-memory chip) that associates a single-bit processor with each column of a standard RAM. This will break the von Neumann bottleneck between a CPU and its memory and allow a more natural evolution from MIMD to a mixed MIMD/SIMD computing environment.
Applications in this mixed computing environment are just now beginning to be explored at SRC. One of the objectives of the PETASYS Project is to design a small-scale PETASYS system on a SUN 4 platform with 4K SIMD processors and a sustained bit-serial performance of 10 gigabit operations per second. Scaling this performance into the supercomputing arena should eventually provide a sustained SIMD
performance of 1015 bit operations per second across 64 million SIMD processors. The Greek prefix peta , representing 1015 , suggested a good name for this SRC research project and potential supercomputer—PETASYS.