Why Supercomputers Are Becoming Less General Purpose
Like their large mainframe and minicomputer cousins, the super is based on expensive packaging of ECL circuitry. As such, the evolution in performance is relatively slower (doubling every five years) than that of the single-chip microprocessor, which doubles every 18 months. One of the problems in building a cost-effective, conventional supercomputer is
that every part—from the packaging to the processors, primary and secondary memory, and the high-performance network—typically costs more than it contributes to incremental performance gains. Supercomputers built from expensive, high-speed components have elaborate processor-memory connections, very fast transfer disks, and processing circuits that do relatively few operations per chip and per watt, and they require extensive installation procedures with high operating costs.
To get the large increases in peak MFLOPS performance, the supercomputer architecture laid down at Cray Research requires having to increase memory bandwidth to support the worst-case peak. This is partially caused by Cray's reluctance to use modem cache memory techniques to reduce cost and latency. This increase in bandwidth results in a proportional increase in memory latency, which, unfortunately, decreases the computer's scalar speed. Because workloads are dominated by scalar code, the result is a disproportionately small increase in throughput, even though the peak speed of a computer increases dramatically. Nippon Electric Corporation's (NEC's) four-processor SX-3, with a peak of 22 GFLOPS, is an example of providing maximum vector speed. In contrast, one-chip microprocessors with on-board cache memory, as typified by IBM's superscalar RS/6000 processor, are increasing in speed more rapidly than supers for scientific codes.
Thus, the supercomputer is becoming a special-purpose computer that is only really cost effective for highly parallel problems. It has about the same performance of highly specialized, parallel computers like the Connection Machine, the microprocessor-based nCUBE, and Intel's multicomputers, yet the super costs a factor of 10 more because of its expensive circuit and memory technology. In both the super and nontraditional computers, a program has to undergo significant transformations in order to get peak performance.
Now look at the situation of products available on the market and what they are doing to decrease the supercomputer market. Figure 1, which plots performance versus the degree of problem parallelism (Amdahl's Law), shows the relative competitiveness in terms of performance for supersubstitutes. Fundamentally, the figure shows that supers are being completely "bracketed" on both the bottom (low performance for scalar problems) and the top (highly parallel problems). The figure shows the following items:
1. The super is in the middle, and its performance ranges from a few tens of MFLOPS per processor to over two GFLOPS, depending on the degree of parallelization of the code and the number of processors
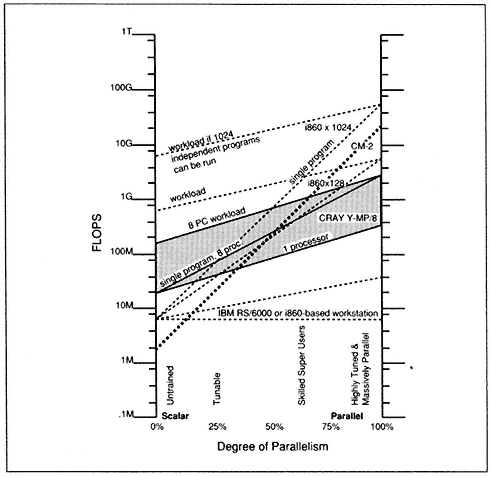
Figure 1.
Performance in floating-point operations per second versus degree of parallel code for four
classes of computer: the CRAY Y-MP/8; the Thinking Machines Corporation CM-2; the IBM
RS/6000 and Intel i860-based workstation; and the Intel 128 and 1024 iPSC/860 multicomputers.
used. Real applications have achieved sustained performance of about 50 per cent of the peak.
2. Technical workstations supply the bulk of computing for the large, untrained user population and for code that has a low degree of vectorization (that must be tuned to run well). In 1990, the best CMOS-based technical workstations by IBM and others performed at one-third the capacity of a single-processor Y-MP on a broad range of programs and cost between $10,000 and $100,000. Thus, they are anywhere from five to 100 times more cost effective than a super costing at around $2,500,000 per processor. This situation differs from a decade ago, when supers provided over a factor of 20 greater
performance for scalar problems against all computers. The growth in clock performance for CMOS is about 50 per cent per year, whereas the growth in performance for ECL is only 10 to 15 per cent per year.
3. For programs that have a high degree of parallelization, two alternatives threaten the super in its natural habitat. The parallelization has to be done by a small user base.
a. The Connection Machine costs about one-half the Y-MP but provides a peak of almost 10 times the Cray. One CM-2 runs a real-time application code at two times the peak of a Cray.
b. Multicomputers can be formed from a large collection of high-volume, cost-effective CMOS microprocessors. Intel's iPSC/860 multicomputer comes in a range of sizes from typical (128 computers) to large (1K computers). IBM is offering the ability to interconnect RS/6000s. A few RS/6000s will offer any small team the processing power of a CRAY Y-MP processor for a cost of a few hundred thousand dollars.