Some Developments in Parallel Applications
The prospects for high-performance, massively parallel applications were raised in 1987 with the demonstration, using a first-generation nCUBE system, of 1000-fold speedups for some two-dimensional simulations based on partial differential equations (Gustafson et al. 1988). The Fortran codes involved consisted of a few thousand to less than 10,000 lines of code. Let's consider what might happen when a number of parallel algorithms are applied to a large-scale scientific computing problem; i.e., one consisting of tens of thousands to a million or more lines of code.
A case study is provided by parallel radar simulation (Gustafson et al. 1989). This is, in some sense, the inverse problem to the radar problem that immediately comes to mind—the real-time processing problem. In radar simulation one takes a target, such as a tank or aircraft, produces a geometry description, and then simulates the interaction of radar with
the geometry on a supercomputer (Figure 1). These simulations are generally based on multibounce radar ray tracing and do not vectorize well. On machines like the CRAY X-MP, a radar image simulator such as the Simulated Radar IMage (SRIM) code from ERIM Inc. typically achieves five or six million floating-point operations per second per processor. Codes such as SRIM have the potential for high performance on massively parallel supercomputers relative to vector supercomputers. However, although the novice might consider ray tracing to be embarrassingly parallel, in practice radar ray tracing is subject to severe load imbalances.
The SRIM code consists of about 30,000 lines of Fortran, an amalgamation of many different algorithms that have been collected over a period of 30 years and do not fit naturally into a half megabyte of memory. The implementation strategy was heterogeneous . That is, rather than combining all of the serial codes in the application package, the structure of the software package is preserved by executing the various codes simultaneously on different portions of the hypercube (Figure 2), with data pipelined from one code in the application package to the next.
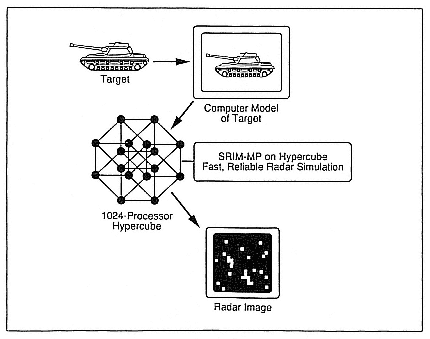
Figure 1.
A parallel radar simulation as generated by the SRIM code.
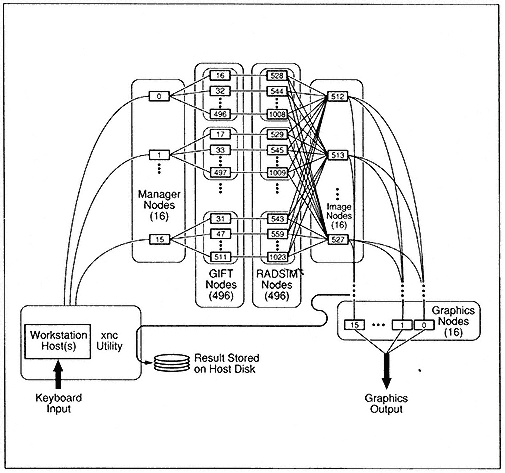
Figure 2.
Heterogeneous image simulation using a MIMD computer.
The heterogeneous implementation uses a MIMD computer in a very general MIMD fashion for the first time. An observation made by one of our colleagues concerning the inaugural Gordon Bell Prize was that the parallel applications developed in that research effort were very SIMD-like and would have performed very well on the Connection Machine. In contrast, the parallel radar simulation features, at least at the high level, a true MIMD strategy with several cooperating processes: a load-balance process, a multibounce radar ray-tracing process, an imaging process, and a process that performs a global collection of the radar image, as well as a user-supplied graphic process and a host interface utility to handle the I/O.
The nCUBE/ten version of the radar simulation, for which one had to develop a host process, had six different cooperating programs. There are utilities on second-generation hypercubes that handle direct node I/O, so a host process is no longer needed. By keeping the application code on the nodes rather than splitting it into host and node code, the resulting parallel code is much closer to the original workstation codes of Cray Research, Inc., and Sun Microsystems, Inc. Over the long haul, I think that's going to be critical if we're going to get more people involved with using massively parallel computers. Furthermore, three of the remaining five processes—the load-balance, image-collection, and graphics processes—are essentially library software that has subsequently been used in other parallel applications.
Consider the religious issue of what qualifies as a massively parallel ![]() architecture
architecture ![]() and what doesn't. Massively parallel is used rather loosely here to refer to systems of 1000 or more floating-point processors or their equivalent in single-bit processors. However, Duncan Buell (also a presenter in this session) visited Sandia recently, and an interesting discussion ensued in which he asserted that massively parallel means that a collection of processors can be treated as an ensemble and that one is most concerned about the efficiency of the ensemble as opposed to the efficiencies of individual processors.
and what doesn't. Massively parallel is used rather loosely here to refer to systems of 1000 or more floating-point processors or their equivalent in single-bit processors. However, Duncan Buell (also a presenter in this session) visited Sandia recently, and an interesting discussion ensued in which he asserted that massively parallel means that a collection of processors can be treated as an ensemble and that one is most concerned about the efficiency of the ensemble as opposed to the efficiencies of individual processors.
Heterogeneous MIMD simulations provide a nice fit to the above definition of massive parallelism. The various collections of processors are loosely synchronous, and to a large extent, the efficiencies of individual processors do not matter. In particular, one does not want the parallel efficiency of the dynamic load-balance process to be high, because that means the load-balance nodes are saturated and not keeping up with the work requests of the other processors. Processor efficiencies of 20, 30, or 50 per cent are perfectly acceptable for the load balancer, as long as only a few processors are used for load balancing and the bulk of the processors are keeping busy.