Compilers and Communication
There are three roles that compilers play in the context of parallel machines. First of all, they provide a mechanism for generating good scalar and vector node code. Since that topic is covered adequately in other papers in this volume, we will not focus on it here. Rather, we will focus on the fact that the compiler can help the user by taking advantage of opportunities for automatic parallelization, and particularly important in the context of distributed machines, there is the possibility for compilers to help the user with some of the communication activities.
The current compilers do a very good job in the area of scalar/vector node code generation, although some node ![]() architectures
architectures ![]() (e.g., i860) are quite a challenge to compiler writers. Some of the compilers also make a reasonable effort in the area of parallelization, at least in cases where data dependencies are obvious. However, there is very little to point to in the third area of compilers helping on distributed machines. The picture here is not completely bleak, so we will refer to two examples that really stand out, namely, the CM-2 and Myrias Research Corporation's SPS-2 computers. In both of these systems, the compilers and the associated run-time system really help enormously with instantiation and optimization of communication.
(e.g., i860) are quite a challenge to compiler writers. Some of the compilers also make a reasonable effort in the area of parallelization, at least in cases where data dependencies are obvious. However, there is very little to point to in the third area of compilers helping on distributed machines. The picture here is not completely bleak, so we will refer to two examples that really stand out, namely, the CM-2 and Myrias Research Corporation's SPS-2 computers. In both of these systems, the compilers and the associated run-time system really help enormously with instantiation and optimization of communication.
Myrias SPS-2:
Virtual Memory on a Distributed System
The Myrias SPS-2 system was introduced in Gary Montry's presentation earlier in this session. It is a typical distributed-memory machine, based on local nodes (Motorola MC68020) with some memory associated
and connected by busses organized in a three-level hierarchy. The SPS-2 has the remarkable feature that it supports a virtual shared memory, and that feature is what we want to focus on here. For further details on the SPS-2, see McBryan and Pozo (1990).
On the system side, virtual shared memory is implemented by the Fortran compiler and by the run-time system. The result is to present a uniform 32-bit address space to any program, independent of the number of processors being used. From the user's point of view, he can write a standard Fortran F77 program, compile it on the machine, and run it as is, without any code modification. The program will execute instructions on only one processor (assuming it is written in standard Fortran), but it may use the memory from many processors. Thus, even without any parallelization, programs automatically use the multiple memories of the system through the virtual memory. For example, a user could take a large Cray application with a data requirement of gigabytes and have it running immediately on the SPS-2, despite the fact that each node processor has only eight megabytes of memory.
With the sequential program now running on the SPS-2, the next step is to enhance performance by exploiting parallelism at the loop level. To parallelize the program, one seeks out loops where the internal code in the loop involves no data dependencies between iterations. Replacing DO with PARDO in such loops parallelizes them. This provides the mechanism to use not only the multiple memories but also the multiple processors. Developing parallel programs then becomes a two-step refinement: first, use multiple memories by just compiling the program, and second, add PARDOs to achieve instruction parallelism.
As discussed in the following section, the virtual-memory support appears to reduce SPS-2 performance by about 40 to 50 per cent. A lot of people would regard a 50 per cent efficiency loss as too severe. But we would argue that if one looks at the software advantages over long-term projects as being able to implement shared-memory code on a distributed-memory system, those 50 per cent losses are certainly affordable. However, one should note that the SPS-2 is not a very powerful supercomputer, as the individual nodes are MC68020 processors with a capacity of 150,000 floating-point operations per second (150 KFLOPS). It remains to be demonstrated that virtual memory can run on more powerful distributed systems with reasonable efficiency.
One other point that should be made is that we are not talking about virtual shared memory on a shared-memory system. The SPS-2 computer is a true distributed-memory system. Consequently, one cannot expect that just any shared-memory program will run efficiently. To run
efficiently, a program should be well suited to distributed systems to begin with. For example, grid-based programs that do local access of data will run well on such a system. Thus, while you can run any program on these systems without modification, you can only expect good performance from programs that access data in the right way.
The real benefit of the shared memory to the user is that there is no need to consider the layout of data. Data flows naturally to wherever it is needed, and that is really the key advantage to the user of such systems. In fact, for dynamic algorithms, extremely complex load-balancing schemes have to be devised to accomplish what the SPS-2 system does routinely. Clearly, such software belongs in the operating system and not explicitly in every user's programs.
Myrias SPS-2:
A Concrete Example
In this section we study simple relaxation processes for two-dimensional Poisson equations to illustrate the nature of a Myrias program. These are typical of processes occurring in many applications codes involving either elliptic PDE solutions or time-evolution equations. The most direct applicability of these measurements is to the performance of standard "fast solvers" for the Poisson equation. The code kernels we will describe are essentially those used in relaxation, multigrid, and conjugate gradient solutions of the Poisson equation. Because the Poisson equation has constant coefficients, the ratio of computational work per grid point to memory traffic is severe, and it is fair to say that while typical, these are very hard PDEs to solve efficiently on a distributed-memory system.
The relaxation process has the form
![]()
Here, the arrays are of dimensions n1 ×n2 , and s,r are specified scalars, often 4 and 1, respectively. The equation above is to be applied at each point of the interior of a two-dimensional rectangular grid, which we will denote generically as G. If the equations were applied at the boundary of G, then they would index undefined points on the right-hand side. This choice of relaxation scheme corresponds to imposition of Dirichlet boundary conditions in a PDE solver. The process generates a new solution v from a previous solution u . The process is typified by the need to access a number of nearby points. At the point i,j it requires the values of u at the four nearest neighbors.
We implement the above algorithm serially by enclosing the expression in a nested set of DO loops, one for each grid direction:
do 10 j = 2, n1-1
do 10 i = 2, n2-1
v(j,i) = s*u(j,i) + r(u(j,i-1) + u(j,i+1)
+ u(j-1,i) + u(j+1,i))
10 continue
To parallelize this code using T parallel tasks, we would like to replace each DO with a PARDO, but this in general generates too many tasks—a number equal to the grid size. Instead, we will decompose the grid G into T contiguous rectangular subgrids, and each of T tasks will be assigned to process a different subgrid.
The partitioning scheme used is simple. Let T = T1T 2 be a factorization of T . Then we divide the index interval [2,n1 - 1] into T1 essentially equal pieces, and similarly we divide [2,n 2 - 1] into T2 pieces. The tensor product of the interval decompositions defines the two-dimensional subgrid decomposition.
In case T1 does not divide n1 - 2 evenly, we can write
![]()
We then make the first r1 intervals of length h1 + 1 and the remaining T1 - r1 intervals of length h1 , and similarly in the other dimension(s). This is conveniently done with a procedure
decompose (a,b,t,istart,iend ),
which decomposes an interval [a,b ] into t near-equal-length subintervals as above and which initializes arrays istart (t ), iend (t ) with the start and end indices of each subinterval.
Thus, the complete code to parallelize the above loop takes the form
decompose(2,n1-1,t1,istart1,iend1)
decompose(2,n2-1,t2,istart2,iend2)
pardo 10 q1=1,t1
pardo 10 q2=1,t2
do 10 i= istart1(q1),iend1(q1)
do 10 j= istart2(q2),iend2(q2)
v(j,i) = s*u(j,i) + r(u(j,i-1 + u(j,i+1)
+ u(j-1,i)+ u(j+1,i))
10 continue
The work involved in getting the serial code to run on the Myrias using multiple processors involved just one very simple code modification. The DO loop over the grid points is replaced by, first of all, a DO loop over processors, or more correctly, tasks. Each task computes the limits within the large array that it has to work on by some trivial computation. Then the task goes ahead and works on that particular limit. However, the data arrays for the problem were never explicitly decomposed by the user, as would be needed on any other distributed-memory MIMD machine.
This looks exactly like the kind of code you would write on a shared-memory system. Yet the SPS-2 is truly a distributed-memory system. It really is similar to an Intel Hypercube, from the logical point of view. It is a fully distributed system, and yet you can write code that has no communication primitives. That is a key advance in the user interface of distributed-memory machines, and we will certainly see more of this approach in the future.
Myrias SPS-2:
Efficiency of Virtual Memory
We have made numerous measurements on the SPS-2 that attempt to quantify the cost of using the virtual shared memory in a sensible way (McBryan and Pozo 1990). One of the simplest tests is a SAXPY operation (adding a scalar times a vector to a vector):
![]()
We look at the change in performance as the vector is distributed over multiple processors, while performing all computations using only one processor. Thus, we take the same vector but allow the system to spread it over varying numbers of processors and then compute the SAXPY using just one processor. We define the performance with one processor in the domain as efficiency 1. As soon as one goes to two or more processors, there is a dramatic drop in efficiency to about 60 per cent, and performance stays at that level more or less independent of the numbers of processors in the domain. That then measures the overhead for the virtual shared memory.
Another aspect of efficiency related to data access patterns may be seen in the relaxation example presented in the previous section. The above procedure provides many different parallelizations of a given problem, one for each possible factorization of the number of tasks T . At one extreme are decompositions by rows (case T 1 = 1), and at the other extreme are decompositions by columns (T2 = 1), with intermediate values representing decompositions by subrectangles. Performance is
strongly influenced by which of these choices is made. We have in all cases found that decomposition by columns gives maximum performance. This is not, a priori, obvious; in fact, area-perimeter considerations suggest that virtual-memory communication would be minimized with a decomposition in which T1 = T2 . Two competing effects are at work: the communication bandwidth requirements are determined by the perimeter of subgrids, whereas communication overhead costs (including memory merging on task completion) are determined additionally by a factor proportional to the total number of data requests. The latter quantity is minimized by a column division. Row division is unfavorable because of the Fortran rules for data storage.
It is instructive to study the variation in performance for a given task number T as the task decomposition varies. We refer to this as "varying the subgrid aspect ratio," although in fact it is the task subgrid aspect ratio. We present sample results for two-dimensional relaxations in Table 1. The efficiency measures the deviation from the optimal case. Not all aspect ratios would in fact run. For heavily row-oriented ratios (e.g., T1 = 1, T 2 = T ), the system runs out of virtual memory and kills the program unless the grid size is quite small.
The Connection Machine CM-2:
Overlapping Communication with Computation
The Connection Machine CM-2 affords another good example of how a powerful compiler can provide a highly effective user interface and free the user from most communication issues. The Connection Machine is a distributed-memory (hypercube) SIMD computer, which in principle might have been programmed using standard message-passing procedures. For a more detailed description of the CM-2, see McBryan (1990).
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||
In fact, the assembly language of the system supports such point-to-point communication and broadcasting. However, Connection Machine high-level software environments provide basically a virtual shared-memory view of the system. Each of the three high-level supported languages, CM Fortran, C*, and *Lisp, makes the system look to the user as if he is using an extremely powerful uniprocessor with an enormous extended memory. These languages support parallel extensions of the usual arithmetic operations found in the base language, which allows SIMD parallelism to be specified in a very natural and simple fashion. Indeed, CM-2 programs in Fortran or C* are typically substantially shorter than their serial equivalents from workstations or Cray Research, Inc., machines because DO loops are replaced by parallel expressions.
However, in this discussion I would like to emphasize that very significant communication optimization is handled by the software. This is best illustrated by showing the nature of the optimizations involved in code generation for the same generic relaxation-type operation discussed in the previous section. We will see that without communication optimization the algorithm runs at around 800 MFLOPS, which increases to 3.8 GFLOPS when compiler optimizations are used to overlap computation and communication.
For the simple case of a Poisson-type equation, the fundamental operation v = Au takes the form (with r and s scalars)
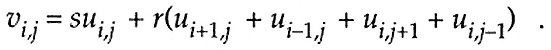
The corresponding CM-2 parallel Fortran takes the form
v = s*u + r*(cshift(u,1,1) + cshift(u,1,-1) + cshift(u,2,1)
+ cshift(u,2,-1)) .
Here, cshift (u,d,l) is a standard Fortran 90 array operator that returns the values of a multidimensional array u at points a distance l away in dimension direction d .
The equivalent *Lisp version of a function applya for v = Au is
(defun *applya (u v)
(*set v (-!! (*!! (!! s) u)
(*!! (!! r) (+!! (news!! u -1 0)
(news!! u 1 0)
(news!! u 0 -1) (news!! u 0 1)
)))))
*Lisp uses !! to denote parallel objects or operations, and as a special case, !! s is a parallel replication of a scalar s . Here (news!! u dx dy ) returns in each processor the value of parallel variable u at the processor dx processors away horizontally and dy away vertically. Thus, cshift (i + 1,j ) in Fortran would be replaced by (news!! u 1 1) in *Lisp.
The *Lisp source shown was essentially the code used on the CM-1 and CM-2 implementation described in McBryan (1988). When first implemented on the CM-2, it yielded a solution rate of only 0.5 GFLOPS. Many different optimization steps were required to raise this performance to 3.8 GFLOPS over a one-year period. Probably the most important series of optimizations turned out to be those involving the overlap of communication with computation. Working with compiler and microcode developers at Thinking Machines Corporation, we determined the importance of such operations, added them to the microcode, and finally improved the compiler to the point where it automatically generated such microcode calls when presented with the source above.
We will illustrate the nature of the optimizations by discussing the assembly language code generated by the optimized compiler for the above code fragment. The language is called PARIS, for PARallel Instruction Set. The PARIS code generated by the optimizing *Lisp compiler under version 4.3 of the CM-2 system is shown in the code displayed below. Here, the code has expanded to generate various low-level instructions, with fairly recognizable functionality, including several that overlap computation and communication, such as
cmi:get-from-east-with-f-add-always ,
which combines a communication (getting data from the east) with a floating-point operation (addition). Here is the optimized PARIS code for relaxation:
(defun *applya (u v)
(let* ((slc::stack-index *stack-index*)
(-!!-index-2 (+ slc::stack-index 32))
(pvar-location-u-11 (pvar-location u))
(pvar-location-v-12 (pvar-location v))) ,
(cm:get-from-west-always -!!-index-2
pvar-location-u-11 32)
(cm:get-from-east-always *!!-constant-index4
pvar-location-u-11 32)
(cmi::f+always-!!-index-2 *!!-constant-index4 23 8)
(cmi::get-from-east-with-f-add-always -!!-index-2
pvar-location-u-11 23 8)
(cmi::f-multiply-constant-3-always pvar-location-v-12
pvar-location-u-11 s 23 8)
(cmi::f-subtract-multiply-constant-3-always
pvar-location-v-12 pvar-location-v-12
-!!-index-2 r 23 8)
(cmi:get-from-north-always -!!-index-2
pvar-location-u-11 32)
(cmi::f-always slc::stack-index -!!-index-2 23 8)
(cmi::get-from-north-with-f-subtract-always
pvar-location-v-12 pvar-location-u-11 23 8)
(cm:get-from-south-always -!!-index-2
pvar-location-u-11 32)
(cmi::float-subtract pvar-location-v-12 slc::
stack-index -!!-index-2 23 8)
(cmi::get-from-south-with-f-subtract-always
pvar-location-v-12 -!!-index-2 23 8)
)
)
Obviously, the generated assembly code is horrendously complex. If the user had to write this code, the Connection Machine would not be selling today—even if the performance were higher than 3.8 GFLOPS! The key to the success of Thinking Machines in the last two years has been to produce a compiler that generates such code automatically, and this is where the user interface is most enhanced by the compiler. The development of an optimizing compiler of this quality, addressing communication instructions, as well as computational instructions, is a major achievement of the CM-2 software system. Because of its power, the compiler is essentially the complete user interface to the machine.