6—
USER-INTERFACE SOFTWARE
This session focused on developments and limitations of systems software for supercomputers and for parallel processing systems. Panelists discussed operating systems, compilers, debuggers, and utilities, as well as load balancing, multitasking, automatic parallelization, and models of computation.
Session Chair
Jack T. Schwartz, New York University
Parallel 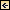 Architecture
Architecture 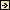 and the User Interface
and the User Interface
Gary Montry
Gary R. Montry is a freelance consultant for Southwest Software in Albuquerque, New Mexico. Until 1990, he was a Consulting Systems Engineer at Myrias Computer Corporation in Albuquerque. Gary has worked in the area of computer simulations for over 20 years. Since 1985, he has concentrated on simulation codes for massively parallel computers. In 1988, he was a recipient of the first Gordon Bell Award for achievements in parallel processing. He also received the Karp Challenge Award for his work as part of the first team ever to demonstrate parallel speedup of 200 on a parallel MIMD computer. In 1989, he received an R&D 100 Award for Contributions in Parallel Computing Software for Scientific Problems. He was the first person to successfully run a computer program using over 1000 MIMD processors. He also has the unique experience of having run parallel codes on both distributed-memory and shared-memory computers with more than 1000 processing elements.
I want to focus on parallel ![]() architectures
architectures ![]() and the user interface. My background is in parallel processing, and I have been working for vendors specializing in parallel software and shared-memory computers since 1989.
and the user interface. My background is in parallel processing, and I have been working for vendors specializing in parallel software and shared-memory computers since 1989.
Figure 1 is a tree showing what I consider to be a parallel-![]() architecture
architecture ![]() hierarchy. If you look at it very closely, you will see that none of the branches have any relationship to the other branches. The reason I drew it this way is because it helps me to enforce the points of view that I want to discuss.
hierarchy. If you look at it very closely, you will see that none of the branches have any relationship to the other branches. The reason I drew it this way is because it helps me to enforce the points of view that I want to discuss.
Figure 1.
Four major divisions of parallel ![]() architectures
architectures ![]() .
.
On the left side of the tree, I have the distributed-memory ![]() architectures
architectures ![]() —the SIMD branch and the MIMD branch. On the right-hand side of the tree, I have the shared-memory machines grouped into two branches, which I call the moderately parallel and the massively parallel branches. Massively parallel would be 200 or more processors, but the number is kind of nebulous. The reason I did the tree this way is because the interface difficulties in providing usability for the user of parallel machines are directly dependent on which side of the tree you happen to be.
—the SIMD branch and the MIMD branch. On the right-hand side of the tree, I have the shared-memory machines grouped into two branches, which I call the moderately parallel and the massively parallel branches. Massively parallel would be 200 or more processors, but the number is kind of nebulous. The reason I did the tree this way is because the interface difficulties in providing usability for the user of parallel machines are directly dependent on which side of the tree you happen to be.
On the left side of the tree, the MIMD machines provide us with Fortran and C and a couple of message-passing primitives. The same holds true for SIMD. Thus, the interface is pretty much fixed. We are given the language, a few instructions, and a few directives that allow us to pass messages. From there it is possible to build more complex interfaces that make it easier for the user to interact with the machine. A good example of that, I think, is the way Thinking Machines Corporation has brought out a new Fortran language to support their SIMD ![]() architecture
architecture ![]() , which helps to do automatic layout of the variables across the memory.
, which helps to do automatic layout of the variables across the memory.
If you are on the right-hand side of the tree, it is a lot more difficult because you have a lot more options. On the massively parallel side, I have identified three particular ![]() architectures
architectures ![]() or companies that are working on massively parallel, shared-memory machines. One company, Myrias Computer Corporation, has tried to build and market a machine that has distributed memory physically but supports shared memory globally, with a global address base across disparate processors that are connected in some kind of hierarchical fashion. (The figure reflects developments through mid-1990; a Kendall Square Research machine based on similar
or companies that are working on massively parallel, shared-memory machines. One company, Myrias Computer Corporation, has tried to build and market a machine that has distributed memory physically but supports shared memory globally, with a global address base across disparate processors that are connected in some kind of hierarchical fashion. (The figure reflects developments through mid-1990; a Kendall Square Research machine based on similar ![]() architecture
architecture ![]() had already been produced at that time, but the work had not yet been made public.)
had already been produced at that time, but the work had not yet been made public.)
Butterfly ![]() architecture
architecture ![]() —represented by the TC2000 from Bolt Beranek & Newman (BBN), the RP3 from IBM, and the Ultra Project at New York University—uses shuffle-exchange networks in order to support shared memory. One difference between these three machines and the Myrias is that while for the former there is only one copy of the operating system in the memory, for the Myrias there is a copy of the operating system on every processor.
—represented by the TC2000 from Bolt Beranek & Newman (BBN), the RP3 from IBM, and the Ultra Project at New York University—uses shuffle-exchange networks in order to support shared memory. One difference between these three machines and the Myrias is that while for the former there is only one copy of the operating system in the memory, for the Myrias there is a copy of the operating system on every processor.
I have included the Sigma machine, which is actually the first machine of a family of data-flow machines being built at Electro-Technical Laboratories in Japan. It has already been superseded by their new M machine. Their goal is to have a 1000-processor machine by 1994. Although they are currently lacking floating-point hardware and a little software, that does not mean they won't succeed—their gains have been very impressive.
The typical view of looking at the software and hardware together is a layered approach, where you have the high-level language at the top of the stack, followed by the compilers, the debuggers, and the linkers, some kind of a supervisor that is used to do I/O or to communicate with the user, and the kernel, which interacts with the hardware at the bottom level. This structure is considered to be layered because it has been
viewed historically as the way to develop software for workstations and single-processor machines. For those single-processor machines, software development can usually take place separately in each level, which contributes to the notion of independent layers of software.
On top of that, everybody wants another level of abstraction, some kind of user interface or metalanguage—maybe a graphic user interface (GUI)—to help them interact with the actual language that interacts with the machine (Figure 2). My assertion is that for parallel processors, it is too soon to have to worry about this. There are several problems in the lower layers that we have to address for massively parallel machines before we can even think about the user interface.
If we correctly design the actual interface at the language level for shared-memory parallel processors, then we will be able to leverage off work that is done for GUIs with metalanguages and user interfaces from serial-like machines in the future. So really, the programming language is the user interface. It is what you have now, and what you are going to have for the next five, six, or seven years, and it is not really going to change much. The difficulty with parallel processors is that the user interface reflects hardware and ![]() architecture
architecture ![]() dependency through the use of language extensions and/or compiler directives.
dependency through the use of language extensions and/or compiler directives.
Figure 2.
A layered approach to developing software for workstations and
single-processor machines, with metalanguages as another level on top to
help the user interact with the languages that in turn interact with the machine.
For distributed-memory machines we have message-passing subprogram calls. For a shared-memory machine we can have message-passing or locks and semaphores. For parallel processors like those from Alliant Computer Systems and the Cedar Project, in which you have lots of compiler assist, there are compiler directives, or pragmas, to indicate to the compiler and to the computer exactly what we are trying to do and how to decompose the problem ideally.
For shared-memory machines, the design of the human-machine interface at the language level is intimately tied to the particular underlying hardware and software. That means that you cannot think of the whole stack of software and hardware in the classical sense, as you would for a workstation or a serial processor. You have to think of it as a seamless environment in which the software and the hardware all have to work together at all different levels in order to cooperate and provide the parallelism.
From a functional point of view, what you really want is for all the software and hardware infrastructure to sit below a level at which the user has to view it. At the top, you only want the high-level interface of the languages to show, like the tip of an iceberg (Figure 3). To do that, you have to develop an interface that is very complex underneath but looks very simple to the user. The complexity that the user sees is inversely proportional to the amount of work that went into the interface to support it.
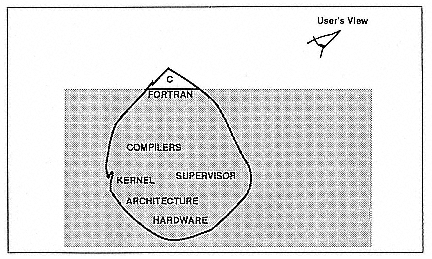
Figure 3.
Functionality of the software and hardware of a simple interface based on a
complex system.
The corollary to this concept is that complex interfaces are cheap, and simple interfaces are expensive, which is the reason you have complex interfaces on distributed-memory machines, or on the first generations thereof, because they were simple to implement and they were not very costly. An iceberg model of this interface would result in an apparent violation of the laws of physics in which the iceberg would float 90 per cent above the water and 10 per cent below the water (Figure 4).
There is another reason for wanting to have a serial look and feel to a shared-memory machine: you would like to get the feeling that when a program is run, you get the right result. You would like to have the feeling that you have an interface that is actually reproducible and trustworthy.
I can tell you some stories about the early days on the ELXSI—about a code of mine that ran for six months. Bob Benner (a Session 7 panelist) and I put it together. It was a finite-element code, and we used it to test the machine's integrity. We ran it for six months, and it always gave the same answers. I went in one day and I ran it, and it didn't give the same answer anymore. It gave different answers. So I went out and had a drink and came back later and ran it, and there was no one on the machine, and it gave the right answers. I studied the problem for a week, and I finally called up the ELXSI company and said, "You have a problem with your machine." They said, "Oh, no, you're a user; you have a problem with your code." We went around and around, and a week later I finally
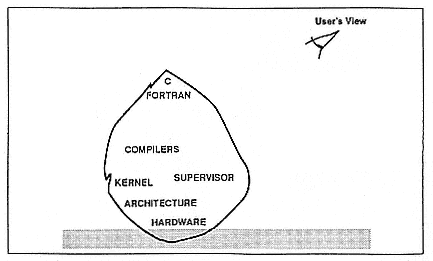
Figure 4.
Functionality of the software and hardware of a complex interface based on a
simple system.
convinced them to look at the microcode. It turned out that they had changed the microcode in their caching scheme and had failed to fully flush all caches during context switch.
So there are problems with shared-memory parallel processors in the sense of really trying to give people the feeling that both the vendor and the user have something solid. We really do want to have the look and feel of serial interfaces. To accomplish these goals, there are several requirements:
• language and compiler extensions that have the look and feel people are used to when working with computer codes;
• automatic generation of independent tasks for concurrent execution, whereby the generation is initiated by the compiler at compile time and then instantiated by the operating system during the run;
• dynamic scheduling and load balancing of independent tasks;
• automatic distribution and collection of data from concurrently executed tasks; and
• the ability to relieve the user of the burden of data locality, which is the toughest constraint of all (the easiest way to meet this last requirement is to build a common-memory machine, although such a machine is very expensive).
The machine discussed by Burton Smith in Session 4 is really a common-memory machine. It is a single-level machine, and it is very expensive. The hope is that we can build machines with memory that is distributed with the processors and still relieve the user of the burden of data locality. We can explicitly relieve the user of the burden if we have an interconnect that is fast enough, but no one can afford to build it. Actually, it is not even technologically possible to do that right now. The alternative way of eliminating the data-locality problem is with latency hiding, and asynchronous machines can do quite a bit of that.
When you look at all of these requirements and you say you want to have a number of independent tasks that you would like to be able to schedule across some kind of interconnect, you have to decide as a computer designer and builder what kind of tasks you are going to have. Are you going to have lightweight threads with very little context that could move very easily, although you might have to generate many of them? If you do, that puts particular constraints on the interconnect system that you have. Or are you going to have fewer heavyweight processes, which are larger-grained, which don't have to move quite as often, but which also don't put quite the strain on the interconnect? The interconnect is very costly in shared-memory machines, so you need to make the decision about what you want to do at the top level, which will affect your compiler and perhaps the constructs that you show to the
user, which in turn will affect the hardware at the bottom of the software/hardware hierarchy.
Now that I have outlined the technical requirements to build the machine, I will discuss the programmatic requirements.
There are five requirements I have identified that are important and that every project has to meet to build a massively parallel, shared-memory machine:
• You have to have a lot of good parallel software expertise to write the operating system and the kernel and the compilers, and they all have to work together.
• You have to have parallel hardware expertise. For that, you have to have hardware resources and people who understand how parallel machines work and what the costs and tradeoffs are for doing certain things in certain ways.
• You have to have teamwork. This may sound corny, but this is one of the most important points. There has got to be teamwork that is driven by end-users, people who are actually going to use the machine at the end so you have something that is usable. A good example of a lack of teamwork here would be the Floating Point Systems T-Series machine, for which there was plenty of hardware built, but the software was left out.
• You have to have commitment. These are long projects that last many years. If you don't think commitment is important, ask the people at Evans & Sutherland about commitment, for example.
• Finally, you need on the order of $50 to $100 million to solve the problems.
Many companies and various entities in the U.S. meet some of those five requirements, but they don't meet them all. Unless the situation changes substantially in the next few years, you probably won't see a massively parallel, shared-machine from a new entity in the U.S. It will either have to come from BBN or Myrias or the companies that are already in business.
In summary, we need to develop a somewhat standardized language implementation at the top level for shared-memory parallel processors so that we can start designing hardware and building the machines to execute that code. These hardware experiments are expensive, and in the current political and economic climate, it is not too likely that private industry is going to take on this particular challenge.
Object-Oriented Programming, Visualization, and User-Interface Issues[*]
David Forslund
David W. Forslund has served since 1989 as Deputy Director of the Advanced Computing Laboratory, Los Alamos National Laboratory. Dr. Forslund, a specialist in theoretical plasma physics, is credited with such accomplishments as the discovery of heat conduction instabilities in the solar wind and development of the first model to account for intense visible harmonics of laser light produced in CO2 laser plasmas. Much of Dr. Forslund's most original work has focused on simulation codes for applications in plasma physics. For example, he developed and has maintained the international laser fusion plasma simulation code WAVE on a multitude of operating systems and machine ![]() architectures
architectures ![]() . Further, he codeveloped the first implicit electromagnetic plasma simulation code, VENUS, with which he discovered the surface magnetic fields that have since explained many of the interactions between intense CO2 light with plasmas. Currently, he is investigating advances in human-computer interfaces and has recently demonstrated successful coupling of a scientific workstation and a supercomputer via the Network extensible Window SystemÔ.
. Further, he codeveloped the first implicit electromagnetic plasma simulation code, VENUS, with which he discovered the surface magnetic fields that have since explained many of the interactions between intense CO2 light with plasmas. Currently, he is investigating advances in human-computer interfaces and has recently demonstrated successful coupling of a scientific workstation and a supercomputer via the Network extensible Window SystemÔ.
Dr. Forslund holds an M.A. (1967) and a Ph.D. (1969) from Princeton University. During his tenure at Los Alamos, which began in 1969, he has served as a Staff Member at the Experimental Physics Division, the Associate Group Leader of the Laser Division, and the Alternate Group Leader of the Applied Theoretical Physics Division. In 1981, he was named a Laboratory Fellow. He has published widely on topics relating to plasma physics and plasma simulations and referees numerous professional journals, including the Journal of Geophysical Research, the Journal of Applied Physics, and the Journal of Computational Physics.
There are two important but disparate elements of the user interface that we will discuss in this presentation. The first is the object-oriented paradigm, which provides a useful framework for writing parallel applications, and the second is the use of visualization tools, which can provide an intuitive interface to complex applications.
Object-Oriented Parallel Programming
Object-oriented programming has become fairly common and popular and has been used in numerous computer-science projects. However, it has not yet been utilized to any degree in large-scale scientific computing. Nevertheless, we believe it is well suited to scientific computing, which frequently deals with well-defined, loosely interacting, physical objects. In particular, the paradigm is particularly useful in distributed, parallel computing because the objects help to encapsulate and clearly define the movement of data. The message interface maps well to the distributed memory model of parallel computing by constraining the mapping of data into memory. The additional features of inheritance and data abstraction also promise to reduce significantly the cost of software maintenance for large-scale scientific programs.
Distributed Computing
An important tool in defining the objects to be used in scientific computing comes from a mapping of the physical model into the computational environment. If the objects are made to correspond to physical elements in the underlying model, the paradigm fits very well. Since all of the information an object needs is stored internally, an object can also provide a good representation for a thread of control. This can greatly assist in the development of parallel applications in a way that is
independent of the hard ware on which it is being run. One can logically define the necessary number of threads (or processes) required for a given problem without worrying about the number of physical processors. This is analogous to not worrying about the size of vector registers in a supercomputer or the actual number of processors in a Thinking Machines Corporation Connection Machine.
A number of these ideas have been implemented in a distributed particle simulation code, which is reported on in the 1990 USENEX C++ conference proceedings (Forslund et al. 1990). The distributed environment for this code is the ISIS programming environment developed at Cornell University by Ken Birman (1990) and his colleagues.
Data Parallel Programming
Another area in which object-oriented programming has had success is data parallel programming. Rob Collins (personal communication), from the University of California, Los Angeles, has built an efficient C++ library for the Thinking Machines Corporation CM-2, called CM++. It gives full access to the C/Paris functionality without any loss in performance. This allows writing in a higher-level abstraction without sacrificing speed. Collins and Steve Pope of the Advanced Computing Laboratory at Los Alamos National Laboratory (personal communication) have been working on porting this library to a more general environment, called DPAR. Thus, the data-parallel paradigm has been abstracted and now runs on a workstation with good optimization. We are optimistic that this library could be made to work on a Cray Research, Inc., supercomputer, with comparable efficiency to that provided on the CM-2.
We are also trying to combine this data-parallel programming paradigm with the distributed environment we mentioned before, following some of the ideas of Guy Steele. In a paper entitled "Making Asynchronous Parallelism Safe for the World," Steele (1990) describes a programming style that tries to unify SIMD and MIMD computing. The essence of the proposal is to allow asynchronous threads to have only a restricted shared-memory access providing only commutative operations. This removes the dependence of the order of sibling parallel threads.
Threads then communicate (synchronize) only on their death. Complex operations are provided by a hierarchy of communications. This is the style we have used in our distributed particle code mentioned earlier. In one sense, this style is the simplest extension of the SIMD programming model.
Visualization Requirements
As one solves large-scale problems on massively parallel machines, the data generated become very difficult to handle and to analyze. In order for the scientist to comprehend the large volume of data, the resulting complex data sets need to be explored interactively with intuitive tools that yield realistic displays of the information. The form of display usually involves polygons and lines, image processing, and volume rendering. The desired interface is a simple, flexible, visual programming environment for which one does not have to spend hours writing code. This might involve a dynamic linking environment much like that provided by the Advanced Visualization System (AVS) from Stardent Computer or apE from the Ohio State University Supercomputer Center in Columbus.
The output need not always be precisely of physical variables but should match what we expect from our physical intuition and our visual senses. It also should not be just a collection of pretty artwork but should have physical meaning to the researcher. In this sense, we don't try to precisely match a physical system but rather try to abstract the physical system in some cases.
To handle the enormous computational requirements involved in visualization, we must also be able to do distributed processing of the data and the graphics. Besides being useful in the interpretation of significant physical and computational results, this visualization environment should be usable both in algorithmic development and debugging of the code that generates the data. The viewing should be available in both "real time" and in a postprocessing fashion, depending on the requirements and network bandwidth. To optimize the traversal of complex data sets, advanced database techniques such as object-oriented databases need to be used.
As mentioned above, there are two graphical environments available today (and possibly others) that attempt to provide the sort of capability described above. They are AVS and apE. The idea is to provide small, strongly typed, modular building blocks out of which one builds the graphical application. These are illustrated in Figure 1, which displays a schematic of the user's workspace with AVS. The data flows through the graphical "network" from the input side all the way through the graphical display. In AVS, there are four basic types of components out of which one builds the application: data that is input, filters that modify the data, mappers that change the data from one format to another, and renderers that display them on the screen. Figure 2 illustrates AVS's ability to interactively analyze data.
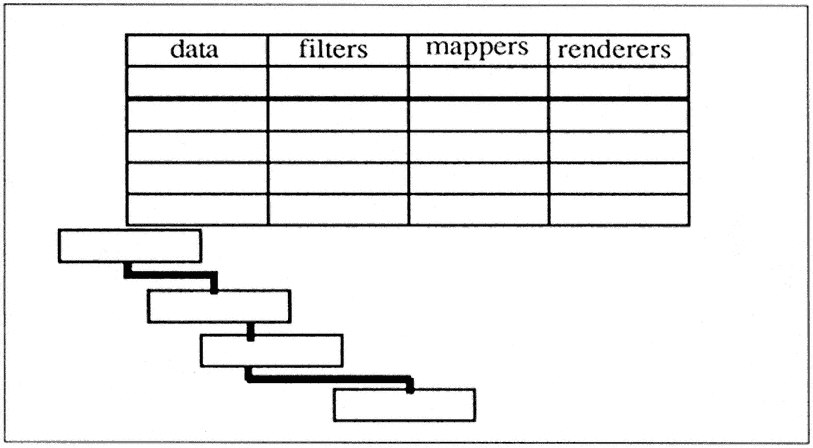
Figure 1.
A schematic of an AVS-network user's workspace.
Figure 2.
The AVS environment is used to display the complex magnetic field in a
numerical model of a Tokamak Fusion Reactor system. AVS provides a
simple visual environment, which is useful to interactively analyze the data.
Several different magnetic field surfacesare shown, as well as the trajectory
of a particle in the system.

Figure 3.
This still from a computer animation illustrates the modeling of the
propagation of smoke in elevation, latitude, and longitude generated by
the oil fires in Kuwait. A full global climate model was used, including
rain washing out the smoke. The picture shows that the smoke does
not loft into the stratosphere to cause a global climate modification.
The limit to the network complexity is only the memory and display limits of the workstation. However, this limitation can frequently be a major problem, as the size of the data set produced on current supercomputers can far exceed the capabilities of this software, even on the most powerful graphics workstations.
Because this data-flow style is, in fact, object-oriented, this model can be readily distributed or parallelized, with each module being a thread or distributed process. By placing the nodes on different machines or processors, this data-flow model can, at least in principle, be distributed or parallelized. In fact, the apE environment provides for this kind of functionality. For high performance in a graphics environment, these nodes need to be connected with a very-high-speed (e.g., gigabit/second) network if they are not running out of shared
memory on the same machine. The next generation of graphics environments of this type will hopefully operate in this manner.
A number of real physical applications are using this graphics environment, including problems that run on a CRAY Y-MP and the CM-2. For example, at the Institute of Geophysics and Planetary Physics, Los Alamos National Laboratory, a three-dimensional climate model has been run on the Cray (see Figure 3). A layer of the resulting temperature data has been taken and mapped onto a globe and displayed in an animated manner as a function of time. Using AVS, one can rotate the spherical globe while the data is being displayed, allowing one to investigate the polar regions, for example, in more detail. This is one simple example of how the data can be explored in a manner that is hard to anticipate ahead of time.
Figures 4 and 5 further illustrate the capability of high-performance graphics environments as applied to physical processes. Realistic displays like these, which can be explored interactively, are powerful tools for understanding complex data sets.
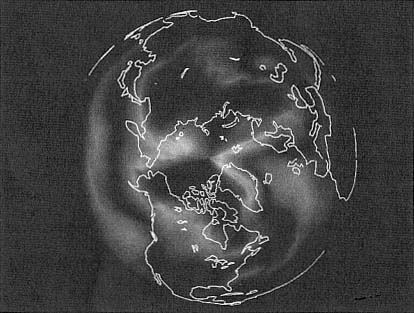
Figure 4.
Temperature distribution over the Arctic, generated by the global climate
simulation code developed at the Earth and Environmental Sciences
Division, Los Alamos National Laboratory.

Figure 5.
Model of the penetration of a high-speed projectile through a metal plate.
Note the deformation of the projectile and the splashing effect in the metal
plate. This calculation was done on a Thinking Machines Corporation CM-2.
References
K. Birman, ISIS Reference Manual, Version 2.0 , ISIS Distributed Systems, Inc., Ithaca, New York (1990).
D. Forslund, C. Wingate, P. Ford, J. Junkins, J. Jackson, S. Pope, "Experience in Writing a Distributed Particle Simulation Code in C++," in Proceedings of the USENEX C++ Conference , USENEX Association, Berkeley, California, pp. 177-190 (1990).
G. Steele, Jr., "Making Asynchronous Parallelism Safe for the World," in The Conference Record of the Seventeenth Annual ACM Symposium on the Principles of Programming Languages, San Francisco, California, 17-19 January 1990 , Association for Computing Machinery, New York, pp. 218-231 (1990).
Software Issues at the User Interface[*]
Oliver McBryan
Oliver A. McBryan studied theoretical physics at Harvard University, where he received a Ph.D. in 1973. After postdoctoral appointments at the University of Toronto and the Rockefeller University, New York, he joined the Mathematics Department faculty at Cornell University, Ithaca, New York, as an assistant professor. He moved to New York University's Courant Institute of Mathematical Sciences in 1979, taking up a post as an associate professor of mathematics and, later, as a full professor. In 1987, Dr. McBryan moved to the University of Colorado at Boulder, where he is currently Professor of Computer Science and Director of the Center for Applied Parallel Processing. His interests include parallel computation, graphics and visualization, computational fluid dynamics, statistical mechanics, and quantum field theory. He has published over 120 technical papers and reports on these subjects.
Abstract
In this presentation we review software issues that are critical to the successful integration of parallel computers into mainstream scientific computing. Clearly, on most systems, a compiler is the most important
software tool available to a user. We discuss compilers from the point of view of communication compilation—their ability to generate efficient communication code automatically. We illustrate with two examples of distributed-memory computers, on which almost all communication is handled by the compiler rather than by explicit calls to communication libraries.
Closely related to compilation is the need for high-quality debuggers. While single-node debuggers are important, parallel machines have their own specialized debugging needs related to the complexity of interprocess communication and synchronization. We describe a powerful simulation tool we have developed for such systems, which has proved essential in porting large applications to distributed memory systems.
Other important software tools include high-level languages, libraries, and visualization software. We discuss various aspects of these systems briefly. Ultimately, however, general-purpose supercomputing environments are likely to include more than a single computer system. Parallel computers are often highly specialized and rarely provide all of the facilities required by a complete application. Over the coming decade we will see the development of heterogeneous environments that will connect diverse supercomputers (scalar, vector, and parallel), along with high-end graphics, disk farms, and networking hubs. The real user-interface challenge will then be to provide a unified picture of such systems to potential users.
Introduction
This paper will survey a selection of issues dealing with software and the user interface, always in the context of parallel computing. The most obvious feature in looking back over the last five to 10 years of parallel computing is that it has been clearly demonstrated that parallel machines can be built. This was a significant issue eight or 10 years ago, particularly in the light of some early experiences. There was a feeling that the systems would be too unreliable, with mean time to failure measured in minutes and with intractable cooling and packaging issues. There are now several examples of real, highly parallel systems, such as Thinking Machine Corporation's Connection Machine CM-2 and the Intel iPSC/860, which are certainly recognized as serious computers and are among the leading supercomputers at present.
It has also been shown that model problems can be solved efficiently on these systems. For example, linear algebra problems, partial differential equation (PDE) solvers, and simple applications such as quantum
chromodynamics have been modeled effectively. In a few cases, more complex models such as oil reservoir simulations and weather models have been parallelized.
Although hardware progress has been dramatic, system software progress has been painfully slow, with a few isolated exceptions that I will highlight in the following section. Another area in which there has been almost no progress is in demonstrating that parallel computers can support general-purpose application environments. Most of what we will present here will be motivated to some extent by these failures.
We could begin by asking what a user would like from a general-purpose supercomputer application environment. In simplest terms, he would like to see a computer consisting of a processor that is as powerful as he wants, a data memory as large as his needs, and massive connectivity with as much bandwidth (internal and external) as desired. Basically, he would like the supercomputer to look like his desktop workstation. This also corresponds to the way he would like to program the system.
It is well known that there are various physical limitations, such as the finite speed of light and cooling issues, that prevent us from designing such a system. As a way around, one has been led to parallelism that replicates processors, memories, and data paths to achieve comparable power and throughput. To complicate the situation further, there are many different ways to actually effect these different connections, as well as several distinctly different choices for control of such systems. Thus, we end up with the current complexity of literally dozens of different topologies and connection strategies.
Yet the user wants to think of this whole system as a monolithic processor if possible. We will focus on several software areas where the user obviously interacts with the system and discuss ways in which the software can help with this issue of focusing on the machine as a single entity.
At the lowest level we will discuss compilers, not from the point of view of producing good machine code for the individual processors but rather from the higher-level aspect of how the compiler can help with the unifying aspect for parallel machines. Then there are the all-important debugging, trace, and simulation phases. People actually spend most of their time developing programs rather than running them, and if this phase is not efficient for the user, the system is likely ultimately to be a failure.
We will briefly discuss several related developments: higher-level languages, language extensions, and libraries. Portable parallel libraries provide a key way in which the user's interaction with systems can be simplified. Graphics and the visualization pipeline are, of course, critical
areas about which we will make several comments. For each of these topics, we will refer to other papers in these proceedings for more coverage.
Finally, we will discuss the development of software for heterogeneous environments, which is in many ways the most important software issue. No one parallel machine is going to turn out to provide the general-purpose computer that the user would really like to have. There will be classes of parallel machines, each well suited to a range of problems but unable to provide a solution environment for the full range of applications. Heterogeneous systems will allow complex algorithms to use appropriate and optimal resources as needed. So ultimately we will be building heterogeneous environments, and the software for those systems is perhaps the greatest challenge in user-interface design in the near future.
Compilers and Communication
There are three roles that compilers play in the context of parallel machines. First of all, they provide a mechanism for generating good scalar and vector node code. Since that topic is covered adequately in other papers in this volume, we will not focus on it here. Rather, we will focus on the fact that the compiler can help the user by taking advantage of opportunities for automatic parallelization, and particularly important in the context of distributed machines, there is the possibility for compilers to help the user with some of the communication activities.
The current compilers do a very good job in the area of scalar/vector node code generation, although some node ![]() architectures
architectures ![]() (e.g., i860) are quite a challenge to compiler writers. Some of the compilers also make a reasonable effort in the area of parallelization, at least in cases where data dependencies are obvious. However, there is very little to point to in the third area of compilers helping on distributed machines. The picture here is not completely bleak, so we will refer to two examples that really stand out, namely, the CM-2 and Myrias Research Corporation's SPS-2 computers. In both of these systems, the compilers and the associated run-time system really help enormously with instantiation and optimization of communication.
(e.g., i860) are quite a challenge to compiler writers. Some of the compilers also make a reasonable effort in the area of parallelization, at least in cases where data dependencies are obvious. However, there is very little to point to in the third area of compilers helping on distributed machines. The picture here is not completely bleak, so we will refer to two examples that really stand out, namely, the CM-2 and Myrias Research Corporation's SPS-2 computers. In both of these systems, the compilers and the associated run-time system really help enormously with instantiation and optimization of communication.
Myrias SPS-2:
Virtual Memory on a Distributed System
The Myrias SPS-2 system was introduced in Gary Montry's presentation earlier in this session. It is a typical distributed-memory machine, based on local nodes (Motorola MC68020) with some memory associated
and connected by busses organized in a three-level hierarchy. The SPS-2 has the remarkable feature that it supports a virtual shared memory, and that feature is what we want to focus on here. For further details on the SPS-2, see McBryan and Pozo (1990).
On the system side, virtual shared memory is implemented by the Fortran compiler and by the run-time system. The result is to present a uniform 32-bit address space to any program, independent of the number of processors being used. From the user's point of view, he can write a standard Fortran F77 program, compile it on the machine, and run it as is, without any code modification. The program will execute instructions on only one processor (assuming it is written in standard Fortran), but it may use the memory from many processors. Thus, even without any parallelization, programs automatically use the multiple memories of the system through the virtual memory. For example, a user could take a large Cray application with a data requirement of gigabytes and have it running immediately on the SPS-2, despite the fact that each node processor has only eight megabytes of memory.
With the sequential program now running on the SPS-2, the next step is to enhance performance by exploiting parallelism at the loop level. To parallelize the program, one seeks out loops where the internal code in the loop involves no data dependencies between iterations. Replacing DO with PARDO in such loops parallelizes them. This provides the mechanism to use not only the multiple memories but also the multiple processors. Developing parallel programs then becomes a two-step refinement: first, use multiple memories by just compiling the program, and second, add PARDOs to achieve instruction parallelism.
As discussed in the following section, the virtual-memory support appears to reduce SPS-2 performance by about 40 to 50 per cent. A lot of people would regard a 50 per cent efficiency loss as too severe. But we would argue that if one looks at the software advantages over long-term projects as being able to implement shared-memory code on a distributed-memory system, those 50 per cent losses are certainly affordable. However, one should note that the SPS-2 is not a very powerful supercomputer, as the individual nodes are MC68020 processors with a capacity of 150,000 floating-point operations per second (150 KFLOPS). It remains to be demonstrated that virtual memory can run on more powerful distributed systems with reasonable efficiency.
One other point that should be made is that we are not talking about virtual shared memory on a shared-memory system. The SPS-2 computer is a true distributed-memory system. Consequently, one cannot expect that just any shared-memory program will run efficiently. To run
efficiently, a program should be well suited to distributed systems to begin with. For example, grid-based programs that do local access of data will run well on such a system. Thus, while you can run any program on these systems without modification, you can only expect good performance from programs that access data in the right way.
The real benefit of the shared memory to the user is that there is no need to consider the layout of data. Data flows naturally to wherever it is needed, and that is really the key advantage to the user of such systems. In fact, for dynamic algorithms, extremely complex load-balancing schemes have to be devised to accomplish what the SPS-2 system does routinely. Clearly, such software belongs in the operating system and not explicitly in every user's programs.
Myrias SPS-2:
A Concrete Example
In this section we study simple relaxation processes for two-dimensional Poisson equations to illustrate the nature of a Myrias program. These are typical of processes occurring in many applications codes involving either elliptic PDE solutions or time-evolution equations. The most direct applicability of these measurements is to the performance of standard "fast solvers" for the Poisson equation. The code kernels we will describe are essentially those used in relaxation, multigrid, and conjugate gradient solutions of the Poisson equation. Because the Poisson equation has constant coefficients, the ratio of computational work per grid point to memory traffic is severe, and it is fair to say that while typical, these are very hard PDEs to solve efficiently on a distributed-memory system.
The relaxation process has the form
![]()
Here, the arrays are of dimensions n1 ×n2 , and s,r are specified scalars, often 4 and 1, respectively. The equation above is to be applied at each point of the interior of a two-dimensional rectangular grid, which we will denote generically as G. If the equations were applied at the boundary of G, then they would index undefined points on the right-hand side. This choice of relaxation scheme corresponds to imposition of Dirichlet boundary conditions in a PDE solver. The process generates a new solution v from a previous solution u . The process is typified by the need to access a number of nearby points. At the point i,j it requires the values of u at the four nearest neighbors.
We implement the above algorithm serially by enclosing the expression in a nested set of DO loops, one for each grid direction:
do 10 j = 2, n1-1
do 10 i = 2, n2-1
v(j,i) = s*u(j,i) + r(u(j,i-1) + u(j,i+1)
+ u(j-1,i) + u(j+1,i))
10 continue
To parallelize this code using T parallel tasks, we would like to replace each DO with a PARDO, but this in general generates too many tasks—a number equal to the grid size. Instead, we will decompose the grid G into T contiguous rectangular subgrids, and each of T tasks will be assigned to process a different subgrid.
The partitioning scheme used is simple. Let T = T1T 2 be a factorization of T . Then we divide the index interval [2,n1 - 1] into T1 essentially equal pieces, and similarly we divide [2,n 2 - 1] into T2 pieces. The tensor product of the interval decompositions defines the two-dimensional subgrid decomposition.
In case T1 does not divide n1 - 2 evenly, we can write
![]()
We then make the first r1 intervals of length h1 + 1 and the remaining T1 - r1 intervals of length h1 , and similarly in the other dimension(s). This is conveniently done with a procedure
decompose (a,b,t,istart,iend ),
which decomposes an interval [a,b ] into t near-equal-length subintervals as above and which initializes arrays istart (t ), iend (t ) with the start and end indices of each subinterval.
Thus, the complete code to parallelize the above loop takes the form
decompose(2,n1-1,t1,istart1,iend1)
decompose(2,n2-1,t2,istart2,iend2)
pardo 10 q1=1,t1
pardo 10 q2=1,t2
do 10 i= istart1(q1),iend1(q1)
do 10 j= istart2(q2),iend2(q2)
v(j,i) = s*u(j,i) + r(u(j,i-1 + u(j,i+1)
+ u(j-1,i)+ u(j+1,i))
10 continue
The work involved in getting the serial code to run on the Myrias using multiple processors involved just one very simple code modification. The DO loop over the grid points is replaced by, first of all, a DO loop over processors, or more correctly, tasks. Each task computes the limits within the large array that it has to work on by some trivial computation. Then the task goes ahead and works on that particular limit. However, the data arrays for the problem were never explicitly decomposed by the user, as would be needed on any other distributed-memory MIMD machine.
This looks exactly like the kind of code you would write on a shared-memory system. Yet the SPS-2 is truly a distributed-memory system. It really is similar to an Intel Hypercube, from the logical point of view. It is a fully distributed system, and yet you can write code that has no communication primitives. That is a key advance in the user interface of distributed-memory machines, and we will certainly see more of this approach in the future.
Myrias SPS-2:
Efficiency of Virtual Memory
We have made numerous measurements on the SPS-2 that attempt to quantify the cost of using the virtual shared memory in a sensible way (McBryan and Pozo 1990). One of the simplest tests is a SAXPY operation (adding a scalar times a vector to a vector):
![]()
We look at the change in performance as the vector is distributed over multiple processors, while performing all computations using only one processor. Thus, we take the same vector but allow the system to spread it over varying numbers of processors and then compute the SAXPY using just one processor. We define the performance with one processor in the domain as efficiency 1. As soon as one goes to two or more processors, there is a dramatic drop in efficiency to about 60 per cent, and performance stays at that level more or less independent of the numbers of processors in the domain. That then measures the overhead for the virtual shared memory.
Another aspect of efficiency related to data access patterns may be seen in the relaxation example presented in the previous section. The above procedure provides many different parallelizations of a given problem, one for each possible factorization of the number of tasks T . At one extreme are decompositions by rows (case T 1 = 1), and at the other extreme are decompositions by columns (T2 = 1), with intermediate values representing decompositions by subrectangles. Performance is
strongly influenced by which of these choices is made. We have in all cases found that decomposition by columns gives maximum performance. This is not, a priori, obvious; in fact, area-perimeter considerations suggest that virtual-memory communication would be minimized with a decomposition in which T1 = T2 . Two competing effects are at work: the communication bandwidth requirements are determined by the perimeter of subgrids, whereas communication overhead costs (including memory merging on task completion) are determined additionally by a factor proportional to the total number of data requests. The latter quantity is minimized by a column division. Row division is unfavorable because of the Fortran rules for data storage.
It is instructive to study the variation in performance for a given task number T as the task decomposition varies. We refer to this as "varying the subgrid aspect ratio," although in fact it is the task subgrid aspect ratio. We present sample results for two-dimensional relaxations in Table 1. The efficiency measures the deviation from the optimal case. Not all aspect ratios would in fact run. For heavily row-oriented ratios (e.g., T1 = 1, T 2 = T ), the system runs out of virtual memory and kills the program unless the grid size is quite small.
The Connection Machine CM-2:
Overlapping Communication with Computation
The Connection Machine CM-2 affords another good example of how a powerful compiler can provide a highly effective user interface and free the user from most communication issues. The Connection Machine is a distributed-memory (hypercube) SIMD computer, which in principle might have been programmed using standard message-passing procedures. For a more detailed description of the CM-2, see McBryan (1990).
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||
In fact, the assembly language of the system supports such point-to-point communication and broadcasting. However, Connection Machine high-level software environments provide basically a virtual shared-memory view of the system. Each of the three high-level supported languages, CM Fortran, C*, and *Lisp, makes the system look to the user as if he is using an extremely powerful uniprocessor with an enormous extended memory. These languages support parallel extensions of the usual arithmetic operations found in the base language, which allows SIMD parallelism to be specified in a very natural and simple fashion. Indeed, CM-2 programs in Fortran or C* are typically substantially shorter than their serial equivalents from workstations or Cray Research, Inc., machines because DO loops are replaced by parallel expressions.
However, in this discussion I would like to emphasize that very significant communication optimization is handled by the software. This is best illustrated by showing the nature of the optimizations involved in code generation for the same generic relaxation-type operation discussed in the previous section. We will see that without communication optimization the algorithm runs at around 800 MFLOPS, which increases to 3.8 GFLOPS when compiler optimizations are used to overlap computation and communication.
For the simple case of a Poisson-type equation, the fundamental operation v = Au takes the form (with r and s scalars)
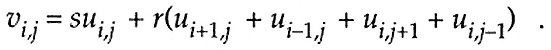
The corresponding CM-2 parallel Fortran takes the form
v = s*u + r*(cshift(u,1,1) + cshift(u,1,-1) + cshift(u,2,1)
+ cshift(u,2,-1)) .
Here, cshift (u,d,l) is a standard Fortran 90 array operator that returns the values of a multidimensional array u at points a distance l away in dimension direction d .
The equivalent *Lisp version of a function applya for v = Au is
(defun *applya (u v)
(*set v (-!! (*!! (!! s) u)
(*!! (!! r) (+!! (news!! u -1 0)
(news!! u 1 0)
(news!! u 0 -1) (news!! u 0 1)
)))))
*Lisp uses !! to denote parallel objects or operations, and as a special case, !! s is a parallel replication of a scalar s . Here (news!! u dx dy ) returns in each processor the value of parallel variable u at the processor dx processors away horizontally and dy away vertically. Thus, cshift (i + 1,j ) in Fortran would be replaced by (news!! u 1 1) in *Lisp.
The *Lisp source shown was essentially the code used on the CM-1 and CM-2 implementation described in McBryan (1988). When first implemented on the CM-2, it yielded a solution rate of only 0.5 GFLOPS. Many different optimization steps were required to raise this performance to 3.8 GFLOPS over a one-year period. Probably the most important series of optimizations turned out to be those involving the overlap of communication with computation. Working with compiler and microcode developers at Thinking Machines Corporation, we determined the importance of such operations, added them to the microcode, and finally improved the compiler to the point where it automatically generated such microcode calls when presented with the source above.
We will illustrate the nature of the optimizations by discussing the assembly language code generated by the optimized compiler for the above code fragment. The language is called PARIS, for PARallel Instruction Set. The PARIS code generated by the optimizing *Lisp compiler under version 4.3 of the CM-2 system is shown in the code displayed below. Here, the code has expanded to generate various low-level instructions, with fairly recognizable functionality, including several that overlap computation and communication, such as
cmi:get-from-east-with-f-add-always ,
which combines a communication (getting data from the east) with a floating-point operation (addition). Here is the optimized PARIS code for relaxation:
(defun *applya (u v)
(let* ((slc::stack-index *stack-index*)
(-!!-index-2 (+ slc::stack-index 32))
(pvar-location-u-11 (pvar-location u))
(pvar-location-v-12 (pvar-location v))) ,
(cm:get-from-west-always -!!-index-2
pvar-location-u-11 32)
(cm:get-from-east-always *!!-constant-index4
pvar-location-u-11 32)
(cmi::f+always-!!-index-2 *!!-constant-index4 23 8)
(cmi::get-from-east-with-f-add-always -!!-index-2
pvar-location-u-11 23 8)
(cmi::f-multiply-constant-3-always pvar-location-v-12
pvar-location-u-11 s 23 8)
(cmi::f-subtract-multiply-constant-3-always
pvar-location-v-12 pvar-location-v-12
-!!-index-2 r 23 8)
(cmi:get-from-north-always -!!-index-2
pvar-location-u-11 32)
(cmi::f-always slc::stack-index -!!-index-2 23 8)
(cmi::get-from-north-with-f-subtract-always
pvar-location-v-12 pvar-location-u-11 23 8)
(cm:get-from-south-always -!!-index-2
pvar-location-u-11 32)
(cmi::float-subtract pvar-location-v-12 slc::
stack-index -!!-index-2 23 8)
(cmi::get-from-south-with-f-subtract-always
pvar-location-v-12 -!!-index-2 23 8)
)
)
Obviously, the generated assembly code is horrendously complex. If the user had to write this code, the Connection Machine would not be selling today—even if the performance were higher than 3.8 GFLOPS! The key to the success of Thinking Machines in the last two years has been to produce a compiler that generates such code automatically, and this is where the user interface is most enhanced by the compiler. The development of an optimizing compiler of this quality, addressing communication instructions, as well as computational instructions, is a major achievement of the CM-2 software system. Because of its power, the compiler is essentially the complete user interface to the machine.
Debugging Tools
The debugging of code is a fundamental user-interface issue. On parallel machines and especially on distributed memory systems, program debugging can be extremely frustrating. Basically, one is debugging not one program, but possibly 128 programs. Even if they are all executing the same code, they are not executing the same instructions if the system is MIMD. Furthermore, there are synchronization and communications
bugs that can make it extremely difficult to debug anything. For example, one problem that can occur on distributed systems is that intermediate nodes that are required for passing data back for debugging from the node where a suspected bug has developed may themselves be sick in some form or another. Debugging messages sometimes arrive in a different order than they were sent and in any event may well be coming in multiples of 128 (or more). Finally, the overall complexity of the systems can be extremely confusing, particularly when communication data structures involve complex numbering schemes such as Grey codes.
We would like to give an example of a debugging tool that we have developed and worked with for some time, with good experiences. The tool is a parallel distributed-system simulator called PARSIM. One goal of PARSIM was to develop an extremely simple and portable simulator that could be easily instrumented and coupled with visualization.
Portability is achieved by developing a UNIX-based tool, where the lowest-level communication is implemented through a very simple data-transfer capability. The data transfer may be handled using either IP facilities or even just by using the UNIX file system. PARSIM provides library support for Intel Hypercube functionality and also library support for similar communication capabilities. All of the standard communication protocols are supported, including typed messages, broadcasts, and global operations. Finally, PARSIM is usable from Fortran or C. In fact, a user simply links the host and node programs of the application to the PARSIM library.
PARSIM maintains a full trace history of all communication activity. A portable X-11 interface provides a graphical view of all the communication activities so that as the simulation is running, one can monitor all communication traffic between nodes. The graphical display represents nodes by colored, numbered circles and represents messages by arms reaching out from the nodes. A dispatched message is represented by an arm reaching toward the destination, whereas a receive request is represented by an arm reaching out from the receiver. When a requested message is actually received, the corresponding send-and-receive arms are linked to form a single path that indicates a completed transaction. Nodes awaiting message receipt are highlighted, and the types of all messages are displayed. In addition to the main display, separate text windows are used to display the output of all node and host processes. Thus, the user can watch the communication activity on a global scale while maintaining the ability to follow details on individual processors. The display works effectively on up to 32 nodes, although typically a smaller number suffices to debug most programs. Finally, PARSIM
provides a history file that records the correct time sequence in which events are occurring. The history file may be viewed later to recheck aspects of a run, without the need to rerun the whole program.
PARSIM has turned out to be a key to porting large programs to a whole range of parallel machines, including the Intel iPSC/860. It is much easier to get the programs running in this environment than it is on the Intel. Once applications are running on the simulator, they port to the machine very quickly. As a recent example, with Charbel Farhat of the University of Colorado, we have ported a large (60,000) line finite-element program to both the iPSC/860 and the SUPRENUM-1 computers in just several weeks. Thus, user-interface tools of this type can be extremely helpful.
High-Level Languages, Extensions, Libraries, and Graphics
There has been substantial progress recently in the area of high-level languages for parallel systems. One class of developments has occurred in the area of object-oriented programming models to facilitate parallel programming. An example that I've been involved with is a C++ library for vector and matrix operations, which was implemented on the Intel Hypercube, the FPS Computing T-Series, the Ametek 2010, the Connection Machine CM-2, and several other systems. Another example is the language DINO developed by R. Schnabel and coworkers at the University of Colorado (Rosing and Schnabel 1989).
There are also some language extensions of several standard languages that are extremely important because they have a better chance of becoming standards. An example here would be the Fortran 90 flavors—for example, Connection Machine CM Fortran. A user can write pure Fortran 90 programs and compile them unchanged on the CM-2, although for best performance it is advisable to insert some compiler directives. This provides the possibility of writing a program for the Connection Machine that might also run on other parallel machines—for example, on a CRAY Y-MP. Indeed, now that many manufacturers appear to be moving (slowly) toward Fortran 90, there are real possibilities in this direction. Several similar extensions of other languages are now available on multiple systems. One good example would be the Connection Machine language extensions C* of the C language. The C* language is now available on various systems, including products from Sequent Computer and MasPar.
There are some problems with the high-level language approach. One is the lack of portability. There is increased learning time for users if they have to learn not only the lower-level aspects of systems but also how to deal with new language constructs. Finally, there is the danger of the software systems simply becoming too specialized.
A few words are in order about libraries. While there is a tremendous amount of very interesting work going on in the library area, we will not attempt to review it. A very good example is the LAPAK work. Most of that work is going on for shared-memory systems, although there are some developments also for distributed-memory machines. It is difficult to develop efficient libraries in a way that includes both shared and distributed systems.
For distributed-memory systems there is now substantial effort to develop communication libraries that run on multiple systems. One example worth noting is the SUPRENUM system, for which they have developed high-level libraries for two- and three-dimensional grid applications (Solchenbach and Trottenberg 1988). That library really helps the user who has a grid problem to deal with. In fact, it allows the user to completely dispense with explicit communication calls. One specifies a few communication parameters (topology, grid size, etc.) and then handles all interprocess communication through high-level, geometrically intuitive operations. The system partitions data sets effectively and calls low-level communication operations to exchange or broadcast data as needed.
One other point to note is that most codes in the real world don't use libraries very heavily, and so one has to be aware that not only is it important to port libraries, but also to make the technology used to design and implement algorithms in the libraries available to the scientific community in a way such that other users can adapt those same techniques into their codes.
The graphics area is certainly one of the weakest features of parallel systems. The Connection Machine is really the only system that has tightly coupled graphics capabilities—it supports up to eight hardware frame buffers, each running at 40 megabytes per second. One disadvantage with the Connection Machine solution is that graphics applications using the frame buffer are not portable. However, the ability to at least do high-speed graphics outweighs this disadvantage. In most systems, even if there is a hardware I/O capability that is fast enough, there is a lack of software to support graphics over that I/O channel. Furthermore, many systems actually force all graphics to pass through a time-shared
front-end processor and an Ethernet connection, ensuring poor performance under almost any conditions.
The best solution is certainly to tightly couple parallel systems to conventional graphics systems. This is a way to avoid developing graphics systems that are specialized to specific pieces of parallel hardware. Much effort is now under way at several laboratories to develop such high-speed connections between parallel systems and graphics stations.
We will mention an experiment we've done at the Center for Applied Parallel Processing (CAPP) in Boulder, Colorado, where we have connected a Stardent Titan and a Silicon Graphics IRIS directly to the back end of a Connection Machine CM-2, allowing data to be communicated between the CM-2 hardware and the graphics system at a very high speed, limited, in fact, only by the back-end speed of the CM-2 (Compagnoni et al. 1991). The data are postprocessed on the graphics processor using the very high polygon processing rates that are available on those two systems. This was first implemented as a low-level capability based on IP-type protocols. However, once it was available we realized that it could be used to extend the domain of powerful object-oriented graphics systems, such as the Stardent AVS system, to include objects resident on the CM-2. From this point of view, a Stardent user programs the graphics device as if the CM-2 is part of the system.
One of the advantages here is that the Connection Machine can continue with its own numeric processing without waiting for the user to complete visualization. For example, the CM-2 can go on to the next time step of a fluid code while you graphically contemplate what has been computed to date.
Another point about this approach (based on a low-level standard protocol) is that it is easy to run the same software over slow connections. In fact, we have designed this software so that if the direct connection to the back end is not available, it automatically switches to using Ethernet links. This means you don't have to be in the next room to the CM-2 hardware to use the visualization system. Of course, you won't get the same performance from the graphics, but at least the functionality is there.
Future Supercomputing Environments:
Heterogeneous Systems
Over the last 20 years we have seen a gradual evolution from scalar sequential hardware to vector processing and more recently to parallel processing. No clear consensus has emerged on an ideal ![]() architecture
architecture ![]() . The trend to vector and parallel processing has been driven by the
. The trend to vector and parallel processing has been driven by the
computational needs of certain problems, but the resulting systems are then inappropriate for other classes of problems. It is unlikely that in the near term this situation will be resolved, and indeed one can anticipate further generations of even more specialized processor systems. There is a general consensus that a good computing environment would at least provide access to the following resources:
• scalar processors (e.g., workstations),
• vector processors,
• parallel machines (SIMD and/or MIMD),
• visualization systems,
• mass-storage systems, and
• interfaces to networks.
This leads us to the last topic and what in the long run is probably the most important: heterogeneous systems, heterogeneous environments, and the importance of combining a spectrum of computing resources.
There is a simple way of avoiding the specialization problem described above. The key is to develop seamless, integrated heterogeneous computing environments. What are the requirements for such systems? Obviously, high-speed communication is paramount—that means both high bandwidth and low latency. Because different types of machines are present, a seamless environment therefore requires support for data transformations between the different kinds of hardware. Equally important, as I've argued from previous experience with single machines, is to try to support wherever possible shared-memory concepts. Ease of use will require load balancing. If there are three Connection Machines on that system, one should be able to load-balance them between the demands of different users. Shared file systems should be supported, and so on. And all of this should be done in the context of portability of the user's code because the user may not always design his codes on these systems initially. Obviously, adopting standards is critical.
Such an environment will present to the user all of the resources needed for any application: fast scalar, vector, and parallel processors; graphics supercomputers; disk farms; and interfaces to networks. All of these units would be interconnected by a high-bandwidth, low-latency switch, which would provide transparent access between the systems. System software would present a uniform, global view of the integrated resource, provide a global name space or a shared memory, and control load balancing and resource allocation.
The hardware technology now allows such systems to be built. Two key ingredients are the recent development of fast switching systems and the development of high-speed connection protocols and hardware
implementing these protocols standardized across a wide range of vendors. We illustrate with two examples.
Recently, Carnegie Mellon University researchers designed and built a 100-megabit-per-second switch called Nectar, which supports point-to-point connections between 32 processors (Arnould et al. 1989). A gigabit-per-second version of Nectar is in the design stage. Simultaneously, various supercomputer and graphics workstation vendors have begun to develop high-speed (800-megabit-per-second) interfaces for their systems. Combining these approaches, we see that at the hardware level it is already possible to begin assembling powerful heterogeneous systems. As usual, the really tough problems will be at the software level.
Several groups are working on aspects of the software problem. In our own group at CAPP, we have developed, as discussed in the previous section, a simple, heterogeneous environment consisting of a Connection Machine CM-2 and a Stardent Titan graphics superworkstation (Compagnoni et al. 1991). The Titan is connected with the CM-2 through the CM-2 back end, rather than through the much slower front-end interface that is usually used for such connectivity. The object-oriented, high-level Stardent AVS visualization system is then made directly available to the CM-2 user, allowing access to graphical objects computed on the CM-2 in real time, while the CM-2 is freed to pursue the next phase of its computation. Essentially, this means that to the user, AVS is available on the CM-2. Porting AVS directly to the CM-2 would have been a formidable and pointless task. Furthermore, the CM-2 is freed to perform the computations that it is best suited for, rather than wasting time performing hidden surface algorithms or polygon rendering. These are precisely the sorts of advantages that can be realized in a heterogeneous system.
Looking to the future, we believe that most of the research issues of heterogeneous computing will have been solved by the late 1990s, and in that time frame, we would expect to see evolving heterogeneous systems coming into widespread use wherever a variety of distinct computational resources is present. In the meantime, one can expect to see more limited experiments in heterogeneous environments at major research computation laboratories, such as Los Alamos National Laboratory and the NSF supercomputer centers.
An Application for a Heterogeneous System
We will conclude by asking if there are problems that can use such systems. We will answer the question by giving an example typical of many real-world problems.
The scientific application is the aeroelastic analysis of an airframe. The computational problem is complicated because there are two distinct but coupled subproblems to be solved. The real aerodynamic design problem is not just to compute airflow over a plane in the context of a static frame but to design planes the way they are flown, which is dynamically. As soon as you do that, you get into the coupled problem of the fluid flow and the airframe structure. There is a structural engineering problem, which is represented by the finite-element analysis of the fuselage and the wing. There is a fluid-dynamics problem, which is the flow of air over the wing surface. Finally, there is a real interaction between these two problems. Obviously, the lift depends on the wing surface, but correspondingly, the fluid flow can cause vibrations in the wing.
One can represent the computation schematically as a two-dimensional (surface) structural problem with O (N2 ) degrees of freedom or as a three-dimensional fluid problem with, typically, O (N3 ) degrees of freedom. Here N measures the spatial resolution of each problem.
Typically, the fluid computation can be solved by explicit methods, but the finite-element problem requires implicit solution techniques. The fluid models require solution time proportional to the number of degrees of freedom. The finite-element problems are typically sparse matrix problems, and it is hard to do better than O (N3 ) on solution times. Thus, we have a computation that is O (N3 ) for both the fluid and structure components.
Thus, the two computational phases are much the same in overall computational complexity. However, the communication of data, the interaction between the two phases, is related to the surface, only, and is therefore an O (N2 ) data-transfer problem. Therefore, provided one is solving a large enough problem so that the O (N2 ) communication cost is negligible, one can imagine solving the fluid part on a computer that is most effective for fluid computation and the structural part on a machine that is most effective for structural problems.
We have been studying this problem quite actively at the University of Colorado (Farhat et al. 1991, Saati et al. 1990, and Farhat et al. 1990) and have found that the fluid problem is best done on a machine like the
Connection Machine, on which one can take advantage of the SIMD ![]() architecture
architecture ![]() and work with grids that are logically rectangular. The structural problem is best done on machines that can handle irregular grids effectively, for example, a CRAYY-MP. Thus, ideally we would like to solve the whole problem on a heterogeneous system that includes both Cray and CM-2 machines. One should also remember that both phases of this computation have heavy visualization requirements. Thus, both systems need to be tightly coupled to high-end graphics systems. Furthermore, if a record is to be saved of a simulation, then high-speed access to a disk farm is mandatory because of the huge volumes of data generated per run. A fully configured heterogeneous environment is therefore essential.
and work with grids that are logically rectangular. The structural problem is best done on machines that can handle irregular grids effectively, for example, a CRAYY-MP. Thus, ideally we would like to solve the whole problem on a heterogeneous system that includes both Cray and CM-2 machines. One should also remember that both phases of this computation have heavy visualization requirements. Thus, both systems need to be tightly coupled to high-end graphics systems. Furthermore, if a record is to be saved of a simulation, then high-speed access to a disk farm is mandatory because of the huge volumes of data generated per run. A fully configured heterogeneous environment is therefore essential.
Conclusions
We conclude by remarking that the winning strategy in supercomputer design for the coming decade is certainly going to be acquisition of a software advantage in parallel systems. Essentially all of the MIMD manufacturers are likely to be using competitive hardware. It is clear from recent experiences—for example, Evans & Sutherland—that using anything other than off-the-shelf components is too expensive. It follows immediately that different manufacturers can follow more or less the same upgrade strategies. They will end up with machines with basically similar total bandwidths, reliability, and so on. Thus, the key to success in this market is going to be to develop systems that have the best software. Key points there will be virtual shared-memory environments and general-purpose computing capabilities.
References
E. A. Arnould, F. J. Bitz, E. C. Cooper, H. T. Kung, et al., "The Design of Nectar: A Network Backplane for Heterogeneous Multicomputers," in Proceedings of the Third International Conference on ![]() Architecture
Architecture ![]() Support for Programming Languages and Operating Systems (ASPLOS III) , Association for Computing Machinery, pp. 205-216 (1989).
Support for Programming Languages and Operating Systems (ASPLOS III) , Association for Computing Machinery, pp. 205-216 (1989).
L. Compagnoni, S. Crivelli, S. Goldhaber, R. Loft, O. A. McBryan, et al., "A Simple Heterogeneous Computing Environment: Interfacing Graphics Workstations to a Connection Machine," Computer Science Department technical report, University of Colorado, Boulder (1991).
C. Farhat, S. Lanteri, and L. Fezoui, "Mixed Finite Volume/Finite Element Massively Parallel Computations: Euler Flows, Unstructured Grids, and Upwind Approximations," in Unstructured Massively Parallel Computations , MIT Press, Cambridge, Massachusetts (1991).
C. Farhat, N. Sobh, and K. C. Park, "Transient Finite Element Computations on 65,536 Processors: The Connection Machine," International Journal for Numerical Methods in Engineering30 , 27-55 (1990).
O. A. McBryan, "The Connection Machine: PDE Solution on 65,536 Processors," Parallel Computing 9 , 1-24 (1988).
O. A. McBryan, "Optimization of Connection Machine Performance," International Journal of High Speed Computing2 , 23-48 (1990).
O. A. McBryan and R. Pozo, "Performance of the Myrias SPS-2 Computer," Computer Science Department technical report CU-CS-505-90, University of Colorado, Boulder (1990). To appear in Concurrency: Practice and Experience .
M. Rosing and R. B. Schnabel, "An Overview of Dino—A New Language for Numerical Computation on Distributed Memory Multiprocessors," in Parallel Processing for Scientific Computation , Society for Industrial and Applied Mechanics, Philadelphia, pp. 312-316 (1989).
A. Saati, S. Biringen, and C. Farhat, "Solving Navier-Stokes Equations on a Massively Parallel Processor: Beyond the One Gigaflop Performance," International Journal of Supercomputer Applications4 (1), 72-80 (1990).
K. Solchenbach and U. Trottenberg, "SUPRENUM—System Essentials and Grid Applications," Parallel Computing7 , 265-281 (1988).
What Can We Learn from Our Experience with Parallel Computation up to Now?
Jack T. Schwartz
Jack T. Schwartz is Professor of Mathematics and Computer Science at New York University's Courant Institute of Mathematical Sciences. Trained as a mathematician at Yale University, he has worked in a variety of subjects, including functional analysis, mathematical economics, computer design, parallel ![]() architectures
architectures ![]() , programming-language design, and robotics. Currently, he is interested in the design of interactive computer systems and interfaces.
, programming-language design, and robotics. Currently, he is interested in the design of interactive computer systems and interfaces.
In this talk I wish to raise a few questions rather than try to answer any. My first question is, what does the way in which parallel computers are currently being used tell us about how they will be used? In this connection, I would like to distinguish among a number of computational paradigms into which particular problems might fit.
The most successful paradigm so far has been the SIMD paradigm, which exists in a number of versions, and all, of course, are evolving. It is worth distinguishing between two types of SIMD computation: the "lockstep" kind of computation (which is what the hardware forces you to if it is vector hardware or some other form of hardware that is centrally driven) and the "relaxed SIMD" paradigm (which you would have on a machine that is basically SIMD, at least in its software structure, but that permits independent branching within a DOALL loop). The latter sort of machine will handle complex loops with subroutine calls in a much more comfortable way than
a lockstep machine, but in both cases SIMD software organization will leave one still thinking of problems in a SIMD mode.
Along the spectrum that runs from "relaxed SIMD" to a true MIMD paradigm, there arise other distinctions between a number of types of MIMD calculations. The first of these paradigms is the Monte Carlo class of MIMD calculations, which represents a particularly advantageous pole within the MIMD world. In Monte Carlo, one uses what are essentially independent complex processes, which only need to interact when their results are combined at the end of what may be a very long calculation. One generates almost independent parallel computations at an arbitrary scale—the ideal case for a MIMD machine.
A second class of MIMD computations, which requires more communication, is typified by chaotic relaxation schemes. Here, communication is required, but the numerical method used does not always have to have absolutely up-to-date information about what's going on at the neighbors of a good data point, as long as the available information is updated often. The broad applicability of this general idea, i.e., the fact that it can be expected to lead to stable and convergent calculations, is reflected in the familiar fact that I need read a newspaper only once a day instead of every minute and nevertheless can feel this keeps me reasonably current about what's happening in the world. This remark on communication within an algorithmic process reflects a very fundamental point: communication latencies within parallel systems are likely to increase because it may simply not be feasible as machines get larger and larger to provide absolutely current remote information to all their processors or to keep caches fully current. Indeed, this consideration may define a whole class of computations that theorists haven't considered in depth but that deserve attention—computations that simply ignore the noncurrency of data but work out well, anyhow.
Another class of algorithms that has stood very much in the forefront of the thinking of people who begin from the MIMD end of the parallel computer design spectrum is the "workpile" kind of computation. Let me distinguish between two types of such algorithms. The first is the class of "compute-driven" workpile computations, as typified by Lisp theorem-prover searches. Such searches find more and more branches to explore and simply throw those branches onto a pile; the branches are subsequently picked up by some processor whose prior exploration has ended. The second class is the "data-driven" workpile algorithms, typified by a large commercial database system in which only one processor can do a particular piece of work, that processor being the one on whose
disk the data required for the work in question is resident. Parallel applications of this sort suggest the use of highly parallel collections of "servers."
I hope that presentations at this conference can help to answer the following questions, which seem to me to be strategic for the development of parallel computers and computation over the next few years:
• What are the basic paradigms of parallel computation? Will both parallel ![]() architectures
architectures ![]() and the languages that constitute the user-hardware interface evolve around those paradigms? Are there other paradigms that can be defined as broadly as those I have listed and that are equally important?
and the languages that constitute the user-hardware interface evolve around those paradigms? Are there other paradigms that can be defined as broadly as those I have listed and that are equally important?
• Are all the paradigms outlined above really important? Are they all of roughly equal importance, or does our experience to date suggest that some are much more important than others? For example, there seems to have been much more success in the "relaxed SIMD" mode use of parallel computations than in the Monte Carlo mode. Is this true? If so, what does it tell us about the future?
• Are all of the cases that I have listed really populated? For example, are there really any important compute-driven workpile algorithms, or is their existence a myth propagated by people who have thought about these algorithms from a theoretical point of view?
I raise these questions because I believe that they can help give some shape to the question of where parallel computer hardware and software design is going.