10—
GOVERNMENT SUPERCOMPUTING
This panel included users from various organs of government—voracious consumers of computers and computing since the 1940s. National laboratories, the intelligence community, the federal bureaucracy, and NSF computing centers all make use of supercomputers. The panel concentrated on the future and referred to the past to give the future some perspective. Panelists agreed that all the problems identified during the first Frontiers of Supercomputing conference have not been solved. Thus, the panelists focused on continuing challenges related to cultural issues, support, efficiency versus user friendliness, technology transfer, impediments to accessibility, and government policy.
Session Chair
George Michael
Lawrence Livermore National Laboratory
Planning for a Supercomputing Future[*]
Norm Morse
For most of the past decade, Norman R. Morse has served as leader of the Computing and Communications Division at Los Alamos National Laboratory. He has a bachelor's degree in physics from Texas A&I University, Kingsville, and a master of science in electrical engineering and computer science from the University of New Mexico, Albuquerque. Under his leadership, the Laboratory's computing facilities were expanded to include the newly constructed Data Communications Center and the Advanced Computing Laboratory. In addition, he promoted the use of massively parallel computers, and through his efforts, the facilities now house three Connection Machines—two CM-2s and one CM-5. Norm recently returned to a staff position, where he plans to pursue research in clustered workstation paradigms for high-performance computing.
Over the past few years I, together with other people from Los Alamos National Laboratory, have been examining the state of computing at Los Alamos and have been thinking about what our desired future state of computing might be. I would like to share with you some of the insights
that we have had, as well as some thoughts on the forces that may shape our future.
We used a strategic planning model to guide our thinking. Figure 1 shows that model. From a particular current state of computing, there are many possible future states into which institutional computing can evolve, some of them more desirable than others. There are drivers that determine which one of these possible future states will result. We have been interested in examining this process and trying to understand the various drivers and how to use them to ensure that we arrive at what we perceive to be our desired state of computing.
In the late 1960s and early 1970s, the current state of computing was batch. We had evolved from single-user systems into a batch-processing environment. The future state was going to evolve from that state of technology and from the influences of that time.
The evolution from batch computing to timesharing computing came from a variety of drivers (Figure 2). One major driver was technology: terminals were invented about that time, and some rudimentary network capabilities were developed to support the needs for remote computing. The mainframes essentially didn't change—they were von Neumann central supercomputers. Software was developed to support a timesharing model of computing. And an important, nontechnical factor was that the money for computing came in through the applications that
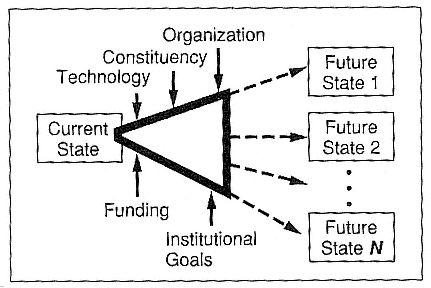
Figure 1.
General model of the evolution of institutional computing.
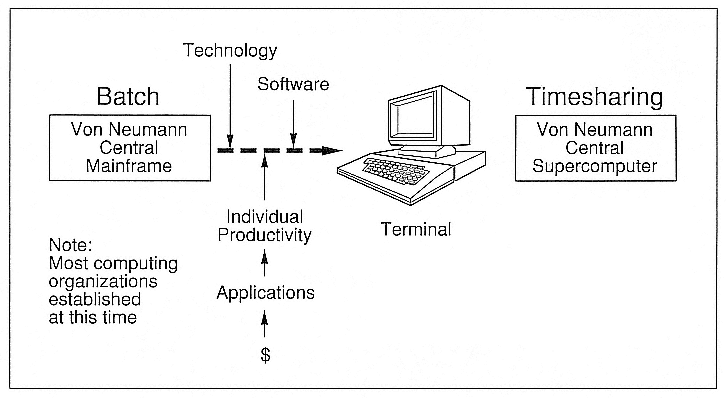
Figure 2.
The evolution from batch to timesharing computing in the 1970s.
people were interested in solving. The people who were developing and running those applications were interested in individual productivity.
It may have been in this period of time that we stopped thinking that machine productivity was the most important issue that we had to deal with, and we began to think that the productivity of the individuals who were using the machine should be maximized. So we evolved into a timesharing environment in the 1970s. We recognized the value of a centrally managed network and central services to support timesharing. Mass storage and high-quality print services became an important part of the network.
In the 1980s we went from a timesharing environment to a distributed environment (Figure 3). And again, the important influences that drove us from timesharing to distributed included advances in technology. But there were also other factors: a large user community required more control of their computing resource, and they valued the great increase in interactivity that came from having a dedicated computer on their desks.
The 1980s became the era of workstations—a lot of computational power that sat on your desk. Networks became more reliable and universal. We began to understand that networks were more than just wires that tied computers together. Users needed increased functionality, as well as more bandwidth, to handle both the applications and the user interfaces. Many of the centralized services began to migrate and were managed on user networks. We started thinking about doing visualization. Von Neumann central supercomputers, along with departmental-class mainframes, were still the workhorses of this environment. Massively parallel supercomputers were being developed.
The next environment hasn't sorted itself out yet. The future picture, from a hardware and software technology viewpoint, is becoming much more complicated. We're calling the next environment the high-performance computing environment (Figure 4).
Again, there are N possible future states into which we could evolve. The drivers or enablers that are driving the vector from where we are now to where we want to be in the future are getting more complicated, and they're not, in all cases, intuitively obvious.
The high-performance computing model that I see evolving, at least at Los Alamos, is one composed of three major parts: parallel workstations, networks, and supercomputers. I think that general-purpose computing is going to be done on workstations. The supercomputers are going to end up being special-purpose devices for the numerically intensive
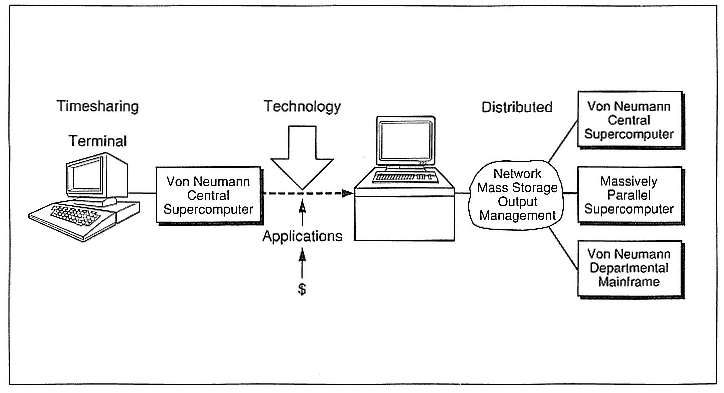
Figure 3.
The evolution from a timesharing- to a distributed-computing environment in the 1980s.
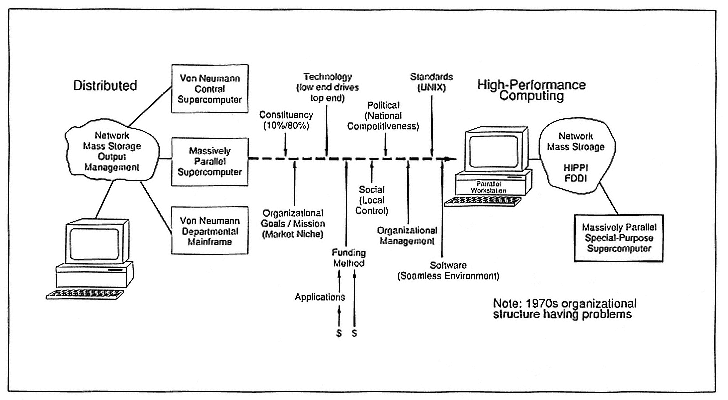
Figure 4.
High-performance computing emerging from a distributed-computing environment in the 1990s.
portion of client tasks. In fact, I personally think they've always been special purpose, regardless of how much work we've put in to try to make them general-purpose devices. I think in the long term, supercomputers have to be massively parallel to achieve the speeds required to solve the grand-challenge problems. That's not to say that the workhorses of today will go away; the von Neumann vector pipeline machines and the departmental-class machines have been around for a long time and will remain essential for a large class of problems.
This high-performance computing environment will evolve and will consist of these three major elements. The real questions are, what will be the balance among them, and how well does that balance satisfy the needs of a particular organization?
Constituency is one of the important drivers. The workstations sitting on people's desks and the computers that people typically learn to use in universities are a very important part of the high-performance computing environment. Of the 8000 clients who use our computing center, virtually every one of them uses a personal computer. Somewhere around 250 people use 90 per cent of our supercomputing cycles in any given month. So when we looked for people to argue for various parts of this high-performance computing environment, we could find 8000 people who would argue for the workstation part. The Laboratory internet is becoming increasingly important to a broad population in the Laboratory because of the need to communicate with colleagues locally and internationally. So we could find 8000 people who would argue for networks. But on the other hand, there are only a few hundred who will argue vehemently for the supercomputing environment. This kind of support imbalance can shift the future state to one in which there is a strong workstation and network environment but a very weak supercomputing capability.
I would guess that the statistics at most sites are similar to this. There are a small number of people who dominate the use of the supercomputing resources, doing problems that are important to the mission of the institution. And if the institution is in the business of addressing grand-challenge problems, it takes a lot of supercomputing cycles to address those problems.
Given the environment described, I feel that the low-end technology will drive this evolution and is going to drive the top end. That is, the massively parallel supercomputers of the future will be made up of building blocks (hardware and software) developed for the workstation market. There are many reasons driving this trend, but one of the most important is the fact that the workstation market is huge compared with
the supercomputer market. A tremendous effort is under way to develop hardware and software for the workstation market. If supercomputers are made from workstation building blocks, the remaining question is whether the supercomputing capability will be closely coupled/closely integrated or loosely coupled/closely integrated. The marketplace will shake out the answer in the next few years.
Standards are going to be even more important in this new environment. For example, UNIX is going to run across the whole environment. It should be easy for people to do as much of their work on workstations as possible, and, when they run out of the power to do their work there, they will be able to use other, more powerful or less heavily used resources in the network to finish their jobs. This means that the UNIX systems must be compatible across a large variety of computing platforms. Computing vendors need to cooperate to build software systems that make this easy.
Another important driver, the funding method, may be different from what we've seen in the past. Traditionally, the money has come in through the applications, driving the future state of computing. The applications people drive the capabilities that they need. With the High Performance Computing Initiative, there is the potential, at least, for money to come directly into building a computing capability. And I think we need to be very careful that we understand what this capability is going to be used for. If we end up building a monument to computing that goes unused, I think we will not have been very successful in the High Performance Computing Initiative.
One last issue that I'll mention is that there are a lot of social issues pushing us toward our next state of computing. Local control seems to be the most important of those. People like to eliminate all dependencies on other folks to get their jobs done, so local control is important. We need to make the individual projects in an organization cognizant of the mission of the organization as a whole and to maintain capabilities that the organization needs to secure its market niche.
High-Performance Computing at the National Security Agency
George Cotter
George R. Cotter currently serves as Chief Scientist for the National Security Agency (NSA). From June 1988 to April 1990, he was the Chairman of the Director's Senior Council, a study group that examined broad NSA and community issues. From June 1983 to June 1988, Mr. Cotter served as Deputy Director of Telecommunications and Computer Services at NSA, in which position he was responsible for implementing and managing worldwide cryptologic communications and computer systems.
Mr. Cotter has a B.A. from George Washington University, Washington, DC, and an M.S. in numerical science from Johns Hopkins University, Baltimore, Maryland. He has been awarded the Meritorious and Exceptional Civilian Service medals at NSA and in 1984 received the Presidential Rank of Meritorious Cryptologic Executive. Also in 1984, he received the Department of Defense Distinguished Civilian Service Award.
Introduction
High-performance computing (HPC) at the National Security Agency (NSA) is multilevel and widely distributed among users. NSA has six major HPC complexes that serve communities having common interests. Anywhere from 50 to several hundred individuals are served by any one complex. HPC is dominated by a full line of systems from Cray Research,
Inc., supplemented by a few other systems. During the past decade, NSA has been driving toward a high level of standardization among the computing complexes to improve support and software portability. Nevertheless, the standardization effort is still in transition. In this talk I will describe the HPC system at NSA. Certain goals of NSA, as well as the problems involved in accomplishing them, will also be discussed.
Characterization of HPC
NSA's HPC can handle enormous input data volumes. For the division between scalar and vector operations, 30 per cent scalar to 70 per cent vector is typical, although vector operations sometimes approach 90 per cent. Little natural parallelism is found in much of the code we are running because the roots of the code come from design and implementations on serial systems. The code has been ported and patched across 6600s, 7600s, CRAY-1s, X-MPs, and right up the line. We would like to redo much of that code, but that would present a real challenge.
An important characteristic of our implementation is that both batch and interactive operations are done concurrently in each complex with much of the software development. Some of these operations are permanent and long-term, whereas others are experimental. The complexes support a large research community. Although interactive efforts are basically day operations, many batch activities require operating the systems 24 hours a day, seven days a week.
HPC Architecture
At NSA, the HPC operating environment is split between UNIX and our home-grown operating system, Folklore, and its higher-level language, IMP. The latter is still in use on some systems and will only disappear when the systems disappear.
The HPC architecture in a complex consists of the elements shown in Figure 1. As stated before, both Folklore and UNIX are in use. About five or six years ago, NSA detached users from direct connection to supercomputers by giving the users a rich variety of support systems and more powerful workstations. Thus, HPC is characterized as a distributed system because of the amount of work that is carried out at the workstation level and on user-support systems, such as CONVEX Computer Corporation machines and others, and across robust networks into supercomputers.
NSA has had a long history of building special-purpose devices that can be viewed as massively parallel processors because most of them do
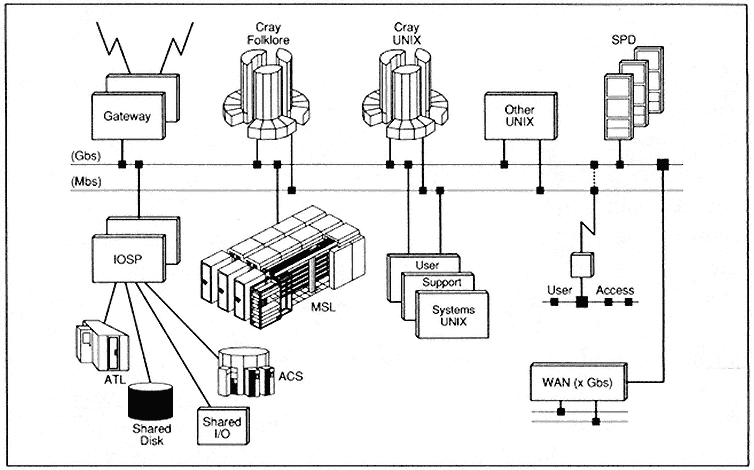
Figure 1.
NSA's HPC architecture in the 1990s.
very singular things on thousands of processors. Over the past few years, NSA has invested a great deal of effort to upgrade networking and storage capacity of the HPC complexes. At present, a major effort is under way to improve the mass-storage system supporting these complexes. Problems abound in network support. Progress has been slow in bringing new network technology into this environment because of the need to work with a large number of systems, with new protocols, and with new interfaces. A great deal of work remains to be done in this field.
Software Environment
IMP, Fortran, and C are the main languages used in HPC at NSA. Although a general Ada support function is running in the agency (in compliance with Department of Defense requirements to support Ada), HPC users are not enthusiastic about bringing up Ada compilers on these systems. NSA plans to eliminate IMP because it has little vectorizing capability, and the user has to deal with vectorizing.
Faster compilers are needed, particularly a parallelizing C compiler. HPC also requires full-screen editors, as well as interactive debuggers that allow partial debugging of software. Upgrading network support is a slow process because of the number of systems involved and new protocols and interfaces. Upgrading on-line documentation, likewise, has been slow. Software support lags three to five years behind the
introduction of new hardware technology, and we don't seem to be gaining ground.
Mass-Storage Requirements
A large number of automatic tape libraries, known as near-line (1012-bit) storage, have deteriorated and cannot be repaired much longer. Mass-storage systems must be updated to an acceptable level. Key items in the list of storage requirements are capacity, footprint, availability, and bit-error rate, and these cannot be overemphasized. In the implementation of new mass-storage systems, NSA has been driven by the need for standardization and by the use of commercial, supportable hardware, but the effort has not always been completely successful.
One terabyte of data can be stored in any one of the ways shown graphically in Figure 2. If stacked, the nine-track tape reels would reach a height 500 feet, almost as high as the Washington Monument. Clearly, the size and cost of storage on nine-track tapes is intolerable if large amounts of data are to be fed into users' hands or into their applications. Therefore, this type of storage is not a solution.
NSA is working toward an affordable mass-storage system, known as R1/R2, because the size is manageable and the media compact (see Figure 3). This goal should be achieved in the middle 1990s. Central to the system will be data management and a data-management system, database system, and storage manager for this kind of capability, all being considered as a server to a set of clients (Cray, CONVEX, Unisys). The mass-storage system also includes Storage Tek silos having capabilities approaching a terabyte in full 16-silo configuration. In addition, E-Systems is developing (funded by NSA) a very large system consisting of a D2 tape, eight-millimeter helical-scan technology, and 1.2 × 1015 bits in a box that has a relatively small footprint. Unfortunately, seconds to minutes are required for data transfer calls through this system to clients being served, but nevertheless the system represents a fairly robust near-line storage capacity.
Why is this kind of storage necessary? Because one HPC complex receives 40 megabits of data per second, 24 hours a day, seven days a week—so one of these systems would be full in two days. Why is the government paying for the development of the box? Why is industry not developing it so that NSA might purchase it? Because the storage technology industry is far from robust, sometimes close to bankruptcy.
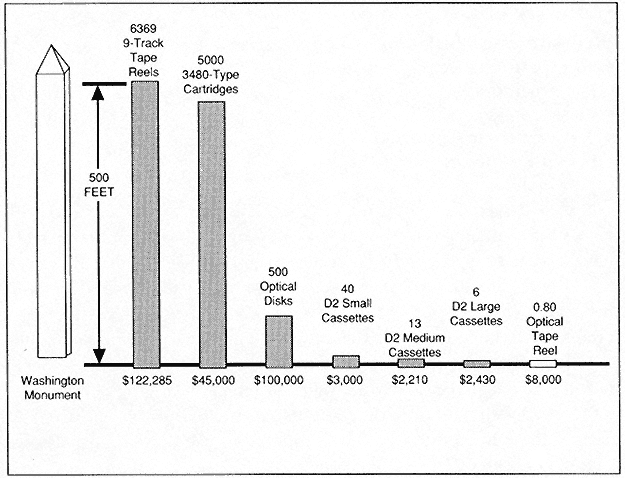
Figure 2.
Storage requirements for one terabyte of data, by medium.
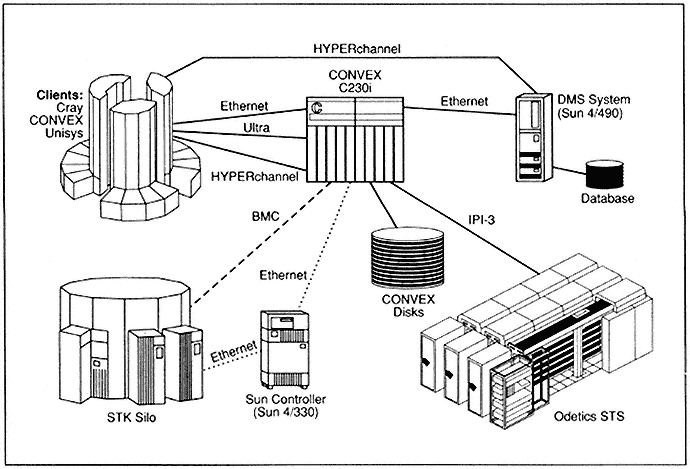
Figure 3.
Mass-storage system for R1/R2 architecture.
Summary of Issues
I have addressed the following important issues:
• cost/performance relationships;
• large memory;
• mass storage;
• software environments;
• network support; and
• new architecture.
NSA is driven by computing requirements that would demand a 40 per cent improvement each year in cost/performance if annual investment were to be held steady. Since we are far from getting that improvement—even though cost/performance has improved a great deal over the years—the complexes are growing. We have problems that are intractable today because sufficiently large memories are not available on the systems. Mass storage and software environments have been thoroughly discussed. Network support, which is lagging behind, has not worked well with the storage industry or with the HPC industry. A much tighter integration of developments in the networking area is necessary to satisfy the needs of NSA.
HPC facilities issues include space, power, and cooling. We are seriously considering building an environmentally stable building that will allow the import of 40 kilowatts of power to the systems. However, such outrageous numbers should drive the computer industry toward cooler systems, new technology, and into the direction of superconductivity.
The High Performance Computing Initiative:
A Way to Meet NASA's Supercomputing Requirements for Aerospace
Vic Peterson
Victor L. Peterson is Deputy Director of the National Aeronautics and Space Administration (NASA) Ames Research Center. He has a bachelor's degree in aeronautical engineering from Oregon State University, a master's degree in aeronautic and astronautic sciences from Stanford University, and a master's degree in management from the Alfred P. Sloan Fellow's Program at MIT. For over 15 years, he has directed programs to advance the use of supercomputers in various fields of science and engineering. He was one of the founders of NASA's Numerical Aerodynamic Simulation System Program.
Supercomputers are being used to solve a wide range of aerospace problems and to provide new scientific insights and physical understanding. They are, in fact, becoming indispensable in providing solutions to a variety of problems. In the engineering field, such problems include aerodynamics, aerothermodynamics, structures, propulsion systems, and controls. In the scientific field, supercomputers are tackling problems in turbulence physics, chemistry, atmospheric sciences, astrophysics, and human modeling. Examples of applications in the engineering field relate to the design of the next-generation high-speed civil transports, high-performance military aircraft, the National
Aerospace Plane, Aeroassisted Orbital Transfer vehicles, and a variety of problems related to enhancing the performance of the Space Shuttle. Example applications involving scientific inquiry include providing new insights into the physics and control of turbulence, determination of physical properties of gases, solids, and gas-solid interactions, evolution of planetary atmospheres—both with and without human intervention—evolution of the universe, and modeling of human functions such as vision.
Future computer requirements in terms of speed and memory have been estimated for most of the aerospace engineering and scientific fields in which supercomputers are widely used (Peterson 1989). For example, requirements for aircraft design studies in which the disciplines of aerodynamics, structures, propulsion, and controls are treated simultaneously for purposes of vehicle optimization can exceed 1015 floating-point operations per second and 1011 words of memory if computer runs are not to exceed about two hours (Figure 1). Of course, these requirements can be reduced if the complexity of the problem geometry and/or the level of physical modeling are reduced. These speed and memory requirements are not atypical of those needed in the other engineering and scientific fields (Peterson 1989).
Advancements in the computational sciences require more than more powerful computers (Figure 2). As the power of the supercomputer grows, so must the speed and capacity of scientific workstations and both fast-access online storage and slower-access archive storage. Network bandwidths must increase. Methods for numerically representing problem geometries and generating computational grids, as well as solution algorithms, must be improved. Finally, more scientists and engineers must be trained to meet the growing need stimulated by more capable computer systems.
The need for advancements in the computational sciences is not limited to the field of aerospace. Therefore, both the executive and legislative branches of the federal government have been promoting programs to accelerate the development and application of high-performance computing technologies to meet science and engineering requirements for continued U.S. leadership. The thrust in the executive branch is an outgrowth of studies leading to the federal High Performance Computing Initiative (HPCI) described in the September 8, 1989, report of the Office of Science and Technology Policy. The thrust in the legislative branch is summarized in draft legislation in both houses of Congress (S. 1067, S. 1976, and H. R. 3131, considered during the second session of
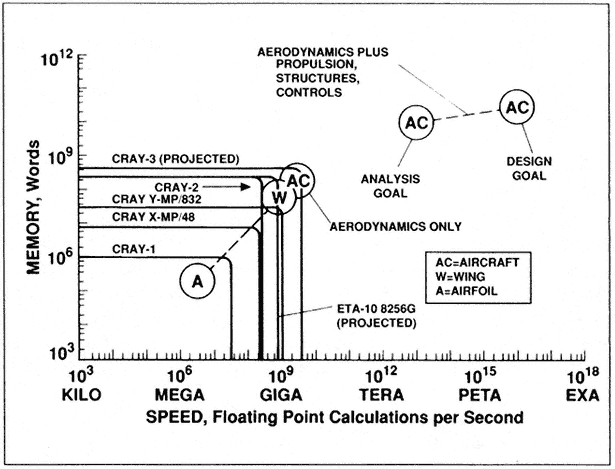
Figure 1.
Computer speed versus memory requirements (two-hour runs with 1988 methods; aerodynamics from Reynolds-averaged
Navier-Stokes equations).
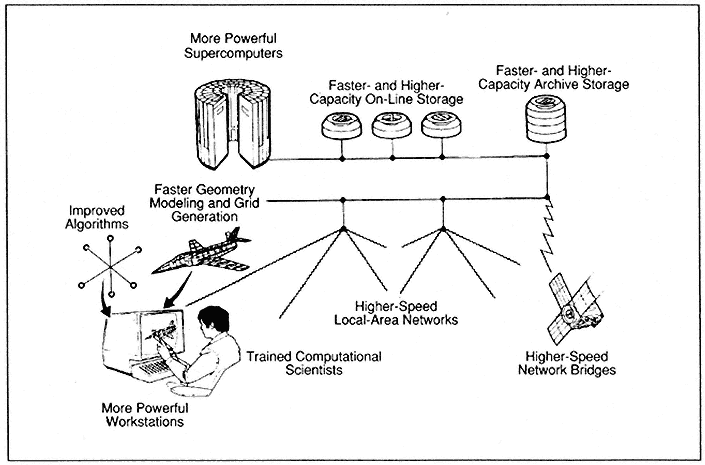
Figure 2.
Advancements in computational sciences require more powerful supercomputers.
the 101st Congress). Some differences between the executive and legislative programs currently exist, but both programs have similar goals, and they both identify the Defense Advanced Research Projects Agency (DARPA), the Department of Energy (DOE), NASA, and NSF as principal implementing agencies. Participating organizations include the Environmental Protection Agency, the National Institutes of Health (NIH), the National Institute of Standards and Technology, and the National Oceanic and Atmospheric Agency.
Roles of the four principal agencies, together with lead-agency designations, have been assigned in the executive-branch version of HPCI (Table 1). Four areas of activity have been defined as (1) high-performance computing systems (with DARPA as the lead agency); (2) advanced software technology and algorithms (NASA to lead); (3) the National Research and Education Network (DARPA to lead for network research, and NSF to lead for network deployment); and (4) basic
| |||||||||||||||||||||||||||||||||||
research and human resources (no lead agency). The participating organizations will undertake efforts to solve grand-challenge computational problems appropriate to their missions.
Objectives of NASA involvement in HPCI are threefold: (1) develop algorithm and architecture testbeds capable of fully utilizing massively parallel concepts and increasing end-to-end performance, (2) develop massively parallel architectures scalable to 1012 floating-point operations per second, and (3) demonstrate technologies on NASA research challenges.
NASA applications or grand-challenge problems will be undertaken in three distinct areas: (1) computational aerosciences, (2) earth and space sciences, and (3) remote exploration and experimentation. The Ames Research Center will lead in the computational-aerosciences area, and the problems will relate to integrated multidisciplinary simulations of aerospace vehicles throughout their mission profiles. The Goddard Spaceflight Center will lead in the earth-and space-sciences area, and the problems will relate to multidisciplinary modeling and monitoring of the earth and its global changes and assessments of their impact on the future environment. Finally, the Jet Propulsion Laboratory will lead in the remote-exploration and experimentation area, and the problems will relate to extended-duration human exploration missions and remote exploration and experimentation.
In summary, supercomputing has become integral with and necessary to advancements in many fields of science and engineering. Approaches to making further advancements are known, so the performance of supercomputing systems is pacing the rate of progress. Supercomputer performance requirements for making specific advancements have been estimated, and they range over seven or eight orders of magnitude in speed and two orders of magnitude in main-memory capacity beyond current capabilities. A major new thrust in high-performance computing is being planned to help meet these requirements and assure continued U.S. leadership in the computational sciences into the 21st century.
Reference
Victor L. Peterson, "Computational Challenges in Aerospace," Future Generation Computer Systems5 (2-3), 243-258 (1989).
The Role of Computing in National Defense Technology
Bob Selden
Bob Selden received his B.A. degree from Pomona College, Claremont, California, and his Ph.D. in physics from the University of Wisconsin, Madison.
He worked at Los Alamos National Laboratory from 1979 to 1988, then served as science advisor to the Air Force Chief of Staff and to the Secretary of the Air Force from 1988 to 1991. Subsequently, he returned to Los Alamos in his current position as an Associate Director for Laboratory Development. In this capacity, his principal responsibilities include providing the strategic interface with the Department of Defense.
Bob Selden has received both the Air Force Association's Theodore von Karman Award for outstanding contributions to defense science and technology and the Air Force Decoration for exceptional civilian service.
The focus of my presentation is on the use of computers and computational methods in the research and development of defense technology and on their subsequent use in the technology, itself. I approach this subject from a strategic standpoint.
Technology for defense is developed to provide the capabilities required to carry out tasks in support of our defense policy and strategy. Considering the broad scope of defense policy and strategy, and the capabilities needed to support them, makes the fundamental role of computers and computational methods self-evident.
Our national security policy can be simply stated as our commitment to protect our own freedom and our way of life and to protect those same things for our friends and allies around the world. National security strategy can be put into two broad categories. The first category is deterring nuclear war. The second is deterring or dissuading conventional war and, failing that, maintaining the capability to conduct those actions that are necessary at the time and place you need to conduct them.
These simply stated strategy objectives provide the basis for the defense forces that exist today. As we look into the future, the characteristics of the kinds of systems that the military has to have are forces that are mobile and have speed, flexibility, and a lot of lethality. You may have to attack tank armies in the desert and go in and shoot weapons at the enemy one at a time with an airplane, against an enemy that has sophisticated defenses, which can result in many losses of airplanes and pilots. You also need accuracy. For instance, suppose the U.S. has to go in and take out all of the facilities related only to chemical warfare. In that case, chemical storage sites and the means of delivering chemical weapons would have to be exactly targeted. To have the fundamental capability to do any of those things, we need systems that provide information, communications, and command and control, as well as the ability to make all the elements tie together so that we know where those elements are, when they are going to be there, how to organize our forces, and how to make the best use of those forces.
Now, let us look at the enabling technologies that allow such complexities of modern warfare to take place successfully. Many of the key enabling technologies depend on the exploitation of electronics and electromagnetics. In short, a major part of the ball game is the information revolution—computing, sensors, communication systems, and so forth, in which very, very dramatic changes are already under way and more dramatic changes are yet to come.
Supercomputing as a research methodology has not truly come of age inside the Department of Defense (DoD). As a whole, the DoD laboratories, as opposed to the national laboratories, also have not been involved with computing as a methodology. It is true that part of the problem is cost, as well as procurement regulations, etc. But the real issue is that there is not a supercomputing culture—a set of people like there is in many of the organizations we have heard from during this conference, to push for computing as a major methodology for doing R&D. Being able to recognize the significance of the broad supercomputing culture will result in a tremendous payoff in investments in large-scale computation as a part of the research process within DoD.
Despite these comments, we are seeing an absolutely unprecedented use of data processing, computing, and computing applications in military hardware, operations, simulations, and training. This is a revolution in the kinds of military equipment we use and in the way we train. It is also true that the number-one logistics problem for maintenance cited in military systems today is software.
Now I would like to discuss some of the impact and applications of computing in military systems and military operations. Computing is a fairly unique kind of technology in that it is both enabling and operational in end products. It is an enabling technology because you do research with computers, and it is an operational technology because you use it with real equipment in real time to do things in the analysis and management, as well as in the systems, themselves. Computing and computational methods are pervasive from the very beginning of the research, all the way to the end equipment.
In operations, real-time computing is an extremely challenging problem. For instance, to be able to solve a problem in a fighter airplane by doing the data processing from a complex electronic warning system and a synthetic-aperture radar, the computational data processing and analysis must be accomplished in near real time (perhaps seconds) and a display or other solutions presented to the pilots so that they will be able to make a decision and act on it. This complex interaction is one of the hardest computational problems around. In fact, it is every bit as challenging as any problem that is put on a Cray Research, Inc., computer at Los Alamos National Laboratory.
Another area of application is in the area of simulation, which includes training, simulation, and analysis. This is going to be an area that is just on the verge of exploding into the big time, partly because of the funding restrictions imposed on the use of real systems and partly because the training simulators, themselves, are so powerful. We already have cockpit simulators for pilots, tanks, training, war games, and so on. The National Testbed that the Strategic Defense Initiative is sponsoring in Colorado Springs is also an example of those kinds of large-scale computer simulations.
The world of computing has changed a great deal over the past decade. A look at Figure 1, the distribution of installed supercomputing capability in the U.S. in 1989, shows the leadership of defense-related organizations in supercomputing capabilities. It also shows a growing capability within DoD.
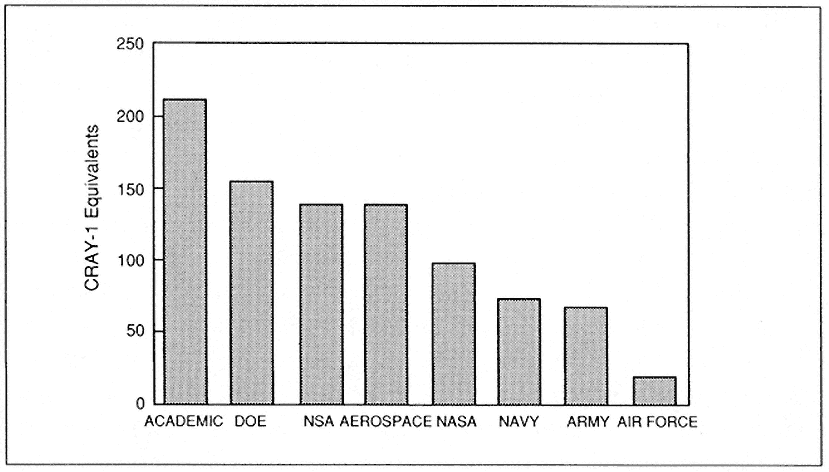
Figure 1.
Installed supercomputing capability in the U.S. in 1989. CYBER 205-class or above
(source: Cray Research, Inc.).
In conclusion, computing is coming of age in both the development and operation of defense technology. Future capabilities are going to rely even more on computation and computational methodology, and this will also be a time of planning, training, and analysis. Computing is a pervasive enabling technology.
NSF Supercomputing Program
Larry Smarr
Larry Smarr is currently a professor of physics and astronomy at the University of Illinois-Urbana/Champaign and since 1985 has also been the Director of the National Center for Supercomputing Applications.
He received his Ph.D. in physics from the University of Texas at Austin. After a postdoctoral appointment at Princeton University, Dr. Smarr was a Junior Fellow in the Harvard University Society of Fellows. His research has resulted in the publication of over 50 scientific papers.
Dr. Smarr was the 1990 recipient of the Franklin Institute's Delmer S. Fahrney Medal for Leadership in Science or Technology.
I attended the 1983 Frontiers of Supercomputing conference at Los Alamos National Laboratory, when the subject of university researchers regaining access to supercomputers—after a 15-year hiatus—was first broached. There was a lot of skepticism as to whether such access would be useful to the nation. That attitude was quite understandable at the time. The university community is the new kid on the block, so far as participants at this conference are concerned, and we were not substantially represented at the meeting in 1983.
Today, the attitude is quite different. Part of my presentation will be devoted to what has changed since 1983.
As you know, in 1985–86 the National Science Foundation (NSF) set up five supercomputing centers, one of which has since closed (see Al
Brenner's paper, Session 12). The four remaining centers are funded through 1995. Three of the four supercomputer center directors are attending this conference. Apart from myself, representing the National Center for Supercomputing Applications (NCSA) at the University of Illinois, there is Sid Karin from San Diego and Michael Levine from Pittsburgh, as well as the entire NSF hierarchy—Rich Hirsh, Mel Ciment, Tom Weber, and Chuck Brownstein, right up to the NSF Director, Erich Bloch (a Session 1 presenter).
During the period 1983–86, we started with no network. The need to get access to the supercomputer centers was the major thing that drove the establishment of the NSF network. The current rate of usage of that network is increasing at 25 per cent, compounded, per month. So it's a tremendous thing.
There were three universities that had supercomputers when the program started; there are now well over 20. So the capacity in universities has expanded by orders of magnitude during this brief period. During those five years, alone, we've been able to provide some 11,000 academic users, who are working on almost 5000 different projects, access to supercomputers, out of which some 4000 scientific papers have come. We've trained an enormous number of people, organized scientific symposia, and sponsored visiting scientists on a scale unimagined in 1983.
What I think is probably, in the end, most important for the country is that affiliates have grown up—universities, industries, and vendors—with these centers. In fact, there are some 46 industrial partners of the sort discussed extensively in Session 9, that is, the consumers of computers and communications services. Every major computer/communications-services vendor is also a working partner with the centers and, therefore, getting feedback about what we need in the future.
If I had to choose one aspect, one formerly pervasive attitude, that has changed, it's the politics of inclusion. Until the NSF centers were set up, I would say most supercomputer centers were operated by exclusion, that is, inside of laboratories that were fairly well closed. There was no access to them, except for, say, the Department of Energy Magnetic Energy Facility and the NSF National Center for Atmospheric Research. In contrast, the NSF centers' goal is to provide access to anyone in the country that has a good idea and the capability of trying it out.
Also, unlike almost all the other science entities in the country, instead of being focused on a particular science and engineering mission, we are open to all aspects of human knowledge. That's not just the natural
sciences. As you know, many exciting breakthroughs in computer art and music and in the social sciences have emerged from the NSF centers.
If you imagine supercomputer-center capacity represented by a pie chart (Figure 1), the NSF directorate serves up the biggest portion to the physical sciences. Perhaps three-quarters of our cycles are going to quantum science. I find it very interesting to recall being at Livermore in the 1970s, and it was all continuum field theory, fluid dynamics, and the like. So the whole notion of which kind of basic science these machines should be working on has flip-flopped in a decade, and that's a very profound change.
The centers distribute far more than cycles. They're becoming major research centers in computational science and engineering. We have our own internal researchers—world-class people in many specialties—that work with the scientific community, nationwide; some of the most important workshops in the field are being sponsored by the centers. You're also seeing us develop software tools that are specific to particular disciplines: chemistry, genome sequencing, and so forth. That will be a significant area of growth in the future.
There's no preexisting organizational structure in our way of doing science because the number of individuals who do computing in any field of science is still tiny. Their computational comrades are from biology,
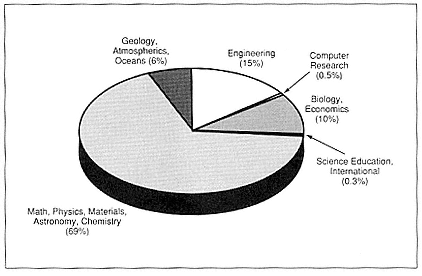
Figure 1.
Usage, by discipline, at NSF supercomputing centers.
chemistry, engineering—you name it—and there are no national meetings and no common structure that holds them together culturally. So the centers are becoming a major socializing force in this country.
What we are seeing, as the centers emerge from their first five-year period of existence and enter the next five-year period, is a move from more or less off-the-shelf, commercially available supercomputers to a very wide diversity of architectures. Gary Montry, in his paper (see Session 6), represents the divisions of parallel architecture as a branching tree. My guess is that you, the user, will have access to virtually every one of those little branches in one of the four centers during the next few years.
Now, with respect to the killer-micro issue (also discussed by Ben Barker in Session 12), in the four extant centers we have about 1000 workstations and personal computers, and at each center we have two or three supercomputers. Just like all of the other centers represented here, we at NCSA have focused heavily on the liberating and enabling aspect of the desktop. In fact, I would say that at the NSF centers from the beginning, the focus has been on getting the best desktop machine in the hands of the user and getting the best network in place—which in turn drives more and more use of supercomputers. If you don't have a good desktop machine, you can't expect to do supercomputing in this day and age. So workstations and supercomputers form much more of a symbiosis than a conflict. Furthermore, virtually every major workstation manufacturer has a close relationship with one or more of the centers.
The software tools that are developed at our centers in collaboration with scientists and then released into the public domain are now being used by over 100,000 researchers in this country, on their desktops. Of those, maybe 4000 use the supercomputer centers. So we have at least a 25-to-one ratio of people that we've served on the desktop, compared with the ones that we've served on the supercomputers, and I think that's very important. The Defense Advanced Research Projects Agency has, as you may know, entered into a partnership with NSF to help get some of these alternate architectures into the centers. In the future, you're going to see a lot of growth as a result of this partnership.
The total number of CRAY X-MP-equivalent processor hours that people used at all five centers (Figure 2) has steadily increased, and there is no sign of that trend tapering off. What I think is more interesting is the number of users who actually sign on in a given month and do something on the machines (Figure 3). There is sustained growth, apart from a period in late 1988, when the capacity didn't grow very fast and the machines became saturated, discouraging some of the users. That was a very clear warning to us: once you tell the scientific community that
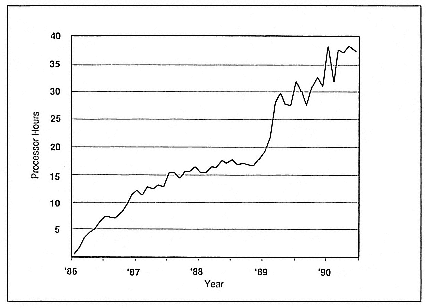
Figure 2.
Total CRAY X-MP-equivalent processor hours used in five NSF supercomputing
centers.
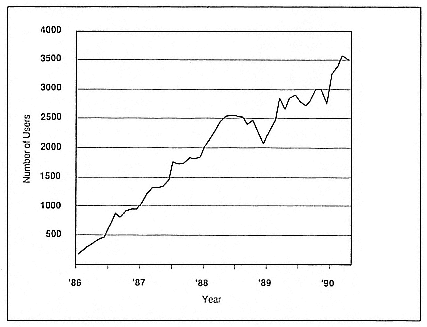
Figure 3.
Number of active users at five NSF supercomputer centers.
you're going to provide a new and essential tool, you've made a pact. You have to continue upgrading on a regular, and rapid, basis, else the user will become disenchanted and do some other sort of science that doesn't require supercomputers. We think that this growth will extend well into the future.
I am especially excited about the fact that users, in many cases, are for the first time getting access to advanced computers and that the number of first-time users grew during the time that desktops became populated with ever-more-powerful computers. Instead of seeing the demand curve dip, you're seeing it rise even more sharply. Increasingly, you will see that the postprocessing, the code development, etc., will take place at the workstation, with clients then throwing their codes across the network for the large uses when needed.
Who, in fact, uses these centers? A few of our accounts range upwards of 5000 CPU hours per year, but 95 per cent of our clients consume less than 100 hours per year (Figure 4). The implication is that much of the work being done at the centers could be done on desktop machines. Yet, these small users go to the trouble to write a proposal, go through peer review, experience uncertainty over periods of weeks to months as to whether and when they'll actually get on the supercomputer, and then have to go through what in many cases is only a 9600-Baud connect by the time we get down to the end of the regional net.
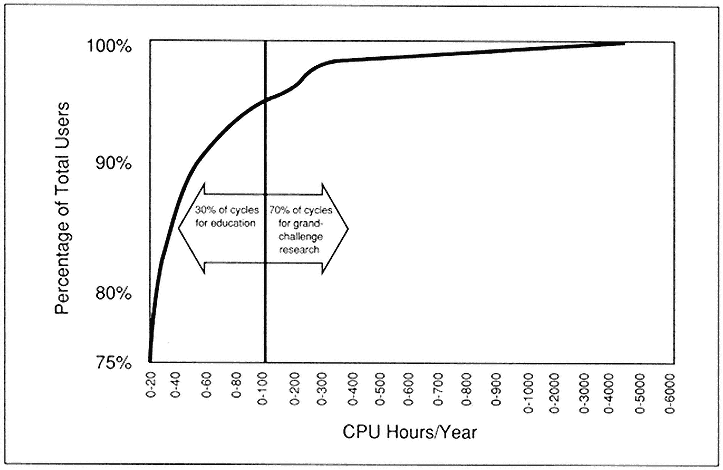
Figure 4.
Percentage of total users versus annual CPU-hour consumption, January FY 1988 through April FY 1990: 95 per cent of all users consume
less than 100 CPU hours per year.
It's like salmon swimming upstream: you can't hold them back. We turn down probably 50 per cent of the people who want to get on the machine, for lack of capacity.
What has happened here is that the national centers perform two very different functions. First, a great many of the users, 95 per cent of them, are being educated in computational science and engineering, and they are using their workstations simultaneously with the supercomputers. In fact, day to day, they're probably spending 90 per cent of their working hours on their desktop machines. Second, because of the software our centers have developed, the Crays, the Connection Machines, the Intel Hypercubes are just windows on their workstations. That's where they are, that's how they feel.
You live on your workstation. The most important computer to you is the one at your fingertips. And the point is, with the network, and with modern windowing software, everything else in the country is on your desktop. It cuts and pastes right into the other windows, into a word processor for your electronic notebook.
For instance, at our center, what's really amazing to me is that roughly 20 per cent of our users on a monthly basis are enrolled in courses offered by dozens of universities—courses requiring the student to have access to a supercomputer through a desktop Mac. That percentage has gone up from zero in the last few years.
These and the other small users, representing 95 per cent of our clients, consume only 30 per cent of the cycles. So 70 per cent of the cycles, the vast majority of the cycles, are left for a very few clients who are attacking the grand-challenge problems.
I think this pattern will persist for a long time, except that the middle will drop out. Those users who figure it out, who know what software they want to do, will simply work on their RISC workstations. That will constitute a very big area of growth. And that's wonderful. We've done our job. We got them started.
You can't get an NSF grant for a $50,000 workstation unless you've got a reputation. You can't get a reputation unless you can get started. What the country lacked before and what it has now is a leveraging tool. Increasing the human-resource pool in our universities by two orders of magnitude is what the NSF centers have accomplished.
But let me return to what I think is the central issue. We've heard great success stories about advances in supercomputing from every agency, laboratory, and industry—but they're islands. There is no United States of Computational Science and Engineering. There are still umpteen colonies or city-states. The network gives us the physical wherewithal to
change that. However, things won't change by themselves. Change requires political will and social organization. The NSF centers are becoming a credible model for the kind of integration that's needed because, just in terms of the dollars, alone (not the equipment-in-kind and everything else—just real, fundable dollars), this is the way the pie looks in, say, fiscal year 1989 (FY 1989) (Figure 5).
There is a great deal of cost sharing among each of the key sectors—the state, the regional areas, the consumers of the computers, the producers. NSF is becoming the catalyst pulling these components together. Next, we need to do something similar, agency to agency. The High Performance Computing Initiative (HPCI) is radical because it is a prearranged, multiagency, cooperative approach. The country has never seen that happen before. Global Change is the only thing that comes close. But that program hasn't had the benefit of a decade of detailed planning the way HPCI has. It's probably the first time our country has tried anything like it.
I would like to hear suggestions on how we might mobilize the people attending this conference—the leaders in all these islands—and, using the political and financial framework afforded by HPCI over the rest of this decade, change our way of doing business. That's our challenge. If we can meet that challenge, we won't need to worry about competitiveness in any form. Americans prevail when they work together. What we are not good at is making that happen spontaneously.
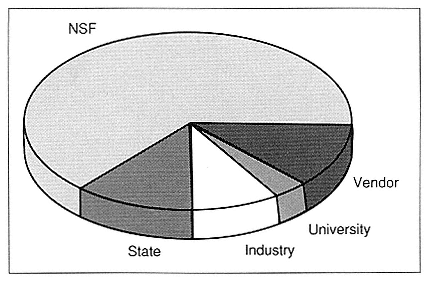
Figure 5.
Supercomputer-center cost sharing, FY 1989.